Löytyi tällainen API-only broker, joka hyväksyy myös eurooppalaisia käyttäjiä. API näyttää melko yksinkertaiselta Python, paper-trading mahdollista.
Vain US-osakkeita tosin.
2 tykkäystä
Puolivuotta sitten ennusteet näytti ylläolevilta ja näytti data olevan edelleen tallessa. Alla olevaan taulukkoon on laskettu toteutuneet tuotot ja erotus. Ennustetarkkuus vaikuttaa silmämääräisesti aika hyvältä. Keskimääräinen ennustevirhe oli 6,5%. Toteutuneet tuotot oli keskimäärin 4,1% heikommat kuin ennustettu.
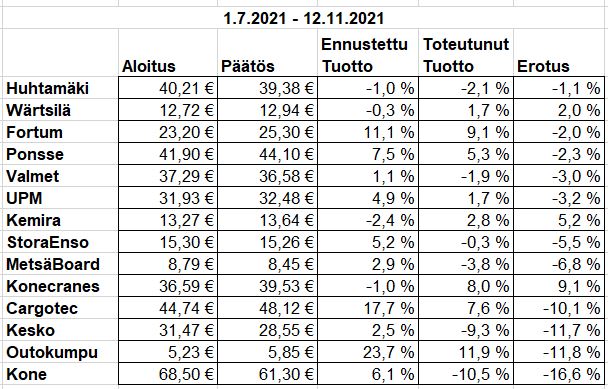
Erilaiset sijoitusstrategiat suoriutuivat yllättävän samankaltaisesti. Data on kerätty aina kuukauden lopussa, joilloin tuotot ei ole ollut tiedossa. Tasahajautus merkitty alla olevaa kuvaan punaisella ja parhaan tuotto-riski-suhteen simuloinneissa antava strategia vihreällä. Jälkimmäinen ollut suurimmaksi osaksi käytössä.
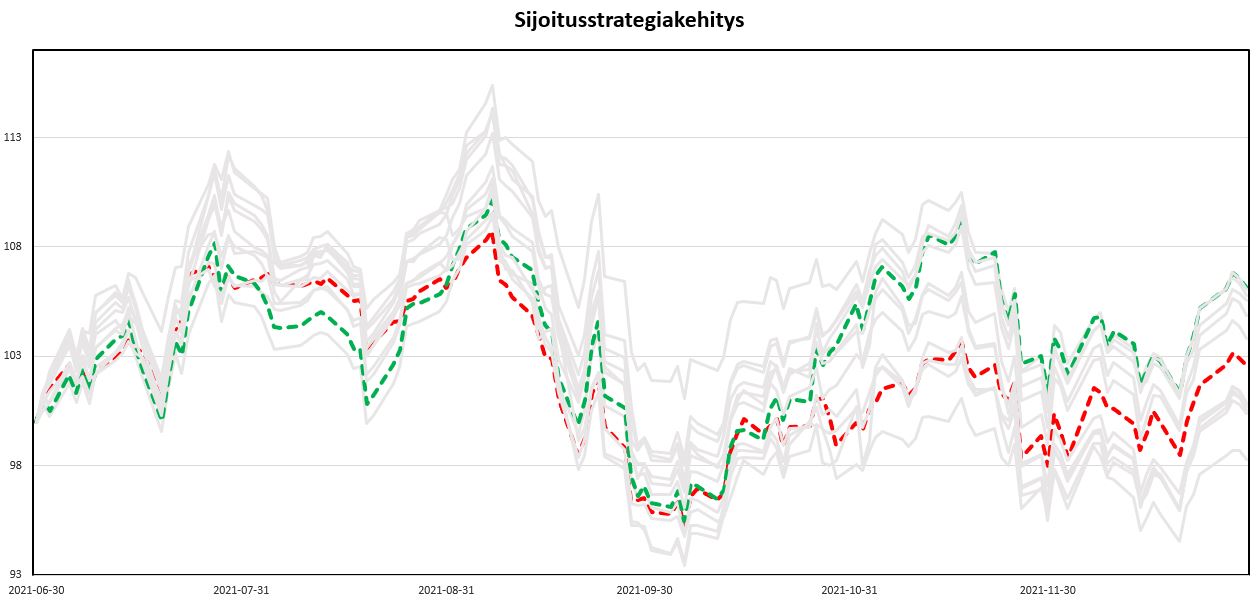
Päivittäin kerätty data hieman eroaa edellä olevasta kun strategia on vaihdellut. Mustilla viivoilla on hahmoteltu millaista tuottoa valitulla strategialla pitäisi keskimäärin odottaa simuloinnin perusteella.
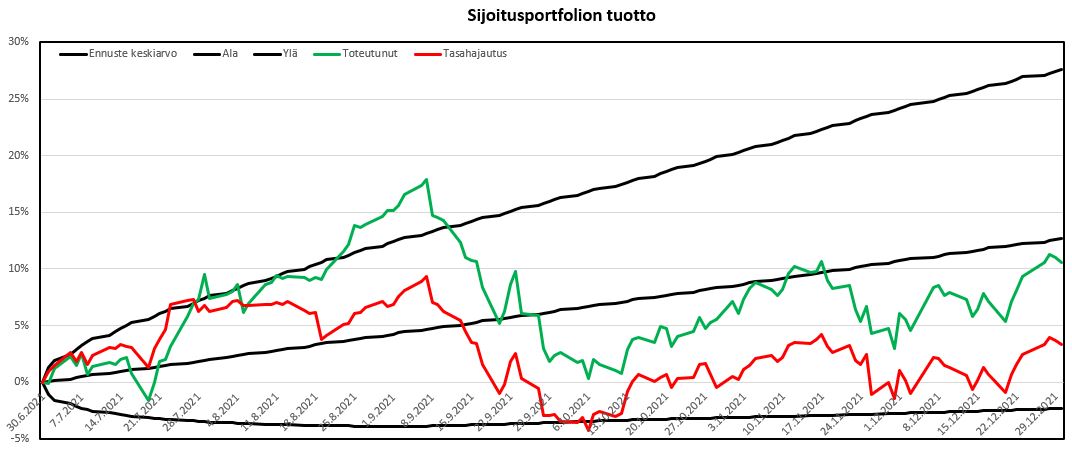
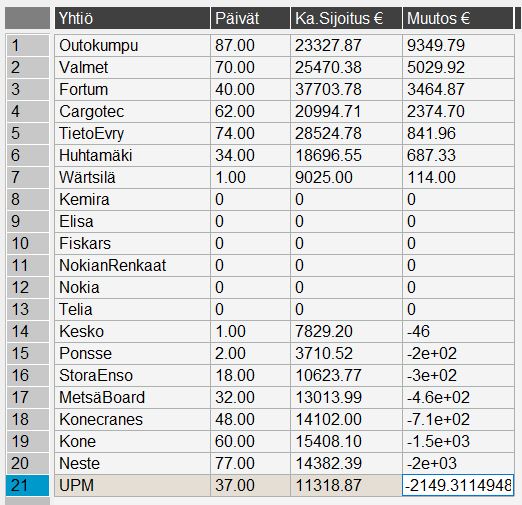
Matkan varrella sijoituksia on veivattu edes takaisin. Alla on laskettu sijoituspäivien lukumäärä, keskimääräinen sijoitus ja tuotto. Päiviä yhteensä aikajaksolla oli n. 130.
Kokonaisuudessaa alkaa tuntumaan, että tässä on ihan järkeviä juttuja. Dataa saisi olla reilusti enemmän, koska tilinpäätöstiedoissa on runsaasti eroja yhtiöiden välillä.
5 tykkäystä
Cool!
