Taitaa ollaa vaan valuuttakauppaan?
Juu niin on. Perimmäinen käyttötarkoitus lienee yritysten järjestelmien ulkomaanmaksuliikenteen hoito.
Gofore esimerkistä näkee aika hyvin miten heikosti keskiarvoihin perustuvat systeemit suoriutuu, kun osake ei ole selvässä nousu- tai laskutrendissä. Sahaavan kurssikehityksen aikana myyntisignaali tulee usein pohjilla. Nopeiden kurssinousujen aikana ei sitten taas tule myyntisignaalia ja voitot jää ottamatta. Tuotto oli 43% kun holdaamalla alusta lähtien olisi tullut n. 200%.
Tämmösessä vertailussa kannattaa tosin huomioida, että varat oli sijoitettuna vain alle puolet koko ajasta. Jos mukana olisi vaikka 10 yhtiötä ja sijoittamista pystyisi muuten rajoittamaan sahaavassa ympäristössä niin lopputulos voisi olla ihan erilainen.
1 tykkäys
Myöhäiset kiitokset tästä.
Tulkitsinko tuota oikein - käsien päällä istuminen olisi ollut parempi strategia (tässä tapauksessa)?
Näin on ainakin tässä, ja helposti useimmissakin tapauksissa. Kuten @Ripelein yllä sanoo, sahaava tai liian jyrkät liikkeet helposti vievät hyödyn.
MACD-strategioita on muuten ääretön joukko, ensinnäkin itse EMA ja signaalin jaksoa voi muuttaa, ja sitten vielä signaalistrategiaakin kaiketi. En ole perehtynyt MACD:hen sen enempää.
Ehkä voi parametreja optimoida niin, että saa tällä tavalla backtestissä jonkun osakkeen suoritutumaan tasaisesti ja hyvin. Eriasia sitten, että toimiiko se tulevaisuudessa.
Kiitos git repo esimerkistä Kelpieracer. Kokeilin tuota ja sain toimimaan python3:lla mac os:ssä.
Backtrader tuntuu sopivalta ympäristöltä algokokeiluihin. Olenkin etsinyt tällaista ympäristöä, jossa pääsee itse asiaan eli algoritmien tunaamiseen sen sijasta että keskittyy graafisen tuloksen luomiseen. Tämä on hyvä pohja siihen, varsinkin kun tuo hakee Yahoo Financesta datat suoraan.
Toki huomasin että esim. TELIA1.HE:n data oli tuota kautta väärin, vaikka se heidän webbisivulla on oikein. Eli kannattaa aina tarkistaa että data on kunnossa. En keksinyt syytä tähän…
Miten muuten noita parametreja voi syöttää? Kokeilin netissä olleista ohjeista, mutta tässä lienee joku oma menetelmä syöttää niitä sisään.
# list of parameters which are configurable for the strategy
# params = dict(
# psignal=9, # EMA signal
# pfast=12, # period for the fast moving average
# pslow=26 # period for the slow moving average
# )
1 tykkäys
Oon hakenut kurssitiedot alla olevalla tavalla ja huomannut myös ettei tiedot ole oikein. Eilisen päivän tiedot tarkistamista varten on ollut pari kertaa hukassa, mutta alkanut sitten löytymään jossakin vaiheessa. Ehkä olisi vaan parempi lisätä uudet tiedot tarkastamatta. Toinen vaihtoehto vois olla hakea tiedot tallentamalla tuolta kurssitiedot Historialliset kurssitiedot - osakkeet - Nasdaq (nasdaqomxnordic.com). Mikähän olis helpoin tapa valita tuolta yhtiö, päivät ja ladata csv-tiedosto?
import pandas_datareader as pdr
import datetime as date
print(pdr.get_data_yahoo(‘UPM.HE’, date.datetime(2021,3,12),date.datetime.today()))
2 tykkäystä
Naputin pari vuotta sitten Yahoolle tuosta TELIA1.HE:stä, mutta naureskelin jo silloin, että kiinnostaako ketään senttiäkään. Hitaampaa kuin Nordnetin asiakaspalvelu ![]()
Ota siis Telia kruunuina TELIA.ST
Pohjoismaisia Yahoo-tickereitä löydät muuten tuossa samassa repossa olevasta symbol_dict.py -filusta. Siinä on tickereitä, joilla voi Nordnet Marketsissa treidailla.
