Ymmärrän, että asiasta ollaan kiinnostuneita, mutta en oikein ymmärrä sitä, että se olisi mikään uutinen tai yllätys. Mikä tahansa oppiva asia, oli sitten ihminen, koira tai tietokone, on riippuvainen materiaalista, jolla sitä opetetaan. Kaikki ihmiset olivat rasisteja ja sovinisteja silloin, kun maailma oli sellainen. Ja on vieläkin niissä maissa, joissa kulttuuri oli sellainen.
Kun ChatGPT:tä opetetaan, niin totta kai se toimii sen mukaan, mitä opetusmateriaalia sisältää. Kerta kyseessä on tilastollinen kielimalli, niin mikäli “mies työskentelee autokaupassa” esiintyy lähdemateriaalissa useammin, kuin “mies työskentelee eläinkaupassa”, niin silloin ChatGPT kertoo miehen työskentelevän autokaupassa. Tuohon voidaan lisätä ihan mitä tahansa sanoja, joten varmaan jos laitetaan miehen, tai naisen, eteen vaikka pitkä, vanha, kalju, tatuoitu, silmälasipäinen, jne., niin ihan samalla tavalla lähdemateriaalista löytyy aina jotain, joka esiintyy muita useammin, ja vastaus tulee siltä pohjalta.
Eli en oikein ymmärrä, että mikä uutisarvo on uutisella, jonka pointtina on se, että tilastollinen kielimalli löytää viitemateriaalista tilastollisia eroja sanojen esiintymistiheyksistä.
Voisikohan tuota tekoälyä käyttää sodan vallitessa jotenkin Venäjää vastaan…hakkeroidaan tv-kanava(t) ja laitetaan Putin omalla naamalla ja äänellään ison pöydän ääreen kertomaan, kuinka Venäläisten olisi nyt parasta nostaa kaikki rahansa pankkiautomaateilta pois, tai tuhota jotkin aineistot/laitteet/muuta? tietyistä paikoista, tai tai tai…jotain näppärää jäynää
Jatkossa saa olla kyllä todella tarkkana, että mitä Biden, Trump, Niinistö, Orpo ja muut ovat oikeasti sanoneet. Vaikka näkisi videon, jossa sanovat selvästi omalla äänellään jotain, niin et voi olla varma onko totta.
Kuvittelen tietäväni suurinpiirtein miten LLM:t toimii, mutta miksi tilastomatemaattinen ratkaisun löytäminen ei olisi ”ymmärtämistä” siinä missä inhimillinen prosessointikin? Pointti: tekoälykin voi ymmärtää asioita väärin siinä missä ihminen.
En ole mikään syväosaaja, mutta olen yrittänyt ymmärtää kielimallien toimintaa, ja jotenkin näin olen sen ymmärtänyt:
Kielimalli “ymmärtää” asioita niiden yhteyksien kautta, kuten ihminenkin, mutta sanoisin että ihmisen ymmärrys voi olla syvällisempääkin. Tavallaan tuota kielimallin ymmärrystä sanojen merkityksistä voisi kai ajatella siten kuin se olisi opetellut ulkoa pinon tietosanakirjoja. On totta, että esimerkiksi koira on eläin ja nisäkäs ja kuuluu biologian luokittelussa johonkin lahkoon ja sukuun jne ja näillä määreillä liittämään koiraan erinäisiä määreitä ja ominaisuuksia, mutta se on aika ohut siivu siitä mitä koira on. Mutta hämmentävän pitkälle tuollakin tiedolla näyttää pärjäävän kun sen yhdistää valtavaan aineistoon sanojen keskinäisistä suhteista kielessä (mikä on sitten se toinen kielimallin osaamisalue).
Voi tietysti olla että näkemystäni vääristää tarve pitää inhimillistä älykkyyttä vähän monimutkaisempana kuin mitä nämä kielimallit ovat
Seuraavan sanan ennustamiseen heikkoudet realisoituivat ikävästi tämän päiväisessä koodaustuokiossa. Tarkoitus oli vaihtaa Pandas kirjasto Polars kirjastoon. Pandas on hiukan hidas isojen datasettien käsittelyssä.
Ajattelin että helppo homma. Heitän Pandas yhteensopivat rutiinit ChatGPT:lle ja saan toimivaa Polars koodia. No en saanut. ChatGPT kyllä tiesi Polarsin olemassa olosta ja osasi generoida melkein toimivaa Polars koodia. Valitettavasti sekaan hallusinoitiin Pandas funktioita ja parametreja.