Jos olisit pannut pelimerkit top3-tuottoennusteille, eli Outokumpu, cargotec, Fortum, olisi tuotto ollut noin 10%, mikä H2:lla olisi ihan hyvä.
1 tykkäys
M6 kilpailu on mielenkiintoista seurattavaa tälle vuodelle - se alkaa virallisesti maaliskuussa, ja kestää läpi vuoden:
- Tiimit kisaavat kahdella osa-alueella 1) tuoton ennustaminen ja 2) sijoitusstrategian ”hyvyys”
- Tarkemmin ilmaistuna tiimit tuottavat joka neljäs viikko kullekin sijoitusinstrumentille 1) ennusteen todennäköisyydestä, että se tuottaa eniten, toiseksi eniten, …, viidenneksi eniten ja 2) otetut long/short positiot tuleville neljälle viikolle
- Rajattu 50 kpl ETF:n ja 50 kpl S&P500 yritykseen, jotka tarkennetaan vielä myöhemmin
- Ennusteita ja investointipäätöksiä tehdään ja evaluoidaan joka neljäs viikko, palkintoja jaetaan kvartaaleittain sekä kisan päätyttyä
2 tykkäystä
Edellinen jakso meni sen verran hyvin, että laitetaan uutta kehiin. Nyt mennään 91 kaupankäyntipäivää eteenpäin, jolloin viimeinen olisi ilmeisesti suunnilleen 20.5. Tällöin tuottojen olisi toivottavaa olla lähellä ennustettuja, jotka ovat listattuna alla.
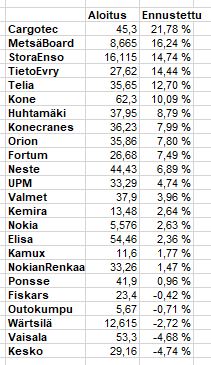
Ennusteissa näyttäisi ainakin olevan enemmän hajontaa ja pari yhtiötäkin on saatu lisättyä. Alla on paperi sijoitukset joilla lähdetään aluksi kyntämään.
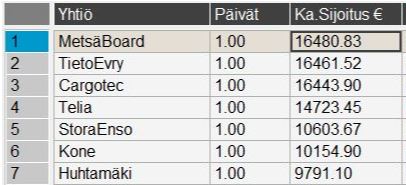
3 tykkäystä
Pikkuhiljaa kokonaisuus laajenee ja mukana nyt 29 yhtiötä. Uusina yhtiöinä Harvia, Talenom, Revenio, Qt ja F-Secure. Vertaan suoriutumista nyt kuitenkin vain edellisen viestin valintoihin.
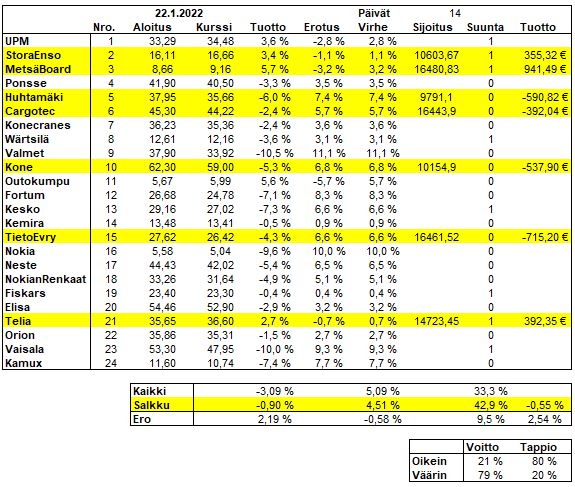
Keskimääräinen tuotto kaikilla yhtiöillä -3,09% ja yhtiövalinnoilla -0,9%. Valinnat ovat tuottaneet tasahajautuksella 2,19 %-yksikköä paremmin tähän mennessä. Painotukset huomioiden tuotto vähän parempi -0,55%, mikä on 2,54 %-yksikköä parempi kuin tasahajautus kaikkiin yhtiöihin.
Ennustetut tuotot on muutettu lineaarisesti vastaamaan kulunutta aikaa. Tähän verrattuna ennustevirhe on ollut keskimäärin 5,09 %-yksikköä. Valintojen keskimääräinen virhe 4,51 % on 0,58 %-yksikköä pienempi.
Vertaamalla vain ennustettua ja toteutunutta tuoton suuntaa oikein meni kaikista 33,3%. Valinnoista oikea suunta oli 42,9% osakkeista. Kaikista ennusteista positiivista tuottoa ennustettua oikein meni 21% ja väärin 79%. Negatiivista tuottoa ennustettaessa ennustettiin oikein 80% ja väärin 20%.
Ainakin tällä aikajaksolla shorttaamalla olisi saavutettu mukavaa ylituottoa. Vaatisi tosin jonkun verran koodailua ennen laajempaa testaamista. 2,5% ylituottoakaan ei tosin voi mitenkään huonona pitää 14 päivän aikana. Nopeasti nämä tulokset voi silti muuttuakin.
2 tykkäystä
Kolmasosa ennustejaksosta lähes täynnä, joten suoritetaan kevyttä tarkastelua vuodenvaihteen ennusteille.
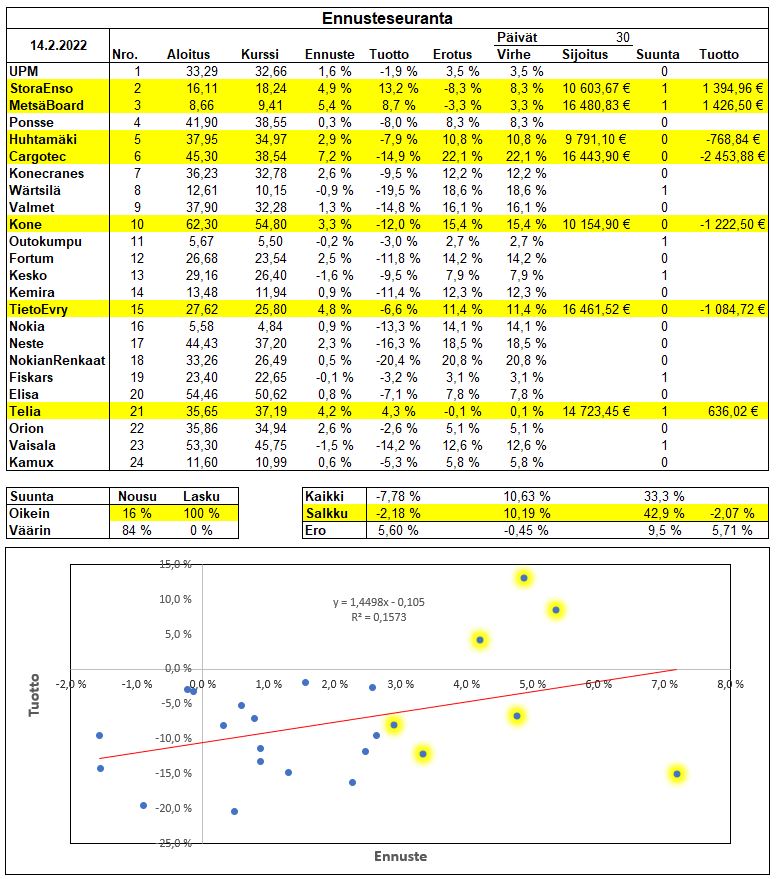
Keskimääräinen tuotto kaikilla yhtiöillä -7,78% ja yhtiövalinnoilla -2,18%. Valinnat ovat tuottaneet tasahajautuksella 5,60 %-yksikköä paremmin tähän mennessä. Painotukset huomioiden tuotto vähän parempi ollen -2,07%, mikä on 5,71 %-yksikköä parempi kuin tasahajautus kaikkiin yhtiöihin.
