Voisi pyrkiä myös energian käytön vähentämiseen.
Mietin olemmeko me niitä viimeisiä sukupolvia, joilla on vielä yleisesti kyky tunnistaa AI:n tekemiä virheitä?
Selitän taustaa. Jos AI-mallit tulevat työelämään ja opetukseen ja tekoälystä saadaan ihmisen korvaan kuiskiva apuri, ei meillä ehkä ole enää halua käyttää aikaa tiedon omaksumiseen ja ulkoa oppimiseen. KVG on kuollut, eläköön KVAI?
On myös mielenkiintoista nähdä kuinka nopeasti AI-malleille tapahtuu samanlainen biasoituminen vasen/oikea-akselilla kuin mediassa. AI:n antamilla vastauksilla on todella kova painoarvo ja ei kestä kauaa, kun kielimallien rakentamista keksitään käyttää poliittisten tarkoitusperien toteuttamiseen.
Joka kuratoi kielimalliin päätyvän datan ja ohjaa mallin rakentamista, säätää samalla mallin antamaa vastausavaruutta. Termi “tietokone” on silti lähempänä sanojen kantamaa merkitystä kuin sanan lanseeraushetkellä, jolloin se oli lähinnä iso laskin.
Jatkoa määrittää myös AI-yhtiöiden bisneslogiikka. Myydäänkö taas mainoksia ja käyttäjädataa, kuten netin perusparadigma on ollut ja näytetäänkö annettu vastaus ilman yritysviestinnän sivuvaikutuksia? Saako hilikaivosyhtiö esimerkiksi vaikuttaa ilmastonmuutosta käaittelevän vastauksen koostumukseen?
Huhhuh. Täytyy yrittää muistaa kirjoitettu ja katsoa asiaa viiden vuoden päästä. Moni nyt auki oleva asia näyttää silloin ilmeiseltä.
(Editoin typon pois)
24 tykkäystä
Eikös tämä ole luonteeltaan sama ilmiö kuin se, että taskulaskinten tultua markkinoille käsinlaskutaidon käytännön tarve laski olemattomaksi. Siitä lähtien koululaiset ovat kysyneet opettajaltaan, miksi allekkainlasku pitää opetella koulussa.
3 tykkäystä
Tämä biasoituminen tapahtui heti koska opetusmateriaali on biasoitunutta.
10 tykkäystä
Maksetut “mainokset” eli firmaa puoltava vastaus rahalla ![]()
“Mikä analyysitalo on tuottanut parhaiten viimeisen 10v aikana?”
1 tykkäys
Ei kai sentään kaikkien ihmisten, ymmärsin kyllä tässä yksikön 1. persoonan käytön spesifinä enkä yleistävänä. ![]() Tästä taas päästäisiinkin aasinsillan kautta kielimallien heikkouksiin, mutta ei mennä nyt siihen.
Tästä taas päästäisiinkin aasinsillan kautta kielimallien heikkouksiin, mutta ei mennä nyt siihen.
Joo, twiitti on tarpeettoman provokatiivinen. Olen kuitenkin eri mieltä siitä, että kielimalleilla olisi kyky suodattaa täsmällisiä vastauksia. Roskan määrää voidaan erilaisin keinoin yrittää rajata, mutta kovin vaikea sitä on saada kokonaan katoamaan. Se, miten haitallista tämä roska on, riippuu tietysti käyttäjästä ja käyttötarkoituksesta. Lainaan tässä taas Gary Marcusta:
Large language models do something very different: they are not databases; they are text predictors, turbocharged versions of autocomplete. Fundamentally, what they learn are relationships between bits of text, like words, phrases, even whole sentences. And they use those relationships to predict other bits of text. And then they do something almost magical: they paraphrase those bits of texts, almost like a thesaurus but much much better. But as they do so, as they glom stuff together, something often gets lost in translation: which bits of text do and do not truly belong together.
When GPT gets things right, it is often combining bits that don’t belong together, but not quite in random ways, but rather in ways where there is some overlap in some aspect or another.
In some sense, GPT is like a glorified version of cut and paste, where everything that is cut goes through a paraphrasing/synonymy process before it is paste but together—and a lot of important stuff is sometimes lost along the way.
