Kaikki tietää Blumman terminaalit. Nyt on ilmeisesti tullut Open Source version: https://openbb.co/
ping @Verneri_Pulkkinen - säästäkää penninne.
Kaikki tietää Blumman terminaalit. Nyt on ilmeisesti tullut Open Source version: https://openbb.co/
ping @Verneri_Pulkkinen - säästäkää penninne.
Blummassahan ei ole sovelluksena ihan hirveästi mitään erityistä. Kaikki ne pricerit ja muut työkalut saa myös opensource toteutuksena esimerkiksi quantlibin kautta. Blommassa (ja Eikonissa) maksaa se data jota ei oikein muualta saa sen halvemmalla ja se kaikki on yhdessä paikassa. Bloombergin koko bisnesmalli on se että myyvät dataa jota ei helposti saa mistään muualta ja Blommalla se on vielä valmiiksi pureskeltua ja siivottua. Tuossakin näyttää olevan lähinnä kryptodataa nopealla selailulla joka on muutenkin normaalia markkinadataa helpommin saatavilla. Tuskimpa edes murto-osaa siitä mitä blommalta löytyy.
Ketjun lukeneena nyt on vähän sellainen olo että tulen mopolla radalle missä muut ajavat kiihdytysautoilla mutta onko kenelläkään kokemuksia Capitalise.ai koodausvapaasta treidirobotista?
Tuolla kirjoitellaan siis ihan sanoilla mitä halutaan robotin tekevän ja on mahdollisuus ajallisesti rajalliseen back testaukseen (max 3kk). Robon voi laittaa toki myös simuloimaan reaaliajassa ja lopulta tekemään kauppaa oikealla rahalla.
Aika uusi palvelu joten vielä hieman kehitysvaiheessa mutta vaikuttaa lupaavalta ainakin sellaisille henkilöille jotka ei osaa koodata. Tiettyjä puutteita siis löytyy ja toiminnallisuudet osin rajallisia mutta homma kehittyy pikkuhiljaa, ja puutteita pystyy kätevästi kiertämään Tradingview kautta webhookeilla. Minkä tahansa alertin TV:stä voi heittää capitalise.ai palveluun triggeriksi. Asiakaspalvelukin vastaa eri foorumeiden kautta aika nopsaan ja auttaa ongelmissa.
Palvelu on ainakin IBKR kautta ilmainen, joten jos vähääkään kiinnostaa niin helppo kokeilla. Mielenkiintoisena seikkana mm. se, että pystyy käyttämään myös uutisia ja/tai kaikenlaisia yhtiötiedotteita triggereinä, esim. tällainen sanallinen entry on mahdollista tehdä: “If the Unemployment Claims (US) figures are below forecast and the SPX daily change crosses below -1% sell 10K SPDV”
Tässä langassa ei ole hetkeen ollut pöhinää ja nautin itse ainakin tämän lukemisesta, joten ehkä voisin itse jotain kontribuoida niin josko elämä palaisi lankaan.
Olen pelaillut viimeaikoina jonkin verran Copuloiden kanssa. Copulahan on siis moniulotteinen jakaumafunktio, jonka marginaaliset distribuutiot ovat tasajakautuneita. Sellaisenaan ei kuulosta kovin mielenmiintoiselta, mutta nk. Sklarin teoreema osoittaa että minkä tahansa moniulotteisen jakauman voi esittää copula-funktion ja jakauman marginaalien avulla. Mikä tekee tästä erittäin hyödyllistä on se, että copulat mahdollistavat täten sen että moniuloitteisia ilmiöitä voidaan mallintaa monesti helpommin copulan kautta sillä se mahdollistaa marginaalien ja riippuvuusrakenteen erillisen mallintamisen.