Sekaannukset ymmärtää kun sekä Polariksessa että Pandaksessa on paljon samojakin rutiineita ja luokkia. Molemmista löytyy mm. Dataframe, mutta se toimii hiukan eri tavalla. Pandaksen käytöstä löytyy ehkä 1000x enemmän opetusesimerkkejä joka lopulta johtaa virheisiin kun koitetaan ennustaa seuraavaa sanaa.
Lopulta pitkän tahimisen jälkeen ChatGPT onnistui tuottamaan toimivaa Polars koodia, mutta se näytti hirveältä ja tässä vaiheessa Polarsin suorituskyky oli samaa luokkaa kuin Pandaksen. Ei auttanut kuin heittää ChatGPTn tekeleet roskiin ja tehdä hommat old school tyyliin lukemalla dokumentaatiota ja kokeilemalla. Edes StackOverflow ei ollut kovin avulias.
Oli muuten raskasta ja hidasta. Tälläistäkö se koodaus ennen olikin? ChatGPTllä homma olisi hoitunut parhaimmillaan muutamassa minuutissa. Nyt meni kolme tuntia. Lopputuloksena onneksi Polars kirjasto antoi 10x nopeutuksen pelkästään datan lukemisessa.
Tuli sama fiilis kun 00-luvulla töissä koodatessa joskus DejaNews oli alhaalla. Silloinhan koodaukseen apuja sai oppikirjoista, Api dokumentaatiosta ja DejaNewsistä. Dejanews oli hakukone NNTP protokollan päälle toimiville foorumeille - aikansa StackOverflow siis. En ole onneksi ikinä työkseni koodannut pelkkien kirjojen avulla.
Kokonaisuutena ehkä pahin epäonnistuminen ChatGPTn kanssa Pythonia koodatessa toistaiseksi.
Pari vastaavaa tapausta tullut itsellekin vastaan (esim. Springfoxin vaihto Springdociin), ja alan uskoa että tämmöinen kirjastosta tai versiosta toiseen migraatio ei ole syystä tai toisesta sellainen asia, johon kannattaa apua ChatGPT:ltä pyytää. Kenties syynä on se, että kielimalli ei kykene erottamaan toisistaan suurelta osin yhdenveroisten asioiden (kuten samaan tarpeeseen tehtyjen softakirjastojen) hienoisia eroavaisuuksia, tai ehkä asioiden versioiminen hämää sitä. Tai samat nimet asioille jotka kuitenkin toimivat vähän eri tavalla, ehkä se ei sovi siihen tapaan miten kielimalli sisäisesti luokittelee asioita linkittäen ominaisuuksia nimeen/nimitykseen.
Tai sitten kyse on ollut vaan siitä, että aiheesta ei ole ollut riittävästi koulutusdataa, koska omallekin kohdalle sattuneissa tapauksissa asian ratkominen perinteisempien (StackOverflow, tekniset blogit yms) on ollut hankalaa tiedon vähäisyyden vuoksi. Ja pitää tietysti muistaa sekin, että ainakin ChatGPT itse edelleen vakuuttaa, ettei tiedä mitään syksyn 2021 jälkeisistä asioista, joten uudehkot kirjastot ja frameworkit (Polars näyttää olevan saaneen alkunsa 2020) ovat sille siksikin varmasti hankalia. Mutta tarvittavan tiedon tuoreus ei kyllä ole ainoa syy itse kohtaamiini ongelmatapauksiin.
(Otsikko kuten yleistä hieman raflaava, mutta juttu hyvä)
Periaatteessa sitä samaa mitä jo on nähty aiheesta “kenties netin sisältöä on käytetty vähän turhan liberaalisti AIn treenaamiseen välittämättä tekijänoikeuksista”, mutta New York Times on sen verran syvät taskut omaava lafka että ongelma saatetaan lopulta testata oikeusistuimissa.
En oikein tiedä mitä tästä pitäisi ajatella - toisaalta ymmärrän tekijänoikeuksien haltijoiden näkökulman: “Olemme tehneet julmetusti laadukasta sisältöä meidän rahoilla ja nyt kaupallinen yritys käyttää tätä sisältöä massana kouluttamaan heidän algoritmiaan. Vähintään tästä pitäisi saada jonkinlaiset provikat, ja lisäksi meidän pitäisi pystyä päättämään sallimmeko tämän.”
No, ainakin NYT on nyt muuttanut käyttöehtojaan jossa he eksplisiittisesti kieltävät sisällön käytön AI-mallien kouluttamiseen.
Loppuen lopuksi kyseessä on tappelu rahasta. AIn ympärillä on isoja rahakasoja ja aina kun yritykset ja heidän lakimiehet haistavat että olisi mahdollisuus saada osa tällaisesta rahavuoresta, paikalle tulllaan käsi ojossa, koska tietenkin tullaan.