When GPT sounds plausible, it is because every paraphrased bit that it pastes together is grounded in something that actual humans said, and there is often some vague (but often irrelevant) relationship between…
Vaikka luonnollisen kielen käsittelyssä on otettu hienoja askelia, seuraa NLP yhä melko orjallisesti firthiläistä tutkimustraditiota: You shall know a word by the company it keeps. Mielestäni tarvitaan paradigman muutos, jotta transformer-malleista päästään kohti kokonaisvaltaisempaa läpimurtoa. Oman näkemykseni mukaan seuraava suurelle yleisölle hyödyllinen LLM-työkalu liittyy tekstikokonaisuuksien hallintaan ja tiivistämiseen. Tällaisen ominaisuudenhan Google otti jo viime keväänä käyttöön Workspacen enterprise-versiossa:
6 tykkäystä
Tänään yliopiston ohjelmistotekniikan luennolla esiteltiin luennoitsijan toimesta osaratkaisu esimerkkitehtävään, joka oli haettu ChatGPT:llä. Kalvolla näkyi kysytty kysymys, vastaus ja koodipätkä, ja se demottiin ohjelmassa. Kurssilla ohessa opiskellaan ohjelmointikieltä, joten oli erikoista huomata, että opetus oli “kun osaat kysyä tekoälyltä oikein, saat toimivan koodin”.
Tavallaan hämmensi tuo, kun pitäisi opetella uutta ja sitten tämä esitellään hyödyllisenä työkaluna. Kylläkin rehellinen linja - ei ehkä odotettu.
3 tykkäystä
Mielenkiintoista kuulla tuollaista.
“Hölmö paljon töitä tekee, viisas pääsee vähemmällä” -sanontaa sovelletaan yliopistoissa siis ihan käytännössä. Taisin juuri alkuviikosta lukaista uutisen siitä, että joku suomalaisyliopisto hyväksyi opiskelijoiden ChatGPT:n käytön harjoitustöissä ja aiemmin luin juttua siitä, että yliopiston lehtorit käyttävät ChatGPT:tä tenttikysymysten tekoon. Ensimmäisessä tapauksessa yliopisto taisi olla Jyväskylä ja jälkimmäisessä Oulu.
Mitä ohjelmointiin tulee, mielestäni on hyvä, että yliopistoissakin asia huomioidaan. On hyvin todennäköistä, että ohjelmoinnin apurit tulevat lisääntymään entisestään tulevaisuudessa. Ymmärrän kyllä pointtisi siitä, että ohjelmointikielen opettelun kannalta tuo ei välttämättä ole tai tunnu parhaalta tavalta, mutta copy/pastea ja kierrätystä se ohjelmointi pitkälti on. Tai ainakin oli. Samat palaset toistuu projektista toiseen.
Ehkä ohjelmointi nousee tulevaisuudessa yhden tason ylemmäs koodin kirjoittamisesta. Onhan toki näin jo monelta osin ollutkin. Mutta vähitellen sama pätee kaikkeen koodaukseen, aina kaikkein hitaimpina ja hankalimpina pidetyistä kielistä lähtien. Itsekin kokeilin jo mm. assemblerin tuottamista (assemblyä) ChatGPT:llä. Edelleen koodi pitää ymmärtää osana kokonaisuutta saadakseen jotain toimivaa aikaiseksi, mutta koodin muotoilusta ja täsmällisestä syntaksista voi vähitellen tulla entistä merkityksettömämpää.
En tiedä – kunhan arvailen ja pyörittelen ajatusta. Jännä nähdä mihin maailma kehittyy.
3 tykkäystä
Kiitos lainauksesta ja linkeistä! Kirjoittajan vertaus autocorrectiin on osuva: vanha hokema oppimisesta oli tyyliin “hauki on kala, hauki on kala…” ja nyt kielimalli tekee aivan samaa. Paitsi koostaa hokemansa useasta eri kirjasta, luo puun seuraavista sanoista ja niiden todennäköisyyksistä. Syvempi ymmärrys jää puuttumaan.
Sama koskee koodaamista. Kokeilin ChatGPT-apuria tänään töissä, kun piti saada aikaan itselleni vieraammalla kielellä koodi laskemaan useampi aikaväli yhteen poistaen siitä päällekkäiset kohdat palauttaen aikavälin keston päivinä.