NDA-FI.HE pitäisi kyllä vaihtaa Tukholmalaiseen sekin, kun suurin osa Nordean futuista on ST.
Noksurenkaat oli kanssa pitkään mahdoton, kun Yahoo vaihtoi tikkeriä. TYRES.HE on nyttemmin kuitenkin korjattu.
params = (
# Standard MACD Parameters
('macd1', 12), # standard 12
('macd2', 26), # standard 26
('macdsig', 9), # standard 9
)
def __init__(self):
m = bt.ind.MACD(self.data,
period_me1=self.params.macd1,
period_me2=self.params.macd2,
period_signal=self.params.macdsig)
Tälleen voi ottaa noita parametrejä käyttöön käsittääkseni, ainakin lopputulos muuttuu.
Yahoon datassa on se etu Nasdaqiin verrattuna, että sieltä löytyy valmiiksi laskettu adjclose, joka ottaa tuotoissa huomioon myös osingot ja splitit. Toki sitten data on epävarmempaa muuten.
Edit. Tuo Nasdaq-datan api vaikuttaa sellaiselta, että suoraviivaisin vaihtoehto automaattiseen datan lataamiseen voi olla Pyppeteer, tosin Nasdaqin javascript näyttää olevan ihan selkokielistä, että sitä vois ehkä reverse-engineeratakin.
1 tykkäys
Ja tällä haen “tuotantodataan” kurssi-infot. Olen ollut tyytyväinen toiminnan luotettavuuteen.
from yahoo_fin import stock_info as si
df = si.get_data("UPM.HE")
Palauttaa siis pandas dataframen.
1 tykkäys
Huonoja uutisia sp500-firmojen osakkeilla pelkkää kurssidataa käyttäville LSTM-algoholisteille:
Based on statistical analysis alone, we have strong evidence to conclude that stock market prices follow a random walk. There is, therefore, no sequential dependence or learnable structure to be found in the data. Thus, we prove the weak market hypothesis to be true.
1 tykkäys
…any previous stock price, trend, or information can not be used to predict future movement
no form of technical analysis on past asset prices or trends can be effectively utilized to aid investors in making trading decisions.
Vaikka pörssikurssit liikkuvatkin yksittäisinä ajanhetkinä täysin sattumanvaraisesti, intuitio tahtoo allekirjoittaneella sanoa, että kenties jokin puhtaasti hintatietoon pohjautuva malli voisi kuitenkin olla tikkaa heittävää apinaa onnekkaampi (etenkin, jos soppaan saa sotkea mukaan myös volyymit). Nyt en puhu siis HFT-/päiväkaupasta vaan ehkäpä ennemminkin isosta kuvasta. Varsin maaginen vaikutus tuntuu vielä tänäkin päivänä olevan esimerkiksi tasaluvuilla, vaikka valtaosan kaupasta käyvätkin tunteettomat algoritmit.
Sitä en tiedä, osuuko MACD:t, RSI:t, Fibbonaccit, tai support- ja resistance-tasot maaliin apinaa tarkemmin, mutta heittäisin ilmoille hypoteesin, että olisi esimerkiksi kannattavampaa ostaa ylimyytyä kuin yliostettua osaketta. Jos Telian osake on sahannut edellisen vuoden pari 3.5-4.0 euron välimaastossa, olisiko kokeilemisen arvoista ostaa lähtökohtaisesti 3.7:sta ja myydä neljän päällä, jollei mitään merkittäviä uutisia ole tarjolla? Random walkiahan ei voi nimensä mukaisesti ennustaa, mutta olisiko Telian tapauksessa tietty käyttäytyminen todennäköisempää (sahaaminen ees taas supportin ja resistancen välillä) kuin jokin toinen skenaario (odottamaton heilahdus suuntaan tai toiseen ilman merkittäviä uutisia)? Jos näin on, eikö tässä olisi mahdollisuus tienata (ja myöhemmin hävitä/voittaa isosti, kun jokin odottamaton tapahtuma realisoituu)?