Mutta oikeusjutut voivat kestää vuosia ja siinä missä OpenAI kenties pystyy nämä hoitamaan ja jonkinlaiset sopimukset solmimaan, moni pienempi startup voi olla syvässä lirissä jos hienot suunnitelmat kolisevat siihen että valtava osa netin sisällöstä sulkeutuu pois heidän käytöstään koska ei ole resursseja maksaa siitä ja mikäli dataa käytetään ilman lupia, ollaan yhden oikeusjutun päässä siitä että ollaan syvässä lirissä. Kalliilla tuotetusta mallista kun ei voi jälkikäteen “ottaa pois” osaa josta nostettiin oikeusjuttu…
Tämä ongelma voi myös nostaa lisää maksumuureja ja login-ruutuja netin sisällön eteen koska jos sisältösi on vapaasti anonyymisti ryystettävissä alas, joku voi sitä käyttää AI:n kouluttamiseen ilman lupaa.
Sitten tietenkin on vielä se toinen tekijänoikeusongelma - mitä jos yritys käyttää ChatGPT:tä tuottamaan sisältöä, joka on tuotettu mallilla joka myöhemmin todetaan laittomaksi. koska tekijänoikeudet. Tarkoittaako se että kaikki tämän mallin avulla tuotettu sisältö on tämän jälkeen laittomasti tehtyä? Paljonko ChatGPTn tuottamaa tavaraa on pitänyt jälkikäteen muokata ja editoida jotta siitä tulee turvallisesti oma tuotos. Kiinnostavia ongelmia…
Kiireisimmät ovat julistaneet jo tekoälybuumin loppumista, mutta maailman tähänastisen tietoteknistymisen ja digitalisaation merkityksen maailmalle ja yrityksille lähes kokonaisuudessaan nähneenä olen täysin samaa mieltä Norjan öljyrahaston Tangenin kanssa.
Tämä touhu on vasta alussa ja vauhti pysyy kovana. Iso raha on liikenteessä ja investoi, ja sitä liikuttelee Norjan öljyrahaston kaltaiset tahot.
Sijoittajana usko joidenkin yksittäisten osakkeiden nousuun on koko ajan pienellä koetuksella. Sitä ei tahdo millään uskoa, että hurjiin nousuihin tehdään vähintään samanmoinen jatko. Nvidian kohdallakin myin jo ison osan matkan varrella (joka on toisinaan ihan viisasta toki sekin).
Sitä tässä fundeeraan koko ajan, että mahtaako tässä kuitenkin käydä niin, että sentimentin voimalla painetaan kaikki maanosat ja pörssit taantumaan, josta sitten lähdetään takaisin nousuun. Juuri nyt näyttää siltä, että pelkkä AI ei syksyä tule pelastamaan.
Tangen kuvaili, että yritykset, jotka eivät hyödynnä tekoälyä, ovat ”täydellisiä idiootteja”.
Hupaisintahan on että arvaa kaksi kertaa kunnioittavatko Kiinalaiset käyttöehtoja?
Kaikki mikä johtoa pitkin irti lähtee menee Kiinalaisten AI-koulutukseen eikä mitään lisenssejä tai lupia kysellä.
OpenAIn osalta tässä on ensisijaisesti kyse rahasta - kaikki sisältöä omistavat tahot haluavat omansa rahavuorista. Sitten kun OpenAI on “putsattu” joko oikeustuvan kautta tai vedenpitävillä soppareilla niin sisältömafia voi siirtyä niistämään startuppeja kuoliaaksi.
Hit piece ChatGPTstä jonka mukaan palvelu ajotaan ajaa alas. Tästä väitteestä ei näyttöä vaan spekulointia ChatGPTn vaikeuksien pohjalta: Käyttäjämäärä laskussa, liian kallista ajaa, riitaa Microsoftin kanssa (Microsoftin omituinen Azure GPT julkaisu ja pois otto), riitaa oikeudessa, käyttö kielletty monissa firmoissa.
Lisätietoja Microsoft vs OpenAI kärhämästä AzureGPT case
2 kuukautta viestisi jälkeen CodeLLama-34B hakkasi GPT-4 HumanEval -testissä.
Tuommoisen 34B mallin saa pyörimään kvantisoituna esimerkiksi meikäläisen kotikoneella.
Rehellisyyden nimissä on todettava, että GPT-4 vieläkin täysin ylivertainen malli käytännön koodauksessa riippumatta siitä, että mitä testituloksia yksittäisistä testeistä tulee, mutta etumatka kaventuu kuukausi kuukaudelta. Llama-2 malleja on alkanut tulla jakoon ja alustavat tulokset ovat kyllä erityisen lupaavia.