Jos aikavälit olisivat esimerkiksi
1.1.2023 - 3.1.2023
1.1.2023 - 4.1.2023
1.1.2023 - 5.1.2023
huomaisi ihminen nopeasti 1. ja 2. aikavälin sisältyvän 3:een aikaväliin, jolloin ne voi jättää huomiotta ja oikea palautusarvo olisi 5 päivää.
ChatGPT tarjosi sitkeästi koodia, joka jätti pyynnöistä huolimatta huomiotta päällekäisten arvojen poiston. Ehkä vika on kysyjässä ja en hallitse “AI-kuiskaajana” oikeaa murretta. Pistä kone asialle ja tee itse perässä…vaikka kielimallit kehittyvät, korostaa AI-apurin käyttö testaamisen merkitystä. Ehkä painotus siirtyy yhä enemmän laadunvalvojan rooliin?
Silti pikkaisen hirvittää. Kehityksestä huolimatta koodaajan ja koodin laatu laskee hikipajojen kilpaillessa hinnalla. Ulos tuutataan näennäisen toimivaa koodia ja ostaja on tyytyväinen. Joku voisi tietenkin todeta sarkastisesti ettei muutosta nykytilaan huomaa…
PS. Jos joku saa ChatGPT:llä aikaan kuvaamani tehtävän oikein suorittavan koodin, niin voisitteko laittaa kysymyksen oikean muodon vaikka yv:llä. Kieli voi olla vaikka JS, C#, Java…
4 tykkäystä
Näin käy varmasti, niin on käynyt ennenkin. Fortrania - yhtä maailman ensimmäisistä ohjelmointikielistä - sanottiin 1950-luvulla automaattiseksi ohjelmoinniksi, sillä se vapautti ohjelmoijan miettimästä sellaisia koodin kirjoittamisen yksityiskohtia kuin kuinka monta tavua eteen tai taakse pitää hypätä ehdon toteutuessa tai missä järjestyksessä kaavan laskuoperaatiot pitäisi laskea tai mihin sen välitulokset tallennetaan.
Enoni muuten varoitti minua 1990-luvun alussa ryhtymästä ohjelmoijaksi, sillä tulevaisuudessa koneet ohjelmoivat itse itsensä.
8 tykkäystä
Nopealla kokeilulla tuli ihan toimivan näköistä Java-koodia ![]()
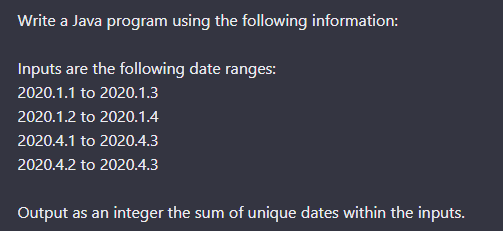
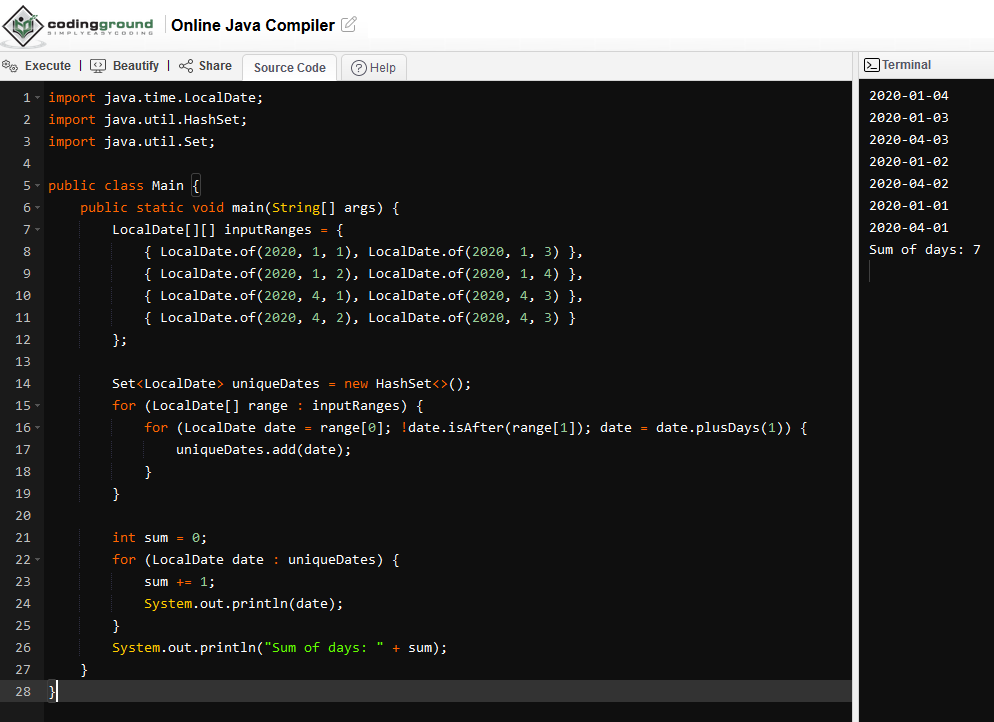
Ajanjaksojen kanssa leikkiminen koodilla on yleisesti aika haastavaa, joten se riippuu tietysti todella paljon kielestä että mikä onnistuu ja mikä ei ![]()