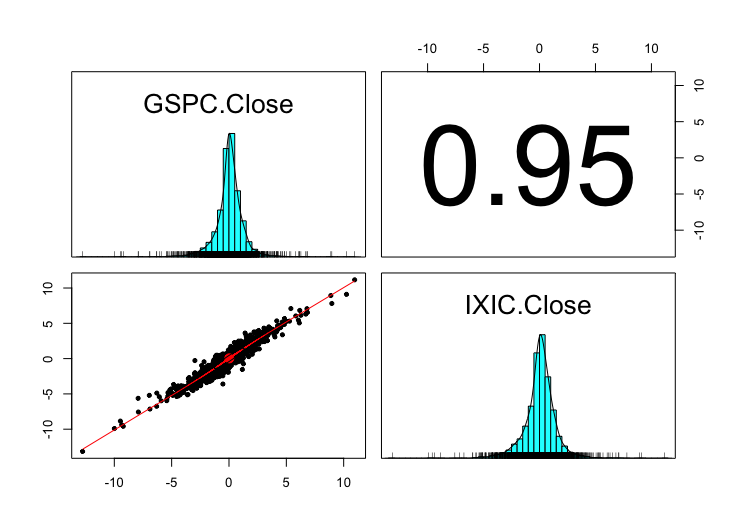
Jos katsotaan vaikka Nasdaq ja SP500 indeksien yhteisjakaumaa esimerkkinä.
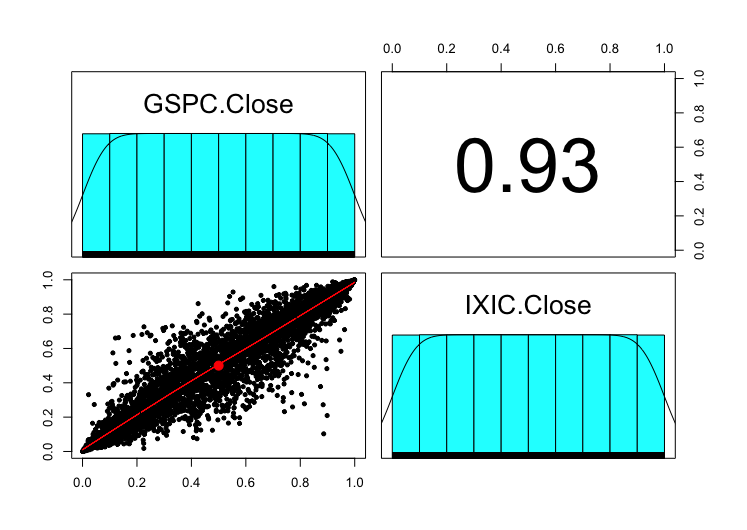
Copulalla on siis helppo mallintaa esimerkiksi juuri monen assetin arvon yhteisjakaumaa, tai assettien riippuvuussuhdetta. Monesti riippuvuutta yritetään mallintaa korrelaatiolla, mutta on helppo nähdä missä tämä menee pieleen.
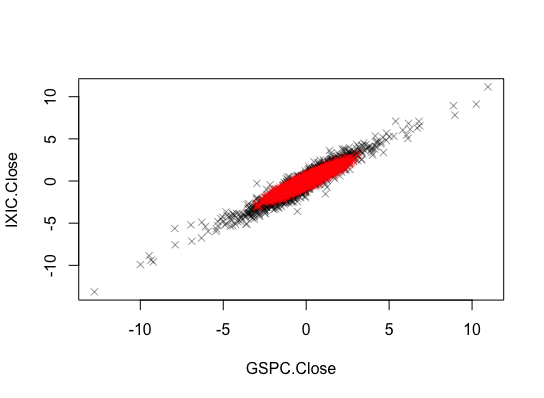
Kuvassa mustalla on taas SP500 ja Nasdaq indeksit ja punaisella on vastaavalla 0.95 korrelaatiolla simuloitu Gaussinen copula Gaussisilla marginaleilla. Korrelaatiot ovat samat, mutta riippuvuusrakenne ei selkeästi ole. Indeksien aikasarjoissa on selkeää häntäriippuvuutta jota ei Gaussisen copulan riippuvuusrakenne pysty nappaamaan. Nämä ei välttämättä ole kaikista paras esimerkki sillä riippuvuus on äärimmäisen positiivinen kuten olettaa voi kahden indeksin välillä, mutta tuottavat helposti koodattavan esimerkin.