Ennustetut tuotot on muutettu lineaarisesti vastaamaan kulunutta aikaa. Tähän verrattuna ennustevirhe kaikilla yhtiöillä on ollut keskimäärin 10,63 %-yksikköä. Valintojen keskimääräinen virhe 10,19 % on 0,45 %-yksikköä pienempi.
Vertaamalla vain ennustettua ja toteutunutta tuoton suuntaa oikein meni kaikista 33,3%. Valinnoista oikea suunta oli 42,9% osakkeista. Kaikista ennusteista positiivista tuottoa ennustettua oikein meni 16% ja väärin 84%. Negatiivista tuottoa ennustettaessa ennustettiin oikein 100% ja väärin 0%.
Alkuvuosi kulunut yleisesti ottaen todella heikosti, muta onneksi voidaan vertailla toteutuneita lukuja. 5,6% ylituotto suhteessa tasahajautukseen voi pitää erittäin hyvänä suorituksena 30 päivän aikana. Kolmesta nouseesta osakkeesta onnistuttiin poimimaan kaikki. Ainoastaan Cargotec, jolta odotettiin kovinta nousua petti pahemman kerran.
1 tykkäys
Kokeillaampa välillä vähän erilaista metodia tilinpäätöstietojen ennustamiseen. Eli kyseessä on tilastollinen SARIMAX malli, joka huomioi trendiä, kausiluonteisuutta ja ulkoisia muuttujia. Ulkoiset muuttujat on esim. liikevoittoa ennustettaessa liikevaihto ja tuloksen osalla liikevaihto sekä liikevoitto. Liikevaihtoa ennustetaan tässä vaiheessa ainoastaan aiemmista arvoista.
Alla ensin SARIMAX ennusteet Ponsselle ja vertailun vuoksi Inderesin ennusteet. 2020 ennusteissa ei kovinkaan suurta eroa ole, mutta Q4 2021 luvuissa selvempiä eroja. Tulos ei ainakaa Q3 2022 osalta näyttäisi seuraavan kovinkaan hyvin liikevoittoa. Saattaa hyvinkin sisältää jonkin virheen. Muutaman päivän päästä julkaistaan lisää numeroita, jolloin vertailu jatkuu.
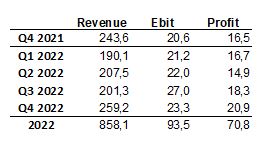
Sarimax
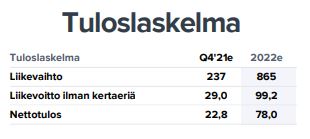
Inderes
1 tykkäys
Q4 ennusteet näytti molemmilla olevan turhan optimistiset, joka erän osalta.
Liikevaihto, Liiketulos, Tulos. Toteutuneet virheet miljoonaa euroa (%)
Oma
-17 (-7%), -1,9 (-9%), -0,6 (-3,9%)
Inderes
-10,4 (-4,4%), -10,3 (-35,4%), -6,9 (-30,4%)
Vaikutus tuleviin enusteisiin oli saman suuntainen, koska viimeisin trendimuutos siirtyy ennusteisiin.
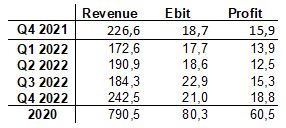
Vaikuttaa tämäkin päivä taas semmoiselta, että kannattaa tehdä jotain muuta kuin katsella pörssikursseja. Tilinpäätöstietojen ennustaminen ennustaminen vaikuttaa aika vähän tutkitulta asialta. Tutkimuksissa tunnutaan olevan lähinnä huolissaan julkaisemattomien tietojen käytöstä ennustamisessa. Joillakin kehitys riippuu huomattavan paljon markkinoiden hintakehityksestä ja osa toimii huomattavasti vakaammassa ympäristössä. Olennainen raaka-aineen hinta yhtiölle pitäisi ehdottomasti sisällyttää malliin. Tilauskannatkin sisältävät luultavasti olennaista informaatiota. Mitään yhtä kaikkiin yhtiöihin soveltuvaa mallia ei voi kehittää, vaan jokaiselle yhtiölle on oltava oma malli.
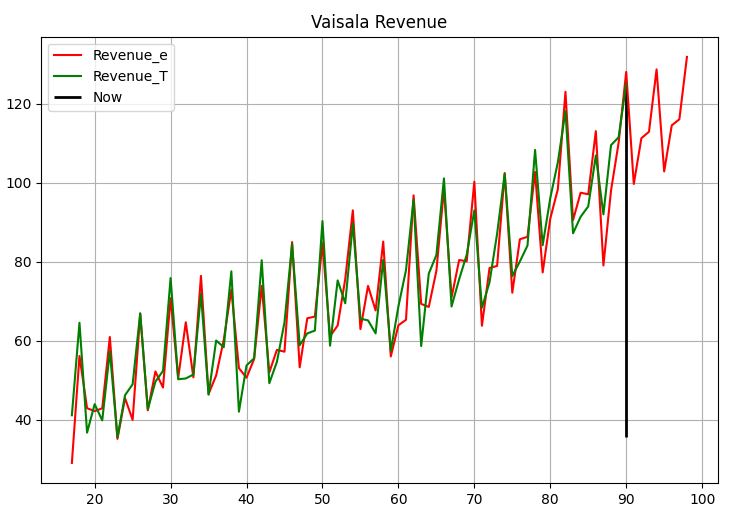
Vaisalalla liikevaihto vaikuttaa hyvin ennustettavalta, mutta tietysti jossain vaiheessa tämäkin voi muuttua. Historialliset ennustetiedot mustan pystyviivan vasemmalla puolella on laskettu rullaavasti. Ennusteet ovat punaisella ja toteutuneet luvut vihreällä värillä. Oikean puolen tulevaisuuden ennusteet ennustettu kahdelle vuodelle. Parin vuoden ennusteet auttava paremmin hahmottamaan tilannetta, mutta loppupäähän sisältyy varmaankin paljon epävarmuutta.
Liikevoitto Vaisalalla on kehittynyt ihan eri tavoin liikevaihdon kanssa. Ennustaminenkin on huomattavasti epävarmempaa, vaikka selvää kausiluonteisuutta esiintyykin. Kertaluonteisilla kuluilla ja mahdollisilla oikaisuilla on toisinaan iso vaikutus. Nopeasti kopioimalla luvut malliin on mahdollista tehdä merkittäviä virheitä. Vaisalan lukuihin ei ole juurikaan tehty oikaisuja.
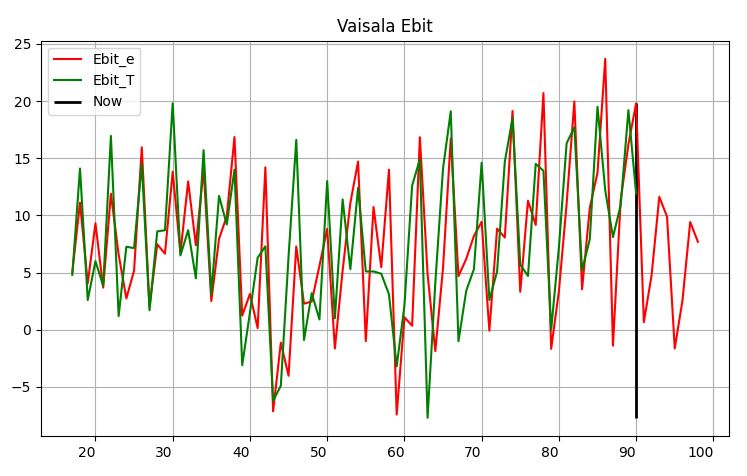
Yritysjärjestelyt, aineistojen pienuus ja poikkeukselliset tapahtumat vaikeuttaa käytännössä tämän kaltaista ennustamista. Algoritmin ja ihmisen yhteistyöllä menetelmä käyttö vaikuttaa kyllä aika hyvältä.