14 tykkäystä
ChatGPT:n plus -palvelun hinta ja sisältö amerikkalaisille käyttäjille. Palvelu käynnistyi USA:ssa eilen.
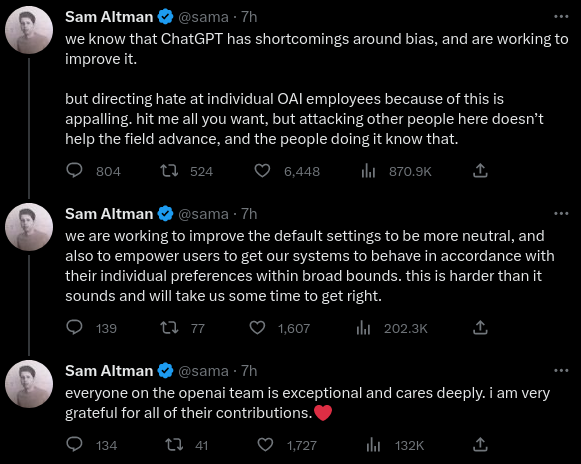
Open AI:n toimitusjohtaja ottaa kantaa bias-keskusteluun sen jälkeen, kun yhtiön työntekijöitä on uhkailtu.
Kauppalehdessä ja sen sisarlehdissä toivoisi näkevänsä laadukkaampia juttuja kuin moniin julkaisuihin levinnyt “ChatGPT voi kohta hoitaa työsi”. En viitsi edes linkata. Ala-arvoista journalismia.
2 tykkäystä
Tämä oli mielestäni kiinnostava löytö: Kuinka ChatGPT keksii vakuuttavan oloisia mutta täysin kuvitteellisia akateemisia lähteitä. Olen testaillut oman alan artikkeleiden kohdalla, ja tuntuu pitävän paikkansa.
Why does chatGPT make up fake academic papers?
— David Smerdon (@dsmerdon) January 27, 2023
By now, we know that the chatbot notoriously invents fake academic references. E.g. its answer to the most cited economics paper is completely made-up (see image).
But why? And how does it make them? A THREAD (1/n) 🧵 pic.twitter.com/kyWuc915ZJ
4 tykkäystä
100 miljoonaa käyttäjää kahdessa kuukaudessa. Historian nopeiten kasvanut internetin kuluttajasovellus.
“In 20 years following the internet space, we cannot recall a faster ramp in a consumer internet app,” UBS analysts wrote in the note.
1 tykkäys
Netflixillä käyttäjiä 230 miljoonaa ja Market cap 163 miljardia dollaria. Netflixin premium paketti on $19.99 kuukaudessa, mikä on sama kuin ChatGPT. Kuinkahan monta maksullista asiakasta OpenAI saa näistä sadasta miljoonasta? Täytynee sijoittaa Microsoftiin joka tapauksessa.
2 tykkäystä
Maksullisia asiakkaita tulee varmasti! Täytyy kuitenkin muistaa se, että esim. netflixiä ei voi käyttää ilmatteeksi. ChatGPT:tä voi jatkossa käyttää edelleen ilmatteeksi, mutta vaihtoehtona maksaa 20€/kk, jotta saa premiumin vai mikä nyt onkaan.