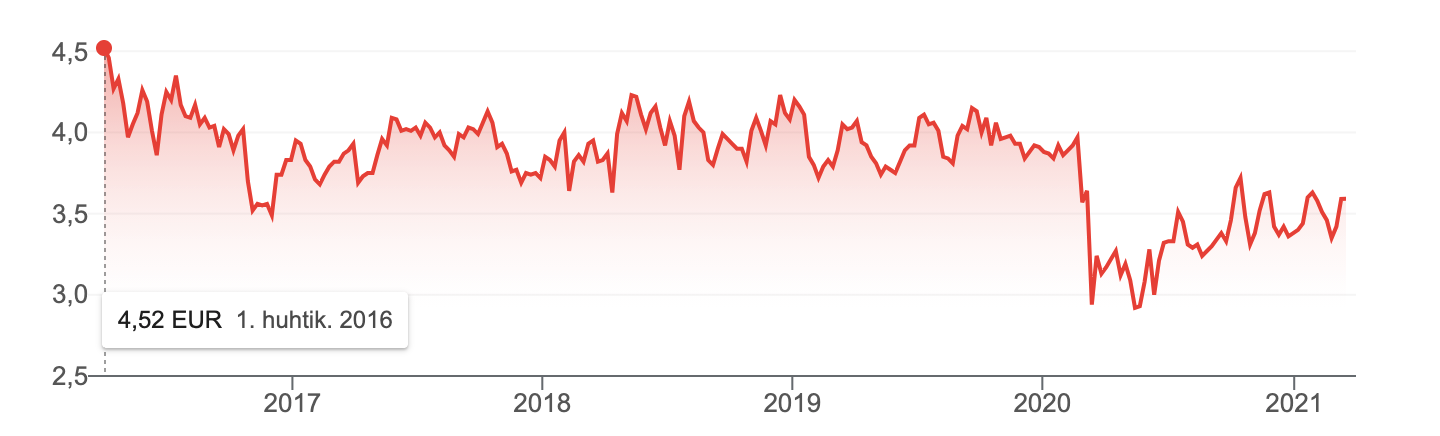
Kun katsoo vaikkapa Cityconin piirtämää kuolleen miehen käyrää tai Revenion vuosikymmenen jatkuvaa nousua, olisiko sellaisella hypoteesilla mitään pohjaa, että kurssilla on tapana jatkaa siihen suuntaan, johon se on aiemminkin liikkunut? Ei varmaan päde kaikkialla, ja homma taitaa levähtää reisille jos ja kun yllättäviä (yritykseen tai markkinaan kohdistuvia) uutisia ilmaantuu, joten mitään käryä ei ole, voisiko tiettyjen osakkeiden kohdalla LSTM tai vastaava malli ottaa jonkinasteista koppia kurssin todennäköisestä käyttäytymisestä?
Tämähän on sikäli mielenkiintoinen teema kokonaisuudessaan, kun ottaa huomioon, kuinka ihmisellä on tapana nähdä patterneja siellä, missä niitä ei todellisuudessa ole, ja miten haastavaa onkaan hahmottaa satunnaisen liikkeen satunnaisuus ja mahdoton ennustettavuus. Puhumattakaan klassisesta survivorship biasista teknisten treidaajien suhteen - jonkunhan se on miljoonista treidaajista onnistuttava jo ihan todennäköisyyksien puolesta.
