Näillä palveluille alkaa hyvää vauhtia ilmestyä avoimempia vaihtoehtoja.
3 tykkäystä
Ekassa videossa hyviä pointteja siitä, miten LLM voi viedä mainostaminen aivan uudelle tasolle. Käytännössä saat juuri sinulle kirjoitettuja mainosviestejä joka voidaan räätälöidä sen paremmin mitä enemmän taustatietoja sinusta on saatavilla. Meillä jokaisella on omat heikot kohdat ja arvot joihin vetomalla mainosten tehoa voidaan kasvattaa huomattavasti.
Mainosten ohella manipulointia voidaan tehostaa huijausviestien generoinissa. Nythän saamme huonolaatuisia nigerialaiskirjeitä ja pankkitietojen kalasteluja jotka on helppo tunnistaa kalasteluksi. Tulevaisuudessa saamme valitettavasti laatua ja uhrien määrä kasvaa.
AI saattaa myös korvata ihmissuhteita. Oikean tyttöystävän saaminen on hankalaa ja AI tyttis jaksaa aina piristää.
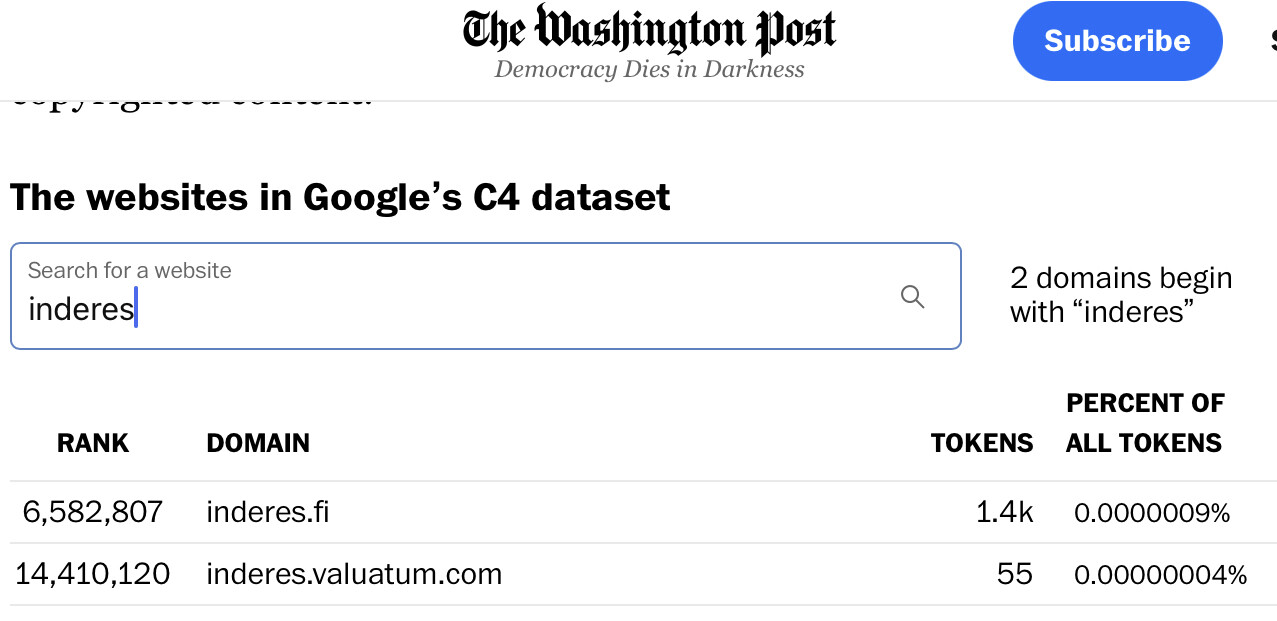
Loppuun vielä WaPon juttu josta voi tarkistaa onko oma webbisivu osa commoncrawlia jota on käytetty chatgptn treenaamiseen. Inderesin osalta keskustelut eivät näytä olevan. Muutenkin kontribuutio vaatimaton 1.4k tokenia. Yle.fi sivulta oli 330k tokenia
2 tykkäystä
Muutama vuosi sitten oli kovaa huutoa, jos sanoi olevansa SEO-osaaja. Hakukoneoptimoinnilla moni varmasti onkin tilinsä tehnyt, mutta luulisi näiden tekoälypalveluiden laittavan vähän uusia haasteita optimoijan pöydälle.