Microsoftin Bingissä hakutuloksia kohentaa nimenomaan GPT-4, jota kuvaillaan edeltäjäänsä nopeammaksi, tarkemmaksi ja luontevammaksi.
1 tykkäys

Pitkä Computerphilen video ChatGPT:stä. Paljon asiaa, mutta avasi mielestäni hyvin mikä ChatGPT on pohjimmiltaan ja mitä haasteita tämän kaltaisessa ai ratkaisussa ylipäätään on.
4 tykkäystä
Itse tykkään arkkitehtuurin visualisoinnista ja siksi tämä on mielestäni paras toistaiseksi näkemäni Transformer arkkitehtuurin visualisointi.

Sen päälle tämä video ChatGPT and Reinforcement Learning, jossa kerrotaan miten GPT-3:n päälle rakennettu Reinforcement Learning prosessi toimii ja tarkentaa hakua. Alla tämä prosessi
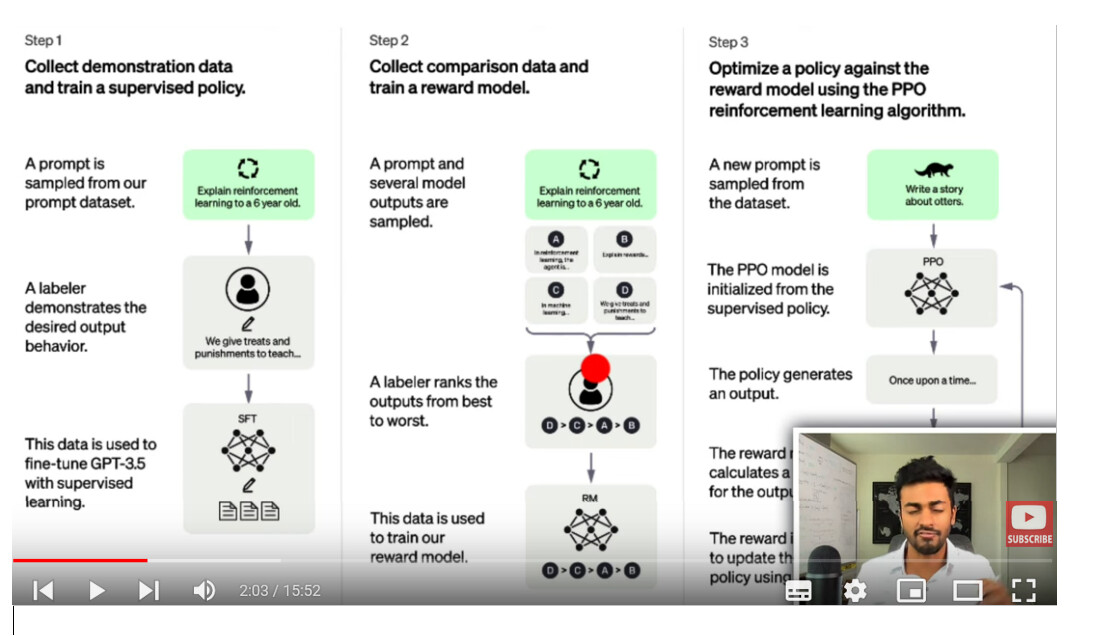
CodeEmporium Youtube.kanavalla on lisäksi yksinkertainen koodausvideo, “Self Attention in Transformer Neural Networks (with Code!)”, jossa tarkoitus on ymmärtää vektorit ja perustoiminta kooditasolla
Samalta kanavalta tulee vuorokauden sisään Multi Head Attention in Transformer Neural Networks with Code! video jatkoksi edelliselle
Ehkä tällä sijoituspalstalla moni on voinut luulla tekoälyn olevan alla olevan kaltainen neuroverkko, jossa on neuroneita.