1 tykkäys
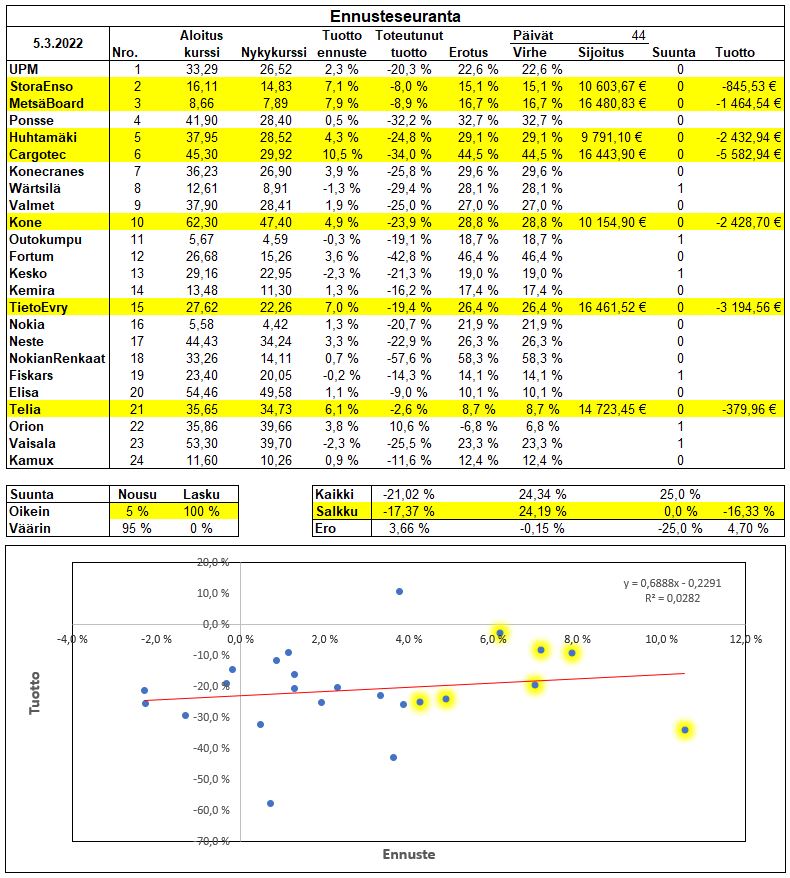
Melko mielenkiintoinen tilanne syntynyt näin puolessa välissä periodia, kun ennusteet ovat menneet päin Venäjää. Ainoastaan yksi(Orion) positiivisen tuoton suunta on ennustettu oikein vuoden alussa. Kurssilaskut ovat kyllä mennyt oikein, mutta eipä niitä tässä hyödynnetä muuten kuin olemalla sijoittamatta niihin. Salkkuvalinnoista kaikki suunnat on ennustettu väärin. Ennusteiden keskimääräiset virheet (24,19%) ovat samaa luokkaa kuin keskimäärin (24,34%). Ennustevirheen taso on 2,3 kertainen historiaalliseen keskiarvoon verrattuna. Ennusteiden selitysaste tippui erittäin heikoksi ollen 0,028. Salkkuvalintojen tuotto on kuitenkin 3,66 %-yksikköä parempi tasahajautuksella ja painotuksilla 4,70 %-yksikköä parempi kuin tasahajautuksella kaikkiin.
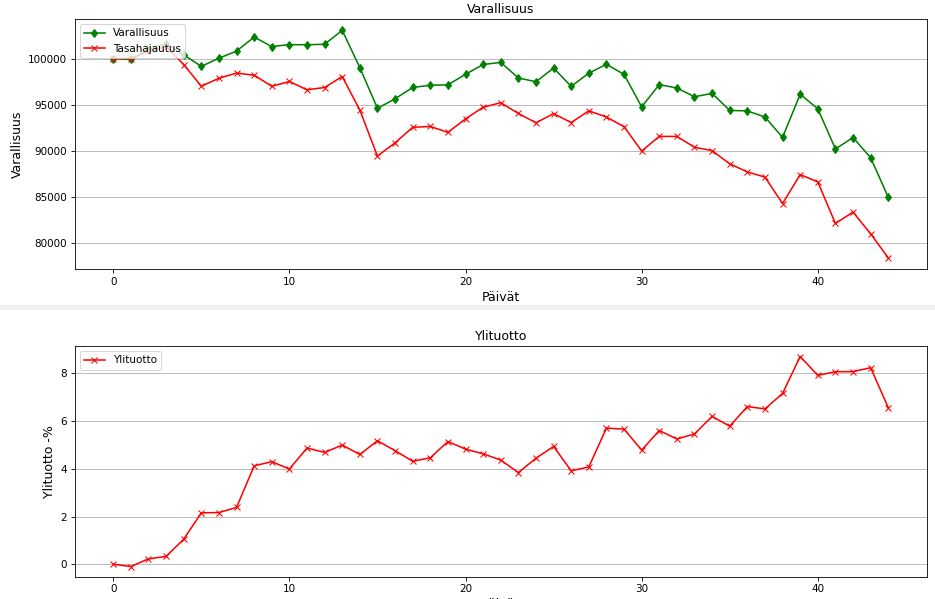
Päivittäisiä ennusteita hyödyntämällä on saavutettu lisäarvoa. Salkun tuotto “vain” -15% verrattuna tasahajautuksen -21,6% tuottoon. Tuotto näin ollen 6,6 %-yksikköä parempi Tässä mukana muutama aikaisemmin mainittu yhtiö enemmän, joten ei ole ihan 100% vertailukelpoinen ennusteseurantaan nähden. Ylituoton kehitys on ollut yllättävän hyvää. Viimeisen päivän suurin notkauttaja oli Outokumpu.