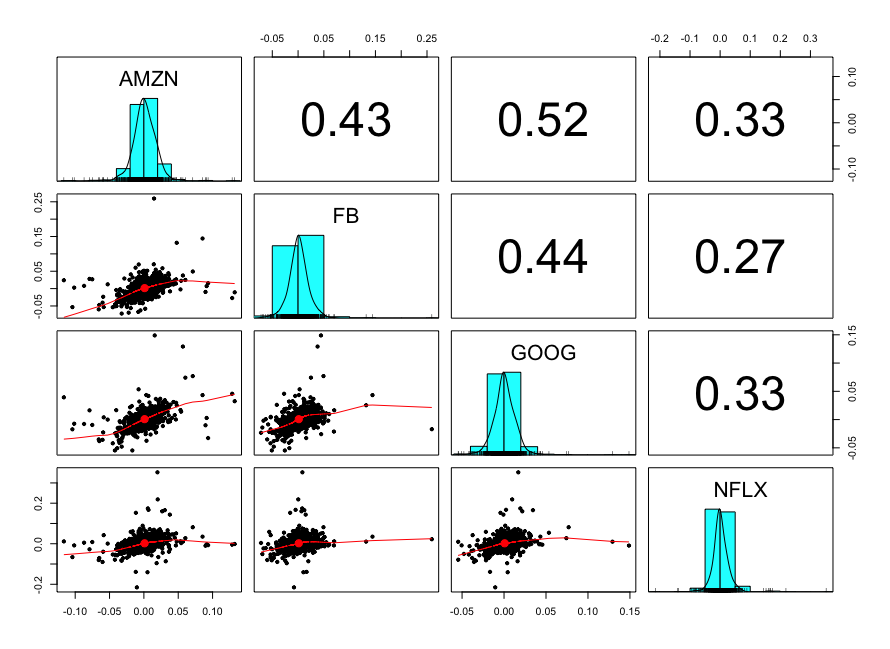
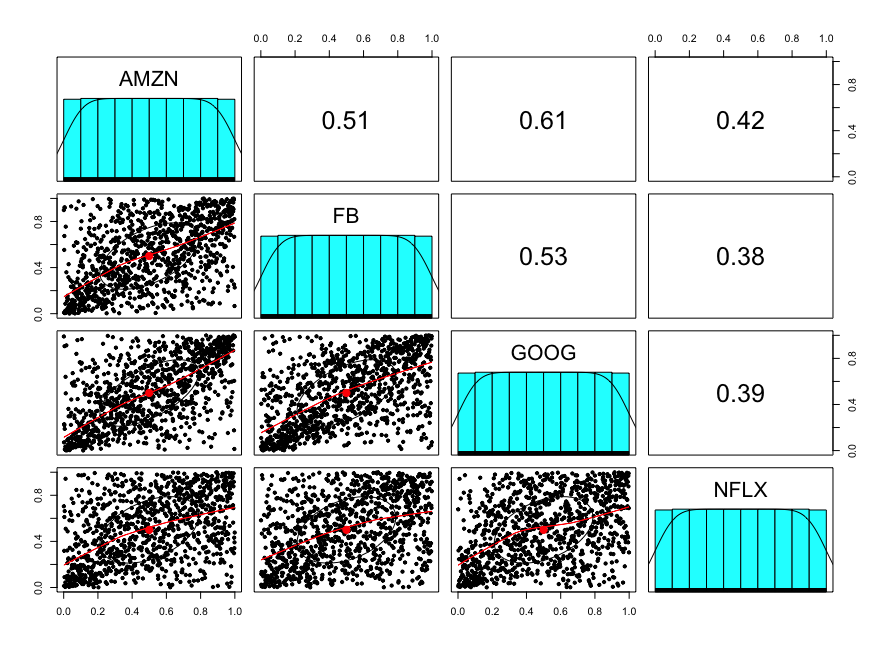
Tässä vielä esimerkin vuoksi FANG datalle samanlaista viritelmää.