Se lienee totta, että ML-pohjainen treidaaminen on äärimmäisen haastavaa, jollei piensijoittajan resurssein mahdotonta. Mielelläni kuitenkin testailen, jahka kerkiän, voisiko esimerkiksi LSTM oppia nappaamaan kiinni moving average crossovereista tai muista tyypillisistä TA-signaaleista, josko niistä saisi vaikkapa pientä tukea ajoittamiseen. Taannoin pyöräytin ihan perus klusteroinnilla varsin näppärästi toimivan support- ja resistance-tasojen automaattisen tunnistajan. Varsin näppärä leikkikalu.
Yleisellä tasolla itselläni on uskoa eniten muun datan hyödyntämiseen sijoittamisen tukena. Varsin hyvin on tuntunut toimivan vanha lausahdus, että veren virratessa kadulla on oikea aika ostaa. Tullut myös huomattua, että mitä innokkaammin kauppaa haluaa tehdä, sitä kuumempi ja vaarallisempi markkina tuntuu usein olevan. Kenties näitä tekijöitä olisi tunnistettavissa ihan sentimenttien, somen tai uutisoinnin puolesta. Luin juuri muutaman tutkimuksen, jossa seurattiin Wikipedia-artikkeleiden näyttökertoja, ja toisen jossa crawlattiin Googlen tarjoamia kohteiden popular visiting timeseja. Paljon on siis edelleen olemassa hyvin heikosti hyödynnettyjä datalähteitä perus Twittereiden ja Google Trendsien ulkopuolella.
Käynytkin mielessä, josko Inderesin foorumia saisi varovaisesti crawlailtua, jos vaikkapa kurkkaisi, millaista parviälyä täältä löytyy, tai josko osto- ja myyntiketjusta olisi tunnistettavissa markkinoiden tilaa.
1 tykkäys
Artikkelissa pakotettiin data stationääriseksi tekemällä difference transform raakadatalle, tuota ei välttämättä kannata tehdä LSTM:lle, vaan normalisoinnin voi tehdä myös muilla kesymmillä tavoilla. Datasetin muuntaminen stationääriseksi ennustuksen ajaksi, ja sen jälkeen palauttaminen takaisin rajaa ison osan informaatiosta ulkopuolelle. Tuossa on aika iso törmäys perinteisen tilastotieteen kanssa, joka olettaa nuo vakio varianssin ja keskiarvon, ja neuroverkkojen välillä jotka pystyy hyödyntämään noita kun dataa on riittävästi. Lisäksi keskityttiin pelkästään päätöshintoihin, eikä esimerkiksi päivän sisäisen kurssin ennustamiseen.
Jos se olisikin noin helppoa todeta, että random walk, no can do niin koneoppiminen olisi huomattavasti helpompaa. Käytäntö kuitenkin pakottaa yritykseen ja erehdykseen, kun etukäteen ei voi tietää parin tilastollisen suureen perusteella, että onnistuuko.
5 tykkäystä
Tuota minäkin kokeilin silmät kiinni, kaadoin ison kasan yleisimpiä TA-signaaleja, mukana ohlcav -hintatiedot. En ehkä osannut rakentaa neuroverkkojen layer stackia järkevästi, koska sain pelkällä hintatiedolla parempaa tulosta.
Klusterointiin en itse ole syvällisesti perehtynyt, olisi mielenkiintoista jo senkin vuoksi, että tuo voisi säästää gpu-aikaa, mikä maksaa.
Tämä itsellänikin käynyt mielessä, varmaan tulee jossain kohtaa jotain viriteltyä ![]()
1 tykkäys
Täällä sitten taas mielipidettä/kokemusta toiseen suuntaan, ja hyvä muistilista.
Assume the markets are rigged, learn the rules, and play by them, but don’t deny them by thinking markets act naturally.
Elikkäs voisiko olla niin, että SP500:t ja muut isot alkaa olla jo hyvin randomia, mutta pienemmillä firmoilla ja pörsseillä olisi ML-algoilla enemmän saumaa.
Nyt olisi tähän faktaakin kerättynä edelliseltä kahdelta viikolta, 250000 hintatiedon verran. Tässä spreadit kellonajan ja viikonpäivän funktiona.