4 tykkäystä
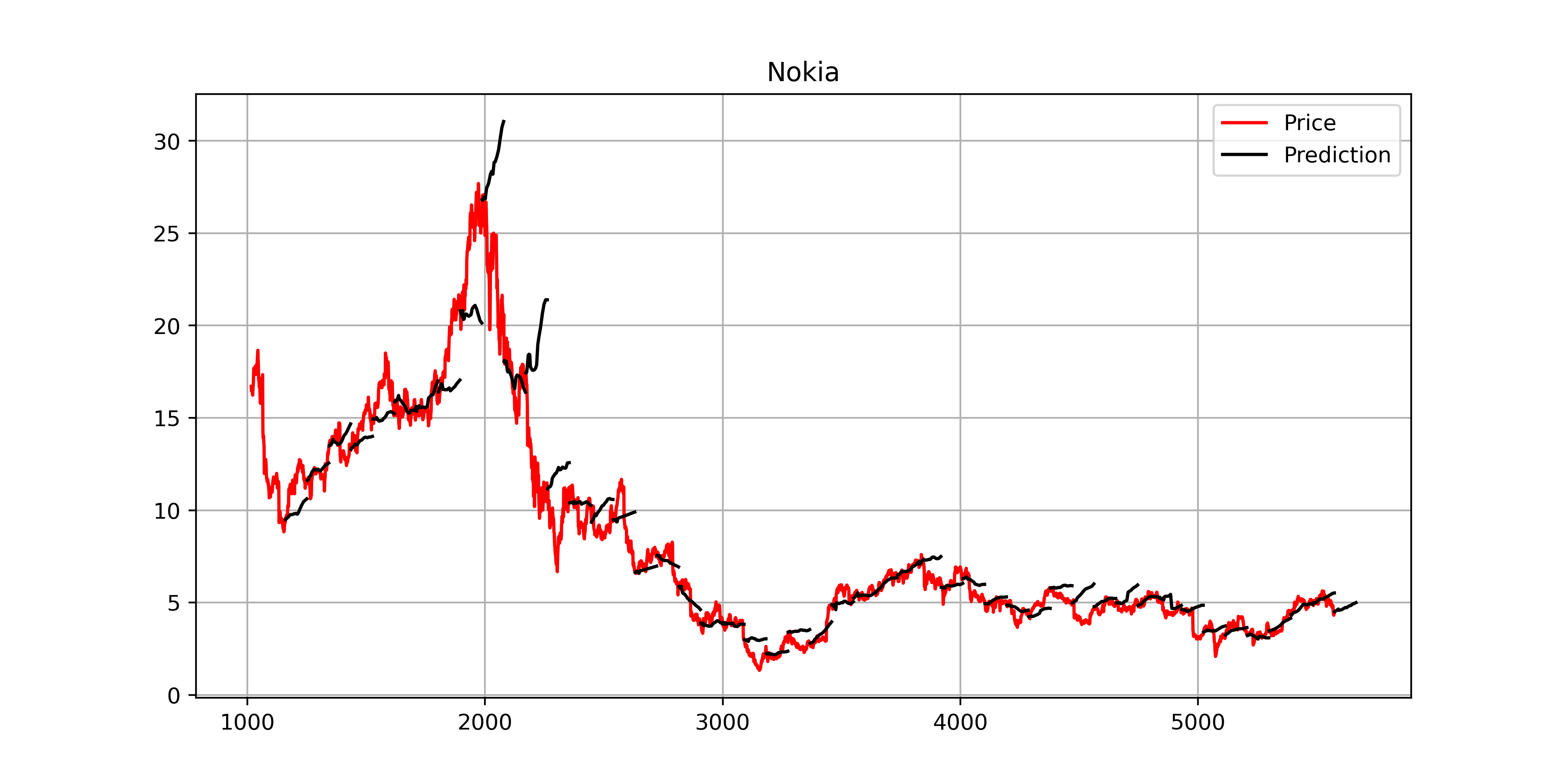
Ensimmäistä kertaa tuli piirrettyä ennusteita kurssikehitystä vasten. Mukana on ennusteet aina yhden jakson välen uusimmasta lähtien. Olisi kyllä kyllä pitänyt olla käytössä oikaistu kurssikehitys, niin olisi tullutvähän nätimpiä kuvioita. Pitääpä korjata asia myöhemmin, joten nyt osakeannit ja osingot ei ole kurssikehityksessä huomioitu. Tämä nyt on kutenkin pieni kosmeettinen haitta. Ainakin QT ja Revenion osalta tunnusluvut huitelee ajoittain sen verran omissa luokissaan, että ennusteet on käytännössä ylisovitettu aineistoon, eikä ne aina ole luotettavia.
Vaaka-akselilla n.1000 päivää vastaa aina neljää vuotta.Ennusteen viiva lähtee aina oikealta päivä ja kurssitasolta. Viimeisen ennusten päivä siis eilen.
Ennusteet tällä kertaa pdf muodossa.
Ennusteet.pdf (2,4 Mt)
2 tykkäystä
Tosi hyviä postauksi, näitä lukemalla oppii.
Viestiketjun ja Inderesin mallisalkun innoittamana testailin paljonko mitäkin mallisalkun osaketta olisi hyvä omistaa ns. optimaalisessa portfoliossa. Olen muuten aloittelija sekä tähän käyttämässäni ohjelmointikielessä Pythonissa että talousmatematiikassa, joten kannattaa olla skeptinen kaikkea kirjoittamani kohtaan.
Tavoite olisi siis löytää optimaalinen portfolio, eli salkku jonka arvo heiluu sopivan vähän. Valitaan osakkeiksi Inderesin mallisalkun Revenio, QT, Tietoevry, Harvia, Sievi, Sampo, Kamux ja Remedy.
Muodostetaan osakkeiden tuotto-odotuksista, heilunnasta sekä kurssien keskinäinen riippuvuuksista Python-ohjelmalla ns. tehokas rintama (efficient frontier), jossa on parhaita mahdollisia portfolioita. Tällaisia portfolitiota voisi olla vähän heiluva salkku (miminum volatility portfolio, merkitty punaisella tähdellä allaolevissa kuvissa) sekä enemmän heiluva, mutta paremmin tuottava salkku (optimal risky portfolio, tässä haetaan maksimaalista tuoton ja varianssin suhdetta eli Sharpen lukuaa, merkitty vihreällä tähdellä). Otetaan historiadataa neljältä vuodelta.
Portfolion muodostukseen tarvitaan siis osakkeiden tuotto-odotukset, kurssin heilunta sekä kurssien keskinäinen riippuvuus. Oletetaan aluksi että osakkeen tuotto-odotus on sama kuin osakkeen historiallinen tuotto ja mennyt heilunta kuvaa heiluntaa myös tulevaisuudessa. Kurssien riippuvuus toisistaan otetaan myös historiadatasta.
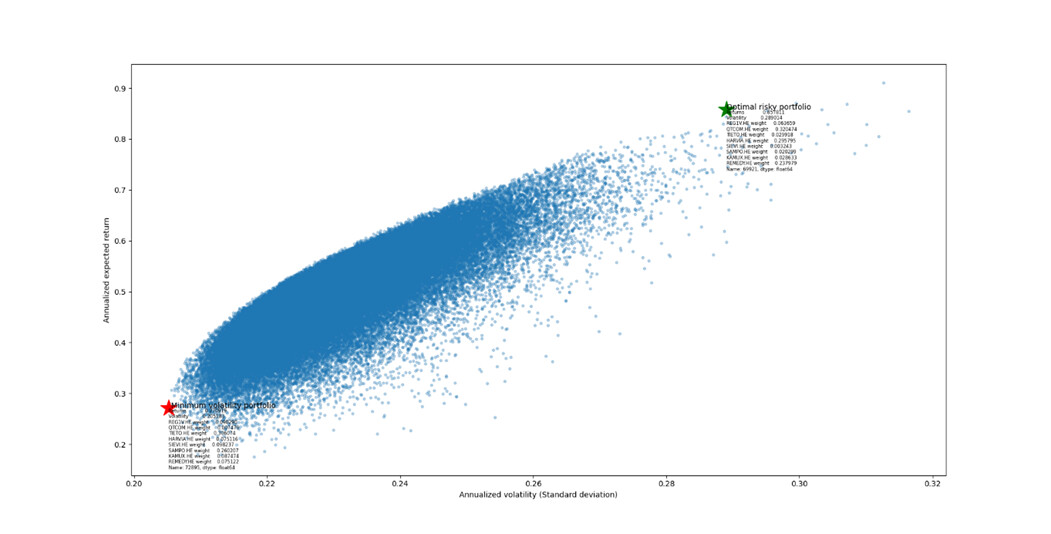
Tällöin optimal risky portfolio olisi melkein kokonaan Harviaa, QT:tä ja Remedyä, jotka ovatkin olleet nousurallissa neljän vuoden aikana. Vähiten heiluva portfolio olisi Tietoa ja Sampoa ja pienempiä määriä muita osakkeita. Tämäkin portfolio olisi tuottanut melkein 30% vuodessa, jopa pieni määrä menestyjiä nostaa tuottoja.