Toistaiseksi hauska asetelma, kun useimmat älyt on koulutettu tietyllä datalla, jonka saatavuus on katkaistu yhteen tiettyyn päivämäärään. Joten tämän päivän optimoinneilla voi vaikuttaa vain haman tulevaisuuden älyjen sisältöön. Sikäli mikäli niiden algoritmit tehdään samoilla ehdoilla, johon optimointiguru omat tekonsa kohdentaa. Perinteinen optimointi ei enää ehkä futaa ja pitää keksiä uudet temput.
Tähän liittyen on helppo myös kuvitella miten esimerkiksi muuan kolajuomabrändi saisi pientä korvausta vastaan tekoälyn suosittelemaan ruokajuomaksi nimenomaan Coca Colaa ja vähän dumaamaan Pepsiä siinä sivussa.
Tällä hetkellä tuntuu siltä, että tekoälyjä markkinoidaan ”tuulipuvuille” uutena Messiaana ja varmasti sitä monessa asiassa ovatkin. Ongelmaksi muodostunee kuitenkin jossain määrin optimoinnin/korruption vääristämä output.
2 tykkäystä
Chat GPT:n taustalla häärii nainen,kyllä Matti ja Teppo sen jo tiesi.
4 tykkäystä
Siis jos tarkoitat hakukoneita, tuollainen näkymättömien avainsanojen luominen sivulle oli ehkä relevanttia 2000-luvun alkupuolella, mutta ei sellaisella nykyään enää pitkälle pääse. Varmaan joissain rajoitetuissa konteksteissa tuo voidaan sallia, mutta jos Google ym. tulkitsee sen avainsanaspammiksi, niin se on nopea tapa saada sivu poistetuksi indeksistä. Spammia kyllä riittää niin paljon, että sitä tulee hakutuloksiin muutenkin, mutta tuskin siinä on mitään etua saavutettu piilotetuilla avainsanoilla. On myös ihan mahdollista, että nuo hakukoneet joissain tapauksissa renderöivät sivun sisällön palvelinpuolella ja arvioivat sitä kautta, mikä sisältö on oikeasti näkyvissä ja relevanttia.
Tuo sama tekniikka voi ehkä paremmin toimia LLM:ien opetusmateriaalien kanssa, mutta niidenkin sisältöön tehdään monenlaisia filtteröintejä ennen kuin webbisivuja käytetään opetusmateriaalina. ![]()
4 tykkäystä
Okei, kontekstista ei oikein käy asia selville. Tuostakin viestistä AI voidaan tulkita monella tavalla, onko se LLM-botti vai jokin muu rankkausalgoritmi, jota hakukone käyttää tulosten järjestämiseen? Luultavasti se tavallisissa hakutuloksissa näytettävä tekstilyhennelmä valitaan myös jollain koneoppimisen algoritmilla. Itse näkisin hakutulosten näyttämisen nimenomaan tekoälyongelmana. Tavallaan tuo vain viittaa Googlen perustajien näkemyksiin, koska he ottivat aikoinaan tavoitteeksi ratkaista tuon hakutulosten järjestämisen algoritmisesti, sitten myöhemmin siihen tuli mukaan lisää ja lisää koneoppimista. Jos hakukone ei ymmärtäisi millään tasolla sivujen sisältöä, tuloksena olisi juuri noita vuosia sitten näkyneitä ongelmia yksinkertaisen avainsanaspammin kanssa. Varmaan nuo LLM-botit voivat myös soveltaa jotain samoja filtterointeja verkkosivuja hakiessaan kuin tavallinen hakukone. ![]()
1 tykkäys
Kuva nykyisistä LLM malleista.