Kirjoittelin asiasta lisää blogitekstin muodossa, ja datatkin löytyy sieltä.
7 tykkäystä
Tekeekö täällä joku muuten backtestausta tai jopa automatisoitua kaupankäyntiä TVn pine skripteillä?
Valitettavasti kokemusta on vain Pythonista ja C#:sta. Miksikähän TV:n on pitänyt ihan oma ohjelmointikieli keksiä ![]()
TV:n API:sta on näköjään Python-kirjastojakin.
Mitä tuotteita ja missä pörsseissä TV:llä voi treidata? Onko sulla kustannuksista käsitystä, @Seinakadun_Keisari ?
Edit. Jaa voikohan tuolla oikeasti treidata vaiko backtestata ja analysoida vaan? ![]()
1 tykkäys
TVn voi yhdistää moneen brokeriin mutta esim. ibkr on vasta tuloillaan, TV itsessään ei siis ole välittäjä. Ulkomailla monet käyttää TVn skriptejä strategian tekemiseen joista muodostuu buy/sell alertteja jotka webhookien avulla menee toimeksiannoiksi brokerille.
Eli se mitä tuotteita voi treidata riippuu brokerista. Samaten kustannukset mutta ne tyypillisesti on todella alhaisia vrt. Suomi-välittäjät
Tuo pineskripti on todella yksinkertaista/helppoa vrt python, varmasti rajoittuneempikin mutta onhan tuolla rakennettu ties mitä virityksiä
2 tykkäystä
Metsäboardin tuotto on vastannut hyvin ennustetta. Osinko ja pääoman palautus on lisätty osakekurssin päälle, koska ne sisältyvät myös ennusteeseen. Pääsiäisen arkipyhät muuttivat vähän päivämääriä. Viimeisin toteutunut piste määräytyy lopullisesti 21.4.