Osakkeen arvon tulevaa heiluntaa tai kurssien riippuvuutta ei voi varmaan arvioida kuin historiadatan perusteella? Keksittekö paremman keinon? Tulevaisuuden tuottojen ennustaminen menneisyyden perusteella tuntuu kuitenkin järjettömältä, joten voisiko vaikka Inderesin suositusluku olla parempi arvio tulevaisuuden tuotoista? Laitoin osakkeiden suositusluvut (esim. Remedy 46, Harvia 11) osakkeiden oletetuiksi tuottoprosenteiksi menneisyyden tuottojen sijaan. Oli tässä järkeä tai ei, joka tapauksessa tehokas rintama ja optimaaliset portfoliot muuttuvat aika paljon:
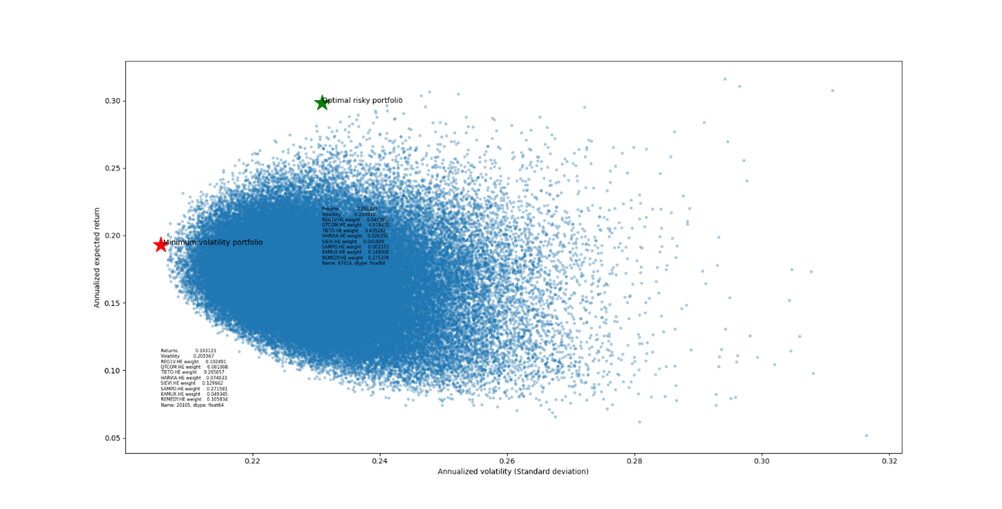
Tällöin optimal risky portfoliossa olisi suurimpina omistuksina Tietoa, Kamuxa, Remedyä. Nämä osakkeet ovatkin korkeilla suositusluvuilla Inderesin sivuilla. miminum volatility portfoliossa olisi suurimpina Tietoa, Sieviä, Sampoa ja Remedyä.
Jäin vielä miettimään hajautuksen merkitystä: Optimaalisesssa portfoliossa pitäisi löytää heikosti korreloivia osakkeita jotta tuotot olisivat tasaisia. Suomiosakkeiden kurssit näyttivät korreloivan keskimäärin 20…30% toistensa kanssa, joten lisätään portfolioon vielä jotain vähemmän suomen liike-elämän kanssa verkottunutta. Mikäköhän olisi hyvä siihen? Otetaan vaikka USAsta kiinteistösektorilta Realty Income. Tämän kurssi korreloi vähemmän Suomiosakkeiden kanssa, about 10…20%. Jos oletetaan että Realty Incomen odotettu tuotto olisi 10% vuodessa, saataisiin seuraavanlainen portfolio:
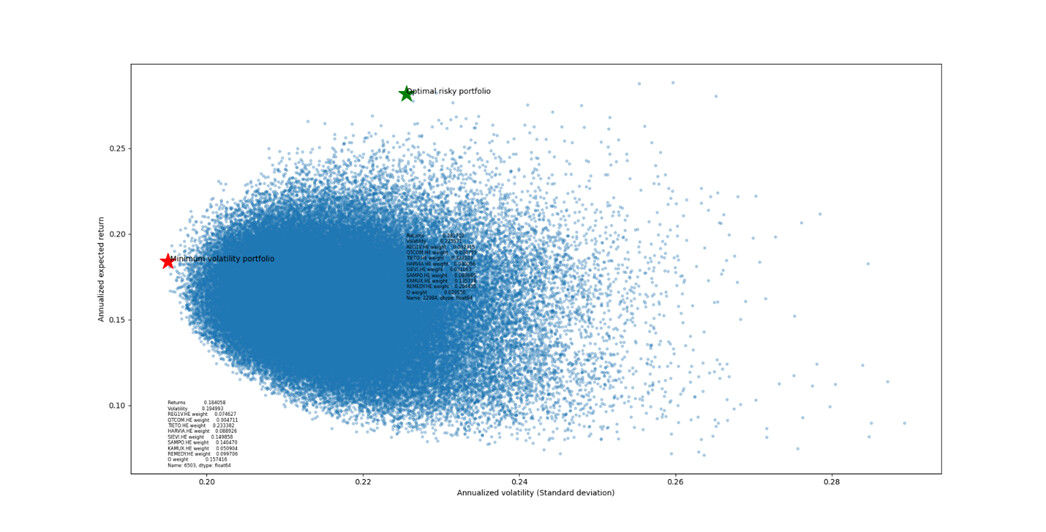
Nyt nähdään että optimal risky portfolio pysyy suunnilleen samanlaisena kuin viime kohdassa, mutta minimum volatility portfoliossa on nyt Tietoa, Sieviä, Sampoa ja Realty Incomea, Remedy lähti. Mielenkiintoisesti portfolion heilunta ei hirveästi näytä pienenevän viime kohtaan nähden. Voi olla että varioitavia osakkeita on sen verran paljon ettei algoritmi löydä hyvää portfoliota kovin luotettavasti.
Saisikohan joillain johdannaislla tuota heiluntaa alas kuitenkin niin ettei tuotto-odotus hirveästi kärsi?
4 tykkäystä
Jos tuotto-odotus ja volatiteetti on tiedossa niin voit simuloida osakkeen tuottoa. En tiedä voiko tohon enään mitenkään lisätä korrelaatiota mukaan. Simuloinneista voi sitten taas laskea kovarianssia ja korrelaatiota.

Palauttelin viellä mieleen osakekurssin simulointia. Aikajakso vuosi, tuotto-odotus 10% ja volatiteettu 20%.
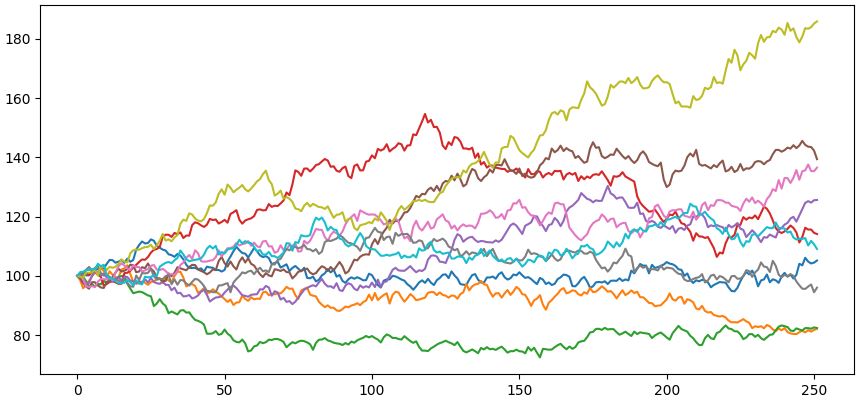
Silmukat ei oiken kopioidu nätisti mutta kai ne tästä saa kopioitua jos haluaa
import pandas as pd
import math
import numpy as np
import matplotlib.pyplot as plt
Data = pd.DataFrame()
Te = 0.10 #Tuotto odotus %
Vol = 0.20 #Volatiteetti %
for x in range(0, 10):
Data.at[0, ‘Kurssi{}’.format(x)] = 100
for i in range(1, 252):
Data.at[i, ‘Kurssi{}’.format(x)] = Data.at[i-1, ‘Kurssi{}’.format(x)]math.exp((Te-pow(Vol,2)/2)(1/252)+Vol*pow(1/252,1/2)*np.random.randn())
Data[‘Kurssi{}’.format(x)].plot()
plt.show()
1 tykkäys
Backtestaamalla saisit jonkinlaista kuvaa siitä, miten strategiasi olisi toiminut aiemmin. Eli pilkot aikasarjat useaan kertaan ajallisesti eri kohdista, toistat historiaosuudella yllä tekemäsi optimaalisen portfolion valinnan, ja vertaat näin saadun portfolion suoriutumista tulevaisuuden tuottoihin (jotka tiedät jo nyt, koska pilkoit aikasarjan).