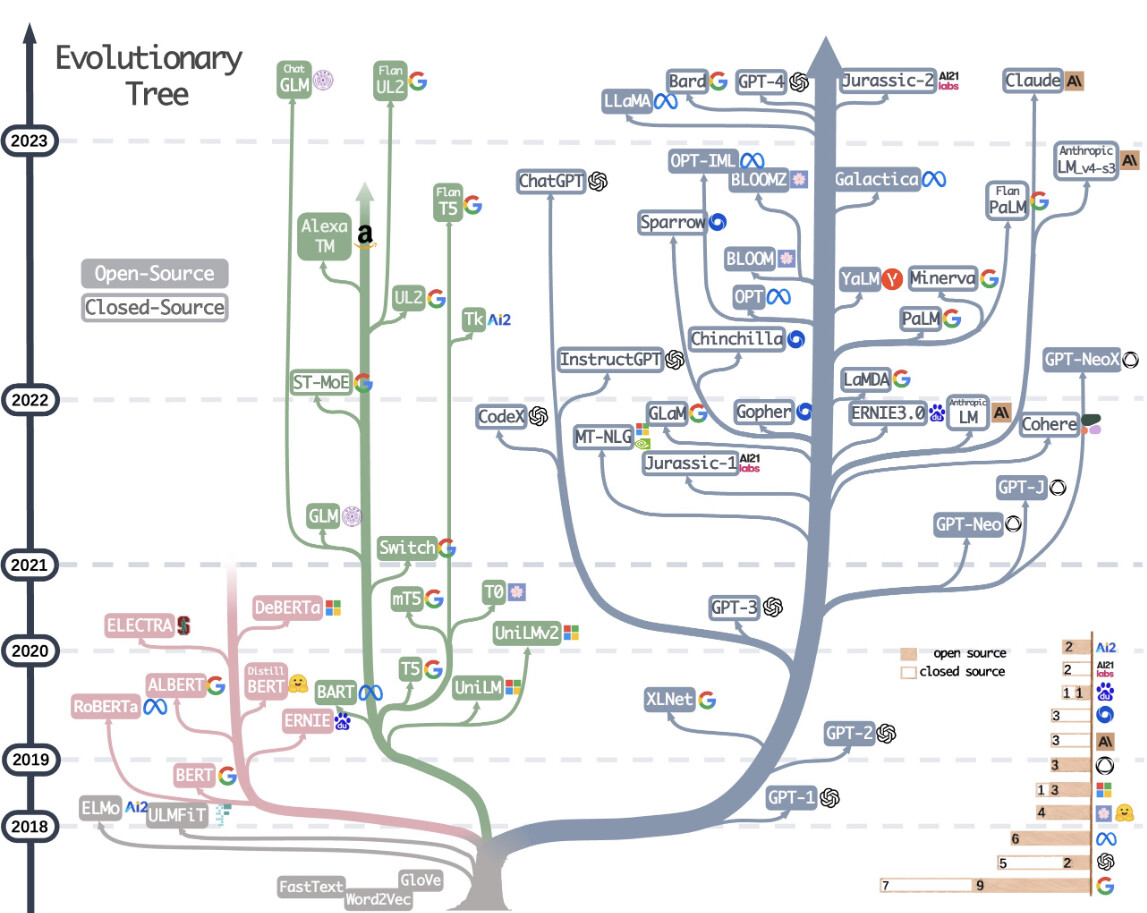
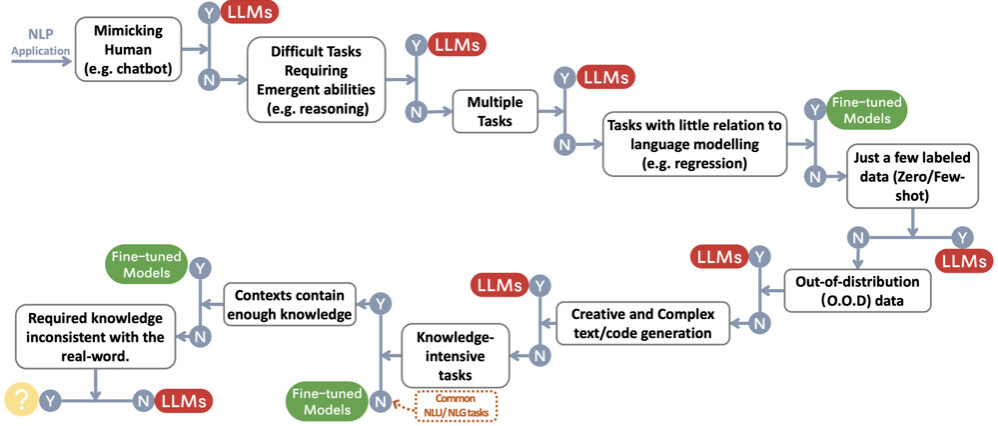
Valitako LLM vai jotain muuta
Gittirepo josta kuvat. Paljon linkkejä papereihin.
Lisäselitystä jota ei Githubissa

3 tykkäystä
Kaikkien hyvien kirjoitusten ja kommenttien jälkeen lasken riman taaperosarjaan. Tämä sopisi jatkoksi taannoin ketjussa nähdylle pizzamainokselle. Pizzaa ja olutta. Mainos yhdistelee mainiosti eri genrejä. On konservatiivista otetta, äijämeininkiä, biletystä, sukupuolirajoista piittaamatonta eroottisvaikutteista nautiskelua – you name it. Jäi jotenkin vaivautunut olo eli mainos jää päähän ja on siten onnistunut?
Sekoäly tositoimissa. Osa n. → “Bud light” beer commercial.
Edit. Kaivelin samaa aihetta hieman syvemmälle. Nämä tuotokset voivat näyttää hassuilta, mutta jos tekisin työkseni vaikka mainosvideoita saattaisin olla hieman huolestunut.
8 tykkäystä
Ei sittenkään emergenttejä ominaisuuksia. Näin väittää uusi preprint joka tarkasteli emergenteiksi väitettyjä ominaisuuksia tarkemmalla lineaarisella ja jatkuvalla mittauksella.
Kuten edelliseen postaukseeni emergenteistä ominaisuuksista täällä jo ansiokkaasti huomautettiin x akseli kasvoi eksponentiaalisesti, mutta y akseli vain lineaarisesti. Hassua etteivät alkuperäisen paperin kirjoittajat huomanneet tätä ongelmaa joka heti jäi nalkkiin inderes palstan brutaalissa vertaisarvioinnissa. Toinen ongelma oli epäjatkuvat mittarit, jotka eivät palkinneet siitä että mallit saivat tuloksia joka lähestyi oikeaa. Esim anagrammi tehtävässä sai pisteen per sana vain jos anagrammi meni täysin oikein. Tässä tilanteessa, kun tietty taso saavutetaan alkaa tulla oikeita anagrammeja vauhdilla ja ominaisuus näyttää emergentiltä, vaikka malli olisi lineaarisesti lähestynyt tehtävän oikeita ratkaisuita jo pitkän aikaa.