Tiedä sitten mikä tämänkin viestin kontribuutio oli.
Mutta vastataan nyt kunnolla silti. Selittämälläni tasolla ei kovin hienoa tietenkään. Viestini tarkoitus oli lähinnä selostaa jotain hyödyllisestä työkalusta joka ei välttämättä ole ihmisille tuttu ja samalla nostaa ketjua pinnalle taas sillä tätä on ollut mukava lukea ja sääli että keskustelu loppunut. Niinkuin alussa sanoinkin, toivon langan uudelleen heräämistä kun sitä välillä vähän nostaa ![]()
Jos kommenttisi taas oli että mitä merkitystä Copuloilla on ylipäätään, niin se kertoo sitten enemmän sinusta. Copulat ovat käytännössä modernin kvantitatiivisen rahoituksen kulmakivi. Ne löytyy käytöstä aina BIS:n vakavaraisuuskaavoista CDSien ja muiden strukturoitujen sijoitustuotteiden hinnoitteluun. Relevantimmin itse langan aiheeseen, Copulat ovat myös kvantitatiivisten sijoitus strategioiden kulmakivi, ja monesti statistista arbitaasia harjoittavat kvanttirahastot perustavat strategiansa juurikin Copuloihin.
Tässä muutamia artikkeleita.
Cointegraation mallinnusta
https://journals.sagepub.com/doi/full/10.1177/0008068319838146
Volatiliteetti riippuvuuden mallinnuksesta
StatArb sovellus (tosin julkaistut parametrit tuskin tosielämässä toimii mutta selostaa hyvin prosessia)
https://www.tandfonline.com/doi/full/10.1080/14697688.2018.1438642