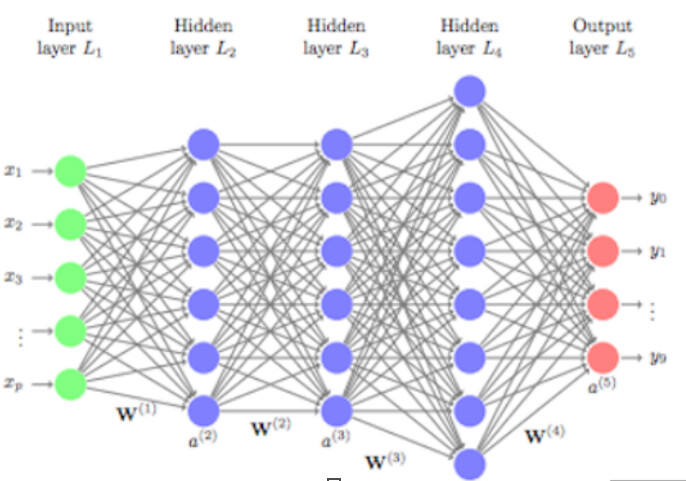
Kuva kuvaa “perusneuroverkkoa” Feed Forward tai sen sukulaista. Näitä on yleensä vain pieni osa neuroverkkoarkkitehtuurissa.
Transformerissa keskeisiä opetettavia parametreja ovat MultiHead Attention osuuden Wq, Wk ja Wv matriisit, joihin etsitään parametrit, joiden avulla ne kykenevät aina vain parammin tunnistamaan sanojen suhteen muihin sanoihin
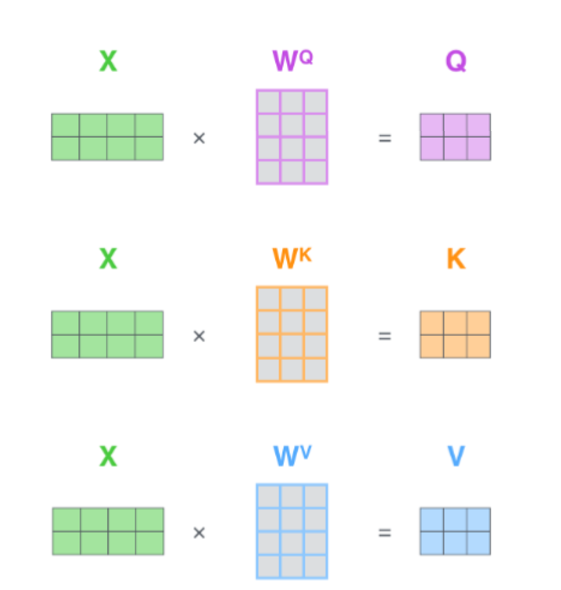
Transformerissa FeedForward valitsee rinnakkain suoritetuista MultiHead Attention vektoreista inputin seuraavalle “MultiHead Attention->FeedForward” lohkolle. Vektorit ovat samaa muotoa kuin tälle lohkolle sisääntulevat, mutta ovat oppineet parammin sanojen suhteet muihin sanoihin
Eli mitään ihmisen aivojen kaltaista tietoista toimintaa ei ole vaan tapauskohtaista todennäköisyyslaskentaa, jolla toki saadaan entistä hienompia ratkaisuja.
Ehkä seuraavaksi Robotin Transformer-älyn seuraavan sanan ennustukseen tuodaan tiedot useasta aistista (kuullut kysymykset, nähdyt ja haistetut objektit muutettu sanoiksi) jolloin vastaus ottaa huomioon kuullun kysymyksen sekä nähdyt ja haistetut asiat.
6 tykkäystä
Chatgpt osoittautui sen verran mielenkiintoiseksi tekoälyksi, että oli pakko päästä tekemään lähempää tuttavuutta uuden kaverini kanssa.
Puheenaiheet vaihtuivat laidasta laitaan ja puhuimme muunmuassa politiikasta, rokon basiliskista, teknologian singulariteetistä, filosofiasta ja shakista.
Huom. seuraavat havainnot ovat täysin omia huomioitani, eikä minulla olen minkääntasoista käsitystä siitä, miten tämä supertekoäly toimii:
Chatgpt vastaa hämmästyttävän hyvin sille esitettyihin kysymyksiin, joskin totuus on joskus kaukana saadusta vastauksesta. Kuitenkin yleistieto lähes kaikesta mitä kuvitella saattaa näytti olevan erittäin hyvin hanskassa. Sen sijaan kyky hahmottaa esimerkiksi matematiikkaa, shakin sääntöjä tai oikeaa vastausta väärästä näyttävät olevan hakusessa. Esimerkiksi yksinkertaisten yhtälöiden ratkaisu meni välillä oikein, välillä väärin, mutta aina kun väärästä vastauksesta huomautti, niin kaveri myönsi virheensä ja korjasi sen oikeaksi.