Edit linkki: https://arxiv.org/pdf/2304.15004.pdf
5 tykkäystä
“Meillä ei ole vallihautoja, mutta ei ole OpenAI:lläkään.” → Open source mallit tulee ja jyrää. Tämä on TLDR vuodetusta Googlen memosta AI:n kehityksestä. Koko dokkari ja lyhyt video aiheesta viesti lopussa alla jotain käännettyjä parhaita paloja. Kannattaa lukea koko dokkari paljon hyviä linkkejä kuten LLM:n leivänpaahtimessa ![]()
-
“Olemme tarkkailleet jatkuvasti OpenAI:ta. Kuka saavuttaa seuraavan merkkipaalun? Mikä on seuraava askel? Mutta epämukava totuus on, ettemme ole hyvässä asemassa voittaaksemme tämän kilpavarustelun, eikä OpenAI ole myöskään. Samaan aikaan kun me olemme taistelleet on kolmas taho tullut kuin varas hiljaa yöllä. Puhun tietenkin avoimesta lähdekoodista. Selkeästi sanottuna, he menevät meistä ohi. Vaikka malleillamme on vielä pieni etumatka laadussa, ero kuroontuu hämmästyttävän nopeasti umpeen. Avoimen lähdekoodin mallit ovat nopeampia, joustavampia, yksityisempiä ja suhteessa tehokkaampia. He saavat aikaan asioita, joihin me käytämme 10 miljoonaa dollaria ja 540 miljardia parametria, vain 100 dollarilla ja 13 miljardilla parametrilla.”
-
"Meillä ei ole mitään salaisia keinoja. Paras toivomme on oppia ja tehdä yhteistyötä Googlen ulkopuolella. Meidän tulisi priorisoida kolmansien osapuolten integraatioiden mahdollistaminen. Jättimäiset mallit hidastavat meitä. Pitkällä aikavälillä parhaat mallit ovat niitä, jotka voidaan iteroida nopeasti. Meidän pitäisi panostaa enemmän pieniin variantteihin, nyt kun tiedämme, mitä on mahdollista alle 20 miljardin parametrin alueella.
-
“Maaliskuun alussa avoimen lähdekoodin yhteisö sai käsiinsä ensimmäisen todella kykenevän perusmallin, kun Metan LLaMA vuoti julkisuuteen. Siinä ei ollut ohjeistuksia tai keskustelun säätöä, eikä RLHF:ää (Reinforcement learning from human feedback). Siitä huolimatta yhteisö ymmärsi välittömästi, kuinka merkittävä lahja heille oli annettu.”
-
" Monessa mielessä tämä ei pitäisi yllättää ketään. Avoimen lähdekoodin suurten kielimallien nykyinen nousu seuraa tiiviisti kuvageneraation muutosta. Ilmiö oli selvä: midjourney jyrää OpenAI:n mallit. On vielä nähtävissä, tapahtuuko sama suurten kielimallien kohdalla, mutta samankaltaiset rakenteelliset tekijät ovat läsnä."

11 tykkäystä
Tekoälyillä on niin paljon ominaisuuksia (rajattomasti), että varmasti saadaan sopivilla määritelmillä vaikka millaisia tuloksia.
Se mikä on varmaa on, että yhteiskunnallisesti tekoäly/kielimallit ovat emergenttejä.
1 tykkäys
Onhan tämä ihan huikeaa, että käytännössä muutaman satasen tai tuhannen euron investoinnilla saat käytännössä täsmälleen omaan use caseen räätälöidyn, GPT-4 suorituskykyyn yltävän transformerin.
Ja tämä kaikki on kehitetty 1-2 kuukauden aikana. Voi vain kuvitella, millaisia uusia mahdollisuuksia tämä avaa, kun yritykset ympäri maailman ymmärtävät tässä piilevän arvon.
Vaikuttaa siltä, että tässä vaiheessa on ihan mahdoton veikata voittajaa. Ne firmat, joilla on arvokasta dataa, tulevat olemaan vahvoilla. Itse ajattelin, että laskenta tulisi tässä pullonkaulaksi, mutta näyttäisi nyt siltä, että nää pruning-menetelmät menevät niin kovaa eteenpäin, että laskennan voi antaa jo CPU:lle tehtäväksi.