Pair tradingia (sama huomatus julkaistusta mallista pätee tähän)
Lisäksi sanon myös anekdoottina, että eräs tuttuni on töissä eurooppalaisessa kvanttirahastossa ja keskustelumme perusteella heillä on käytössä copuloihin pohjautuva strategia.
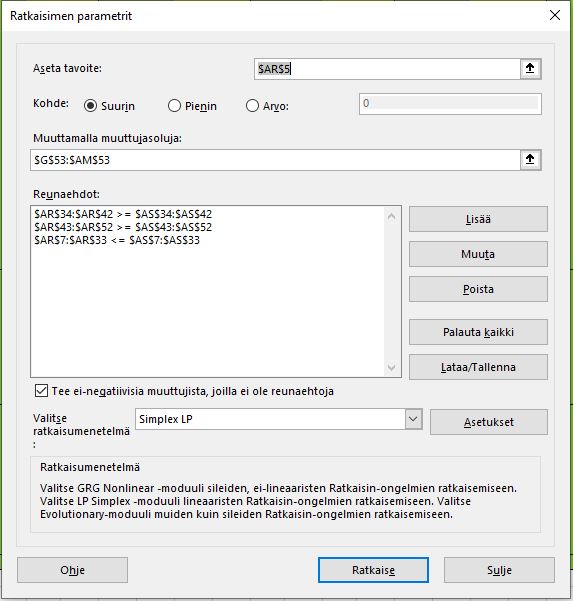
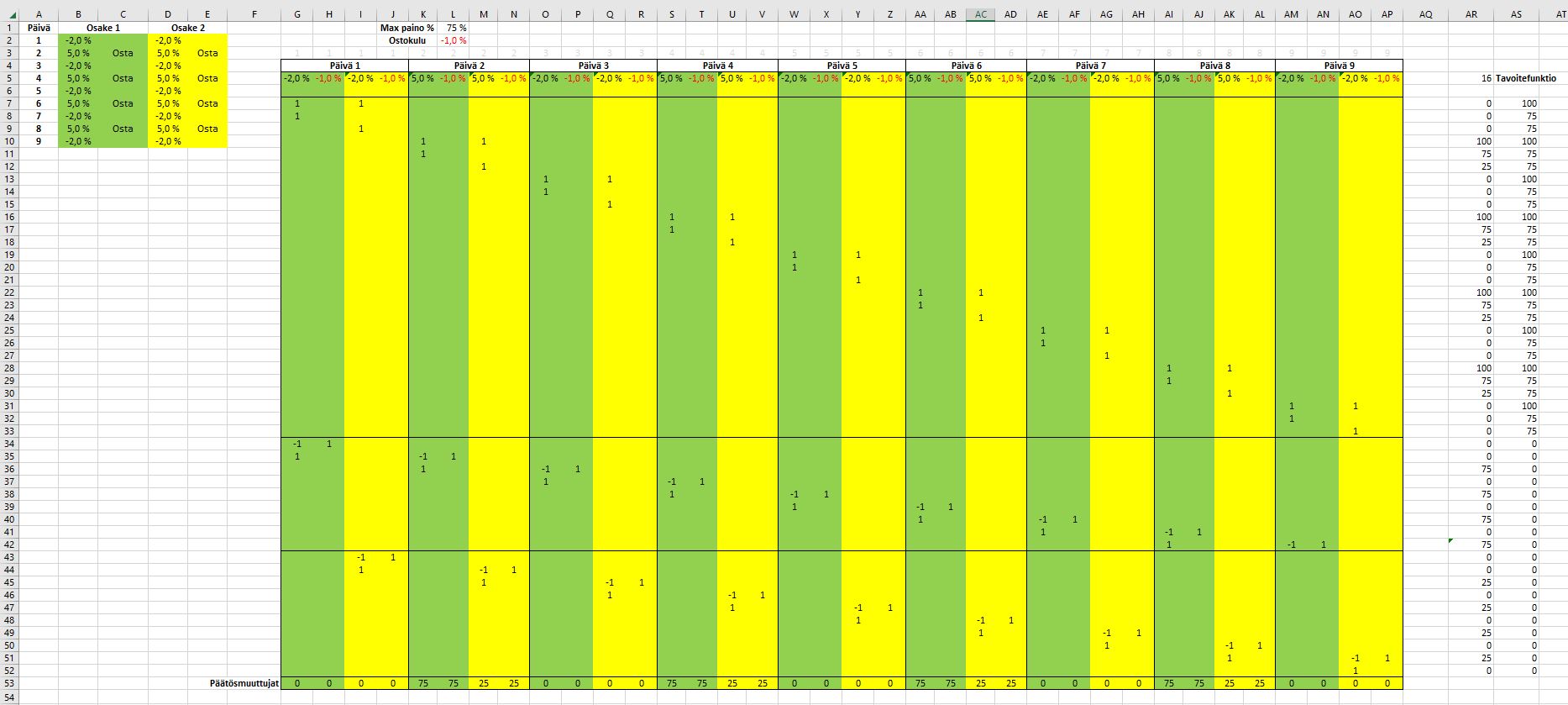
Alkaa taas olemaan opiskelujen jälkeen enemmän aikaa keskityä sijoittamiseen. Aika paljon tullut väännettyä viime aikoina Lineaarisen ohjelmoinnin kanssa ja miksipä sitä ei koittaisi soveltaa myös sijoittamiseen. Kokeilen tässä ensin pientä Excel ratkaisua niin pääsee vähän kärryille. Tässä optimoidaan portfolion tuottoa, kun 2 osakkeeen tuotot on estimoitu seuraavalle yhdeksälle päivälle. Molempien osakkeiden tuotot on nyt samat ja vuopäivinä tuotot on +5% ja -2%. Osakkeen maksimipaino on 75% ja ostoon kohdistuu ensimmäisessä ratkaisussa 1% kulu. Tuoton ja ostoajankohdat pienemmässä taulukossa. Isommassa taulukossa itse malli, jonka yläreunassa osakkeiden tuotot ja kulut kaupankäynnistä. Riveiltä 7-35 löytyy rajoitteet päiväkohtaisesti, jossa portfolion koko on 100 ja maksimipaino 75. Kahdessa pienemmässä alueessa määritelty kaupankäyntiin liittyvän kulun toteutuminen. Alareunassa päätösmuuttujat kertoo sijoituksen päivittäisen osuuden portfoliosta.