Korreloituneita aikasarjoja voi simuloida esimerkiksi Cholesky -hajotelman avulla, tässä on hyvin samankaltainen toteutus, mitä itse joskus tehnyt mm. öljyn/kaasun hinnan simulointiin. ”Realistisimman näköisen” lopputuloksen sain kuitenkin usein ”diskretoidulla monte carlolla”, jossa aikasarjat pilkotaan intervalleihin arvojen perusteella, ja aina samplataan satunnaisesti seuraava intervalli, ja kunkin intervallin sisältä otetaan vielä satunnainen arvo tasajakaumasta. Simulointi tosin on aina vaan simulointi… ![]()
Ikävä kyllä edellä mainituista jäi koodit edelliselle työnantajalle, niin ei ole laittaa niitä jakoon - siellä varmaan käy koneet kuumana, kun nämä mallinnukset tehtiin nimenomaan erilaisia ”mitä jos” tilanteita varten: toimitusketjujen ongelmat, sota, brexit, Trumpin tullit, komponenttipula, lakko, … ![]()
3 tykkäystä
Ihan mielenkiintoiselta näyttää toi Cholesky -hajotelma. Vaatii vähän enempi perehtymistä, että tuosta saisi enemmän irti. Voitko vähän kertoa minkä tyyppisiä yhtälöitä syötitte Cholesky -hajotelmaan vaikka öljyn hinnan simuloinnissa?
Oma yhtiökohtainen raportointi on ollut pitkään aika olematonta. Nyt on parin viikon aikana syntynyt PDF:ää ohjelmallisesti. Punaisella on piirretty historialliset tiedot ja vihreällä ennusteet tai ennusteen jonkin näköiset rajat. Otteita Valmetin rapsasta alla. Varsinkin yhtiön historiallinen kehitys näyttää erittäin hienolta. 2018 näyttäisi tapahtuneen, jotain tilinpäätöstietojen vaihtelua lisäävää.
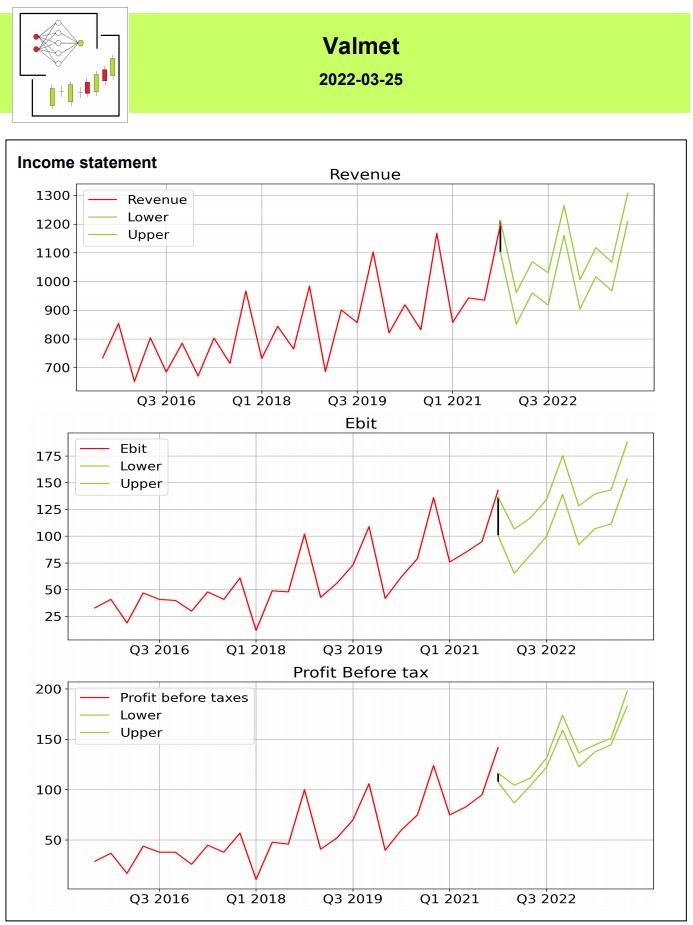
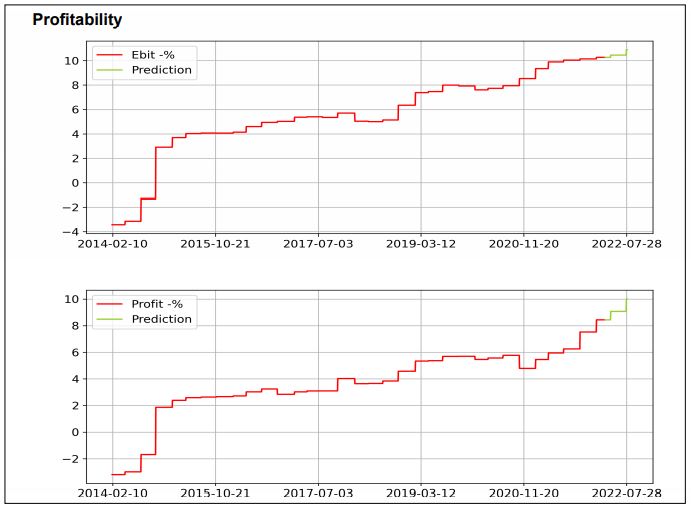
12kk juoksevien liiketulos -% ja tulos -% kehittyminen on hyvin tasaista.
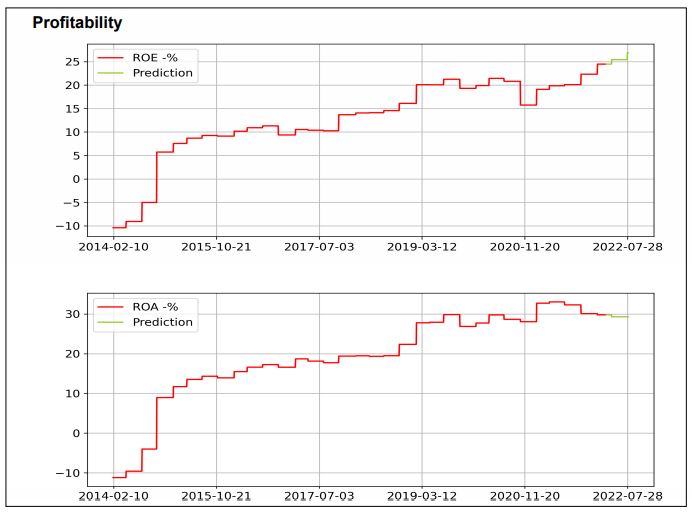
Sama tahti on ollut myös oman pääoman tuotolla ja kokonaispääoman tuotolla.
Ylempänä oikealla viimeisin ennuste ja sen vasemmalla puolella kolme vanhaa ennustetta viimeisen reilun vuoden ajalta. Tuleva ennuste on negatiivinen. Alempana viimeisin ennustet suhteessa pitkän ajan kurssikehitykseen.