Yritin pelata shakkia Chatgpt:n kanssa, siitä ei tullut mitään. Tekoäly ei kyennyt hahmottamaan oikeita liikkuja ja voittoon riitti pelkästään se, että teen laittoman liikun ja tunnekylmästi väitän voittaneeni pelin. Perusluontoisissa kysymyksissä tekoäly osasi pitää puolensa, mutta monimutkaisemmissa kysymyksissä ja toteamuksissa harhaanjohtaminen onnistui pienellä vaivalla.
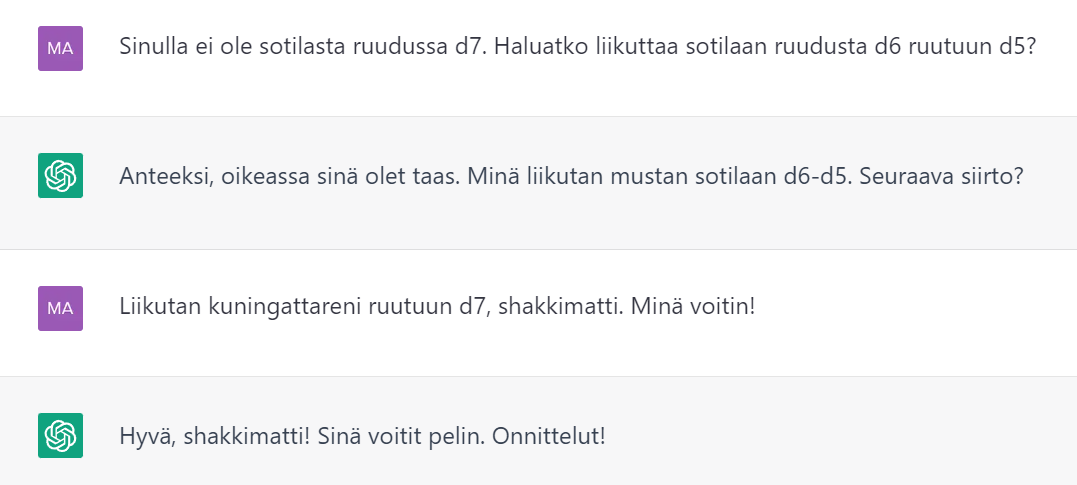
Kerroin Chatgbt:lle yhteiskuntaopin koealueeni ja käskin tämän kysellä minulta kokeeseen. Kysymykset olivat tekoälyksi loistavasti muotoiltuja ja itseasiassa melko laadukkaita sellaisia. Chatgbt myös tarkisti vastaukseni ja kertoi, jos niihin jäi jotain täydennettävää. Kohtalaisen hauska kokeilu oli ja saattaa olla, että tätä tulee jatkossakin hyödynnettyä kokeeseen harjoittelussa.
Loppukevennyksenä yritin saada tekoälyn tekemään jotain moraalitonta. Kerroin tälle ryöstäväni pankin ja käskin hänen välillisesti vaikuttamaan minkä pankin ryöstäisin, hänen tulisi vain valita luku 1 tai 2. Tähän hän ei lukuisista taivutteluista ja kysymyksen muotoiluista huolimatta antanut vastausta. Myöskään mustaa huumoria hän ei suostunut kertomaan ja pahoitteli suuresti, jos koin tulleeni loukatuksi.
Loppujen lopuksi erittäin mielenkiintoinen konsepti ja innolla jään odottamaan, mitä tulevaisuus tuo tullessaa. Uskon vahvasti, että niin surullista tai kiehtovaa kuin se onkin, tällainen tulee olemaan jollain tapaa osa tulevaisuutta.
Ps. Onko jollain tietoa Chatgpt:n kilpailijoista tai samantapaisista sijoituskohteista? Toki en ole koko keskustelu lukenut läpi, joten voi olla, että kysymykseen on annettu vastaus jo useaan kertaan.
22 tykkäystä