Hienoa aikaa kyllä olla tällä alalla duunissa.
13 tykkäystä
Bard julkaistu maailmalle pl EU. King of regulation saavutti tavoitteensa.
Oma kokemus sanoo, että ChatGPT on edelleen selvä ykkönen jos sitä vertaa Bingiin tai OpenAssistanttiin. Tuskin Bardissa vielä tässä vaiheessa paljoa menettää, mutta suunta on pelottava.
5 tykkäystä
Aika Sci-filtä alkaa kyllä meno tuntumaan. Monet näkevät mahdollisuuksia ja niitä varmasti riittää. Ikuisena pessimistinä itseäni kuitenkin ensisijaisesti pelottaa, mihin suuntaan kehitys kehittyy ja millainen maailma on 10-20v päästä. Moni ala tulee olemaan murroksessa ja monelle saattaa jäädä luu käteen.
7 tykkäystä
![]()
16 tykkäystä
Oman käytön perusteella ChatGPT on kaikista kokeilemistani kielimalleista edelleen selvästi paras ja tämä muutos palvelun PLUS-käyttäjille luultavimmin kasvattaa eroa entisestään.
Sijoittajille mielenkiintoinen lisä on tämä →
Osakekurssien ennustaminen. ChatGPT pystyy käyttämään hyväkseen yritysten tulostietoja arvioidakseen niiden osakkeiden lähiaikojen kehitystä.
Tuosta ennustamisesta en oikein perusta, mutta eiköhän vastauksia löydy muihinkin sijoittamiseen liittyviin ajankohtaisiin kysymyksiin. Veikkaan joka tapauksessa merkittävää maksullisten käyttäjien lisääntymistä sijoittajien keskuudessa. Ehkä tämän voisi vähentää ensi vuoden verotuksessa…
10 tykkäystä
3 tykkäystä
Hieman vanhentunutta tietoa. Kysehän on regulaatiosta ja sitä kaikki tuntuvat haluavan – myös OpenAI. Sen täytyy kuitenkin perustua yhteistyöhön, ei yksipuoliseen saneluun. Ainakin perjantaina Altman oli varsin sovittelevalla kannalla.
Eniten ihmetyttää hiljaisuus Amazonin puolelta. Tässä on kuitenkin jo puoli vuotta ChatGPT:n julkaisusta. Uutta Amazon echo:a on kuuleman mukaan taas tulossa, mutta se ei tuo mitään uutta.
Jotain Amazonillakin oli vireillä, mutta tämä kuva kuvastaa tilannetta melko osuvasti.
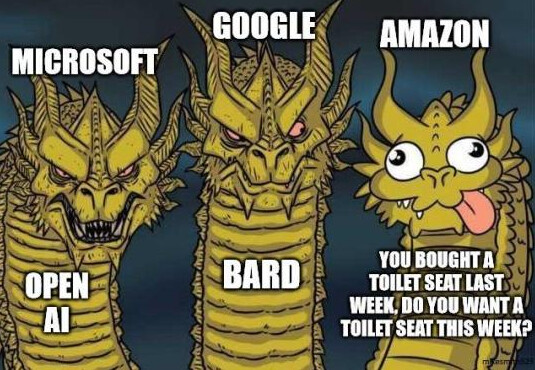
14 tykkäystä
Pitää muistaa, että EU-lakeja vasta sorvataan. Eli ne ovat valmistelussa.
Lain käsittelyn yhteydessä tapahtuva monipuolinen asiantuntijoiden kuuleminen vaikuttaa usein lakien sisältöihin EU-tasolla – toisin kuin Suomessa usein käy – mutta ei mennä nyt siihen.
Kyllä se on, mutta pitää vaan laittaa erikseen päälle. Tässä videossa esimerkiksi on ohjeet: ChatGPT Browsing - ChatGPT:llä on nyt pääsy nettiin! - YouTube
2 tykkäystä