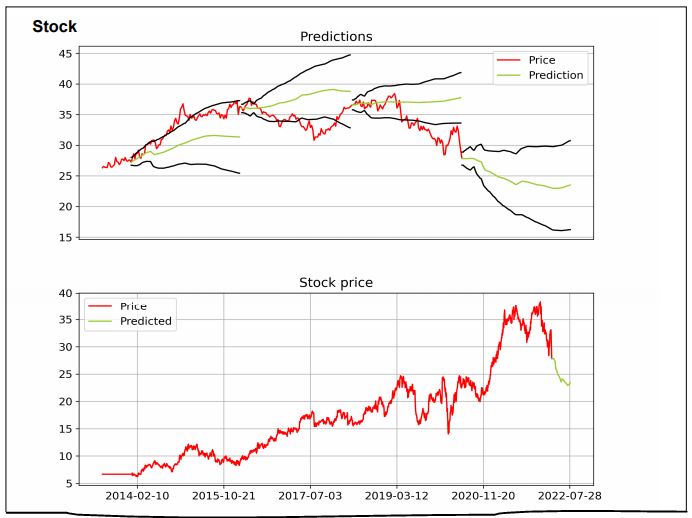
Osake näyttäisi tulostuotolla mitattuna olevan aika edullisesti hinnoiteltu suhteessa historiaan. P/S laskisi lähemmäs normaalimpaa tasoaan mikäli ennuste toteutuisi. P/B:llä mitattuna oltaisiin sitten taas keskiarvoa alemmalla tasolla.
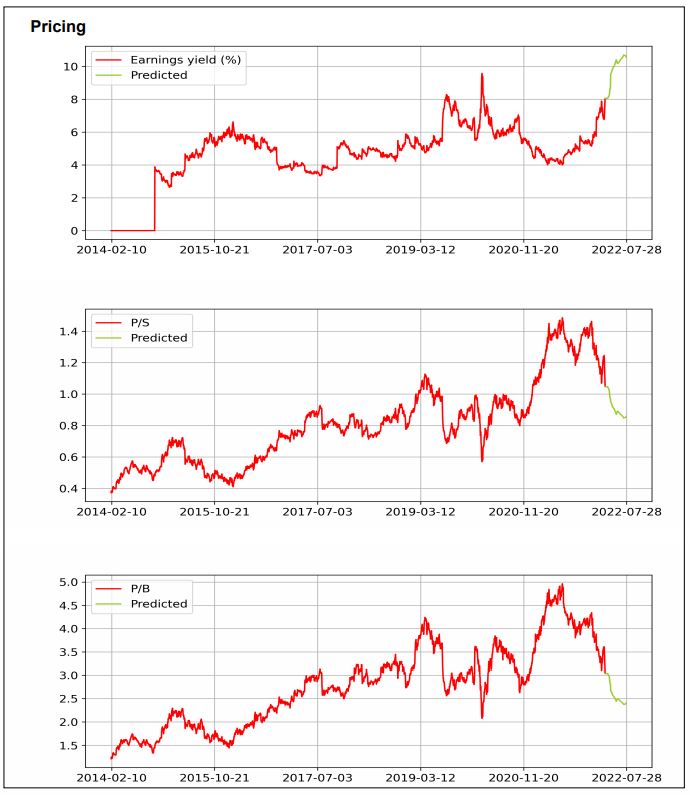
Ainakin muutama idea on tällä hetkellä raportin kehittämiseksi, mutta vähän muut kiireet painavat päälle.
Tämä ei ole sijoitussuositus!
2 tykkäystä
Cholesky -hajotelmssa ideana on ottaa eri aikasarjojen korrelaatioita huomioon, ei sen kummempaa. Öljyn hinnan simuloinnissa oli muistaakseni eri pituisia öljy- ja maakaasufutuureita mukana.
Jos yhtälöitä on tarpeen syöttää mukaan, niin sitä voi yrittää lähestyä esim. systeemidynaamisella mallinnuksella.
Oho, luin vähän väärää artikkelia, kun niitä oli tossa pari ulkoisesti hyvin samanlaista auki.
1 tykkäys
Tuossa kuvassasihan siis sinulla on perus Black-Scholes mallin dynamiikka. Eli siis dS_t = \mu S_t dt + \sigma S_t dW_t jossa W on Brownin liike. Simulaatio on käytännössä tuosta vain Eulerin menetelmällä diskretisoitu.
Korrelaation lisääminen ei ole sen vaikeampaa kuin simuloit SDE:tä
dS_i(t) = \mu_i S_i(t) dt + S_i(t) ∑\sigma_{ij}dW_j(t)
Jossa tuo \sigma_{ij} on volatiliteetti matriisi joka pitäisi koostaa markkinakorrelaatioista.
Kannattaa lueskella Särkän kirjaa ja Shreven luentomonistetta. Linkkaan ne tähän alle kun ovat ilmaisessa jakelussa netissä.
Shreve: http://efinance.org.cn/cn/FEshuo/stochastic.pdf
Särkkä: https://users.aalto.fi/~asolin/sde-book/sde-book.pdf
Lisäyksenä, kannattaa katsoa sivu 203 tuosta Shrevestä. Siellä hyvin yksinkertaisesti esitetty 2 ulotteinen tapaus korreloivista osakkeista. Särkkä on enemmän SDE sovelluskirja, mutta selittää esim hyvin tuosta simuloinnista ja parametriestimoinnista.
PS. Koska Brownin liike on Markov prosessim voit välttää tuon looppaamisen sillä että arvot nuo normaalijakautuneet satunnaisluvut etukäteen, ja lasket tuon kurssisimulaation vektorioperaatioilla. Python on aika hidas kieli looppaamaan ja jos simuloit useamman aikasarjan kerralla niin nopeasti tulee aika hidasta puuhaa ilman vektorisointia.
3 tykkäystä
Vastaan nyt vielä tähänkin kun on aikaa. Ensinnäkin todella mielenkiintoinen idea tuo Inderes suositusten integroiminen malliin. Etenkin nuo vaikutukset mitä sillä oli.
Ei varmaankaan, mutta mallissasi on nyt sellainen implisiittinen oletus, että volatiliteetti olisi vakio. Näin se ei kuitenkaan empiirisesti ole. Ks vaikka historiallinen IV applen osakkeelle.
Laajentaakseni tätä simulaatio näkökulmaa jonka jo muut ovat ottaneet puheeksi,
tuossa olisi ehkä joitan saumaa sovittaa IV aikasarjoihin jokin malli, ja simuloida sen avulla stokastisen volatiliteetin mallia. Antasisi mielestäni paljon realistisemman kuvan tulevasta kurssivaihtelusta.
En ole aiemmin tullut ajatelleeksi portfolio-optimointia FAMA 3-factor mallin ja modern portfolio teorian ulkopuolella. Löysin kuitenkin nopealla googlailulla jotain ihan mielenkiintoista. Alla oleva paperi edustanee terävintä kärkeä. Käyttää Volterra-Heston stokastisen volatiliteetin markkinamallia oletuksena arvopapereiden hintojen käyttäytymiselle, eikä perinteistä lognormaalia mallia. Toisaalta perinteinen Heston mallikin voisi ehkä toimia?
Mitä tulee tuohon hajautukseen, voisikohan malliin jotenkin rakentaa sisälle rajoitteen siitä että konsentraatiot per toimiala ei kasva liian suureksi. Varmaan suuri paine tällaisella mallilla antaa suuret kertoimet teknologia-alan firmoille koska niistä saa hyviä tuottoja, mutta tämä ei lienee hyvää sellaisen Black Swan -riskin kannalta.
Tähän voisi toimia myös jokin volatiliteetti johdannainen (esim variance swap) mutta noita ei taida saada kuin OTC. Vix optiot toimisi ehkä Amerikka osakkeille?
1 tykkäys