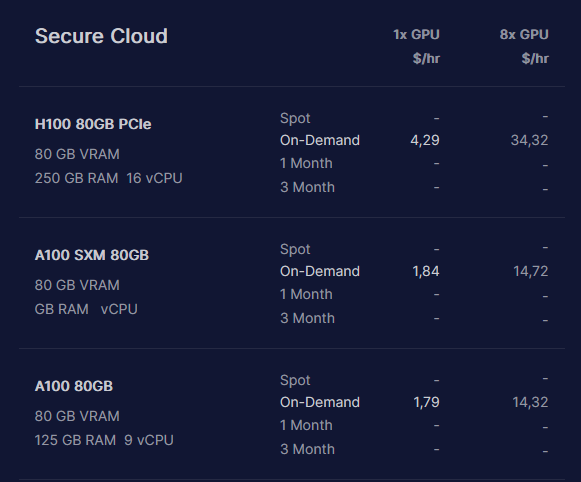
“We employed DeepSpeed ZeRO 3 and Flash Attention 2 to train these models in three hours using 32 A100-80GB GPUs, with a sequence length of 4096 tokens.”
Tarvittiin 96h (3*32) laskentaa 16k$ kortilla. Jos oletetaan että datacenterin tarjoaja hinnoitteleen laskennan siten että kortin hinta tienataan vuodessa niin laskennan hinnaksi tulee 16k$ × 4 / 365 = 175$. Kuulostaa halvalta.
Olet oikeilla jäljillä. Ei tuo heidän käyttämänsä treenaus mitään mahdottomia summia maksa. Phindillä käyttivät tuohon AWS, mutta halvempiakin tarjoajia löytyy netistä:
Eihän siitä montaa viikkoa ole, kun mediassa ennustettiin konkurssia.
Ehkä totuus on jossain “ydinpommitulojen” ja “konkurssin” välimaastossa. Luulisi ainakin yrityksillä olevan kiinnostusta vastajulkaistuun kustomoitavaan yritysversioon. Olen jonkin verran käytellyt suomalaisyritystenkin chatteja viime aikoina ja ovathan ne aika hirveitä, kun on tottunut ChatGPT:n kanssa jutustelemaan. Hirveällä tarkoitan sitä, että Telian botti ei ainakaan ymmärrä edes lyhyitä kysymyksiä vähänkään monimutkaisemmasta asiasta ja vastaa mitä sattuu – eikä se Elisankaan kyllä sen parempi ollut.
Sisukkaasti olen silti yrittänyt botin kanssa ensin jutella, jos jonkun yhtiön webbipalveluja olen käyttänyt. Ehkä sieltä joku päivä vastaakin botti, joka ei aiheuta ajanhukkaa ja turhautumista.
Tätä on useaan kertaan tuotu esiin että chatgpt:n avulla voitaisiin saada nykyiseen verrattuna aivan ylivoimaisia chatbotteja. Olen 95% samaa mieltä. Mutta yrityksillä on tietysti aika kova tarve varmistaa että chatista saa luotettavaa tietoa, en tiedä onko keinoja rajoittaa gpt:n hallunisointeja ja varmistaa ettei se tee vaikka tuotelupauksia jotka eivät pidä lainkaan paikkaansa jne?
Tästä ensimmäistä otsikkoa odotellen… ts. joku pistää asiakspalveluhommin ChatGPT-johdannaisen ja sitten setvitään, mahdollisesti raastuvassa asti, että mitä botti meni lupailemaan kun tarpeeksi kiero ihminen sille sopivia turinoi.
En ole mikään ML Engineer, mutta eikös sen saisi omilla matskuilla opettamalla ja background prompteilla rajoitettua varsin tiukaksi, ettei jää horisemaan aivan mitä sattuu?
Ainakin muistan jonkin esimerkin, että vastaa lähteisiin perustuen tai muutoin tyyliin “I don’t know”.
Esimerkissä kyllä tosin GPT:tä ei opetettu vaan erillistä vektorisoijaa, jota GPT apunaan käytti. Hinta voi tietysti nousta vähän etupeltoon tällaisessa tapauksessa.
Embeddaukseen en ole koskenut lainkaan, mutta voisin kyllä olettaa senkin tekevän samaa asiaa.
EDIT: tietty poistaa juuri sen luovuuden, mutta toisaalta pystyisi puolestaan tulkitsemaan kaikenlaista pyynnöistä sen “pihvin”.