1 tykkäys
Tuli luettua kirja Building Winning Algorithmic Trading Systems: A Trader’s Journey From Data Mining to Monte Carlo Simulation to Live Trading, + Website | Wiley, joka oli aika mukavaa luettavaa. Kirjassa keskityttiin aika paljon algosijoittamisen ongelmista.
Kiinnostavinta oli keskimääräisetn tuottojen ja niiden keskihajontojen hyödyntäminen arvioinnissa lyhyellä aiavälillä. Omien tietojen perusteella tuoton pitäisi olla satunnaisena ajankohtana alla olevan mukainen. Vaaka-akselilla on kaupankäyntipäivät ja pystyakselilla tuotto. Ala- ja yläraja ovat yhden keskihajonnan päässä keskiarvosta.
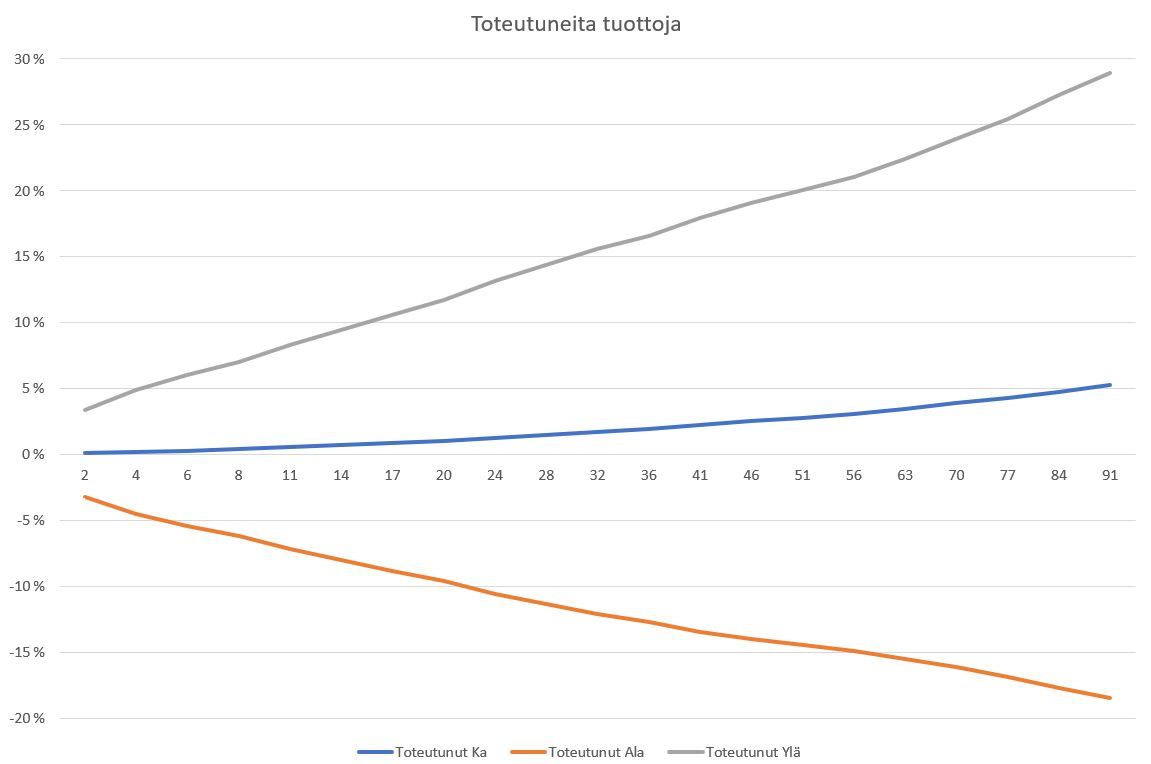
Ylläolevaan voidaan lisätä historiallisen testauksen mukaiset tulokset. Voidaan nähdä, että sijoitusstrategian keskimääräinen tuotto on korkeampi kuin kaikkien toteutuneiden tuottojen. Alaraja on selvästi siirtynyt ylöspäin eli tappioita on pystytty välttämään.

Kun edelleen tarkastellaan lähihistoriaa(vain esimerkki) niin nähdään tuottojen olevan ylärajan tuntumassa. Sijoitustrategia on myös tuottanut vähän paremmin kuin tasahajautus.
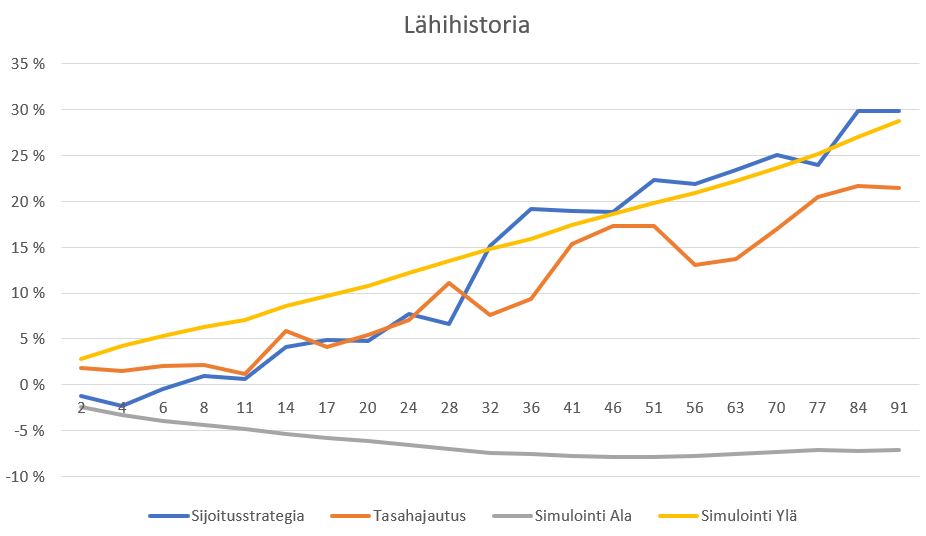
Tämän jälkeen voidaan edelleen tarkastella yhtiökohtaisesti ennusteita ja tuottoja edellisen viestin tietoja mukaillen.
1 tykkäys