Ratkaisimen parametrin määritetty näin
Ensimmäisessä ratkaisussa ostot toteutuisi joka toinen päivä.
Toisessa ratkaisussa kaupankäynnin kulut on -3%, jolloin ratkaisu muuttuu. Nyt kannattaa ottaa mieluummin markkinoilta -2% ja tehdä vähän kauppaa. Osakkeet ostetaan toisena päivänä ja myydään yhdeksäntenä päivänä.
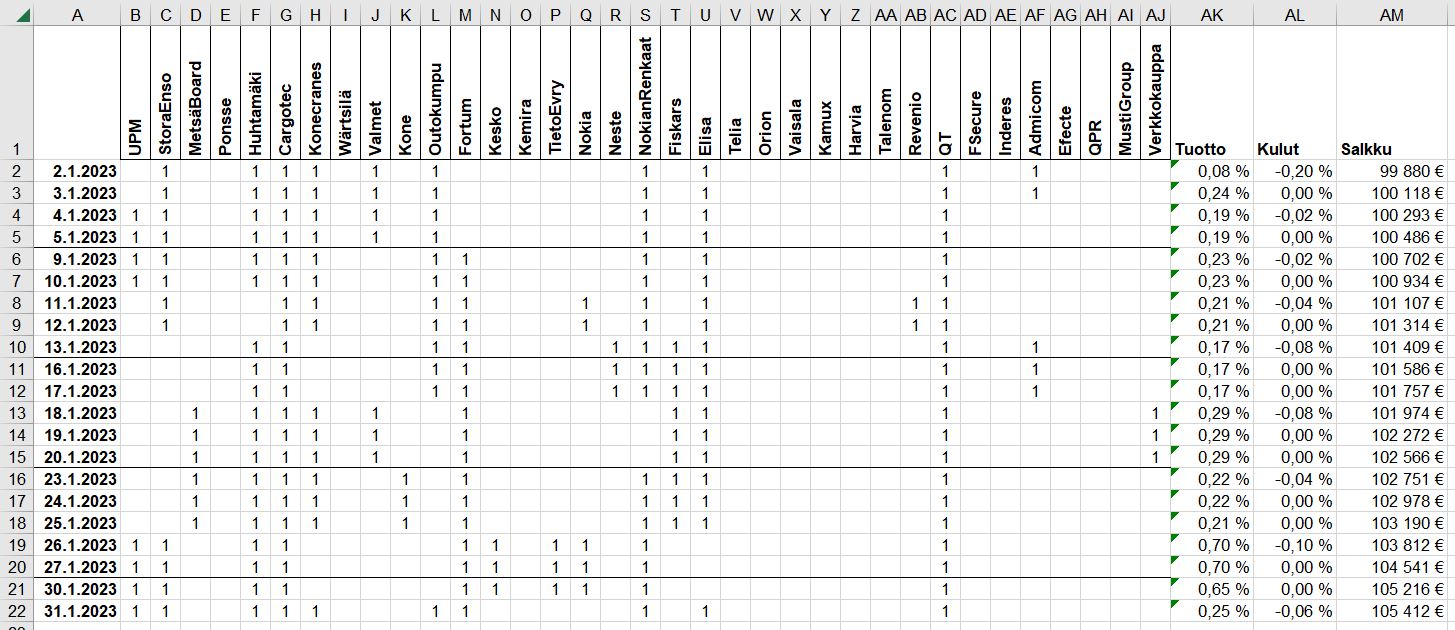
Jatkoa edelliseen viestiin todellisemmalla tilanteella. Toteutus Pythonilla ja viimeistely Excelissä. Otin joulukuun viimisen päivän ennusteet ja optimoin salkun niiden ja 0,2% kaupankäyntikuluilla. Maksimipaino yksittäiselle osakkeelle on 10%, eli käytännössä tarkoittaa tasahajautusta.
Ei sitte kannata tän perusteella sijoitella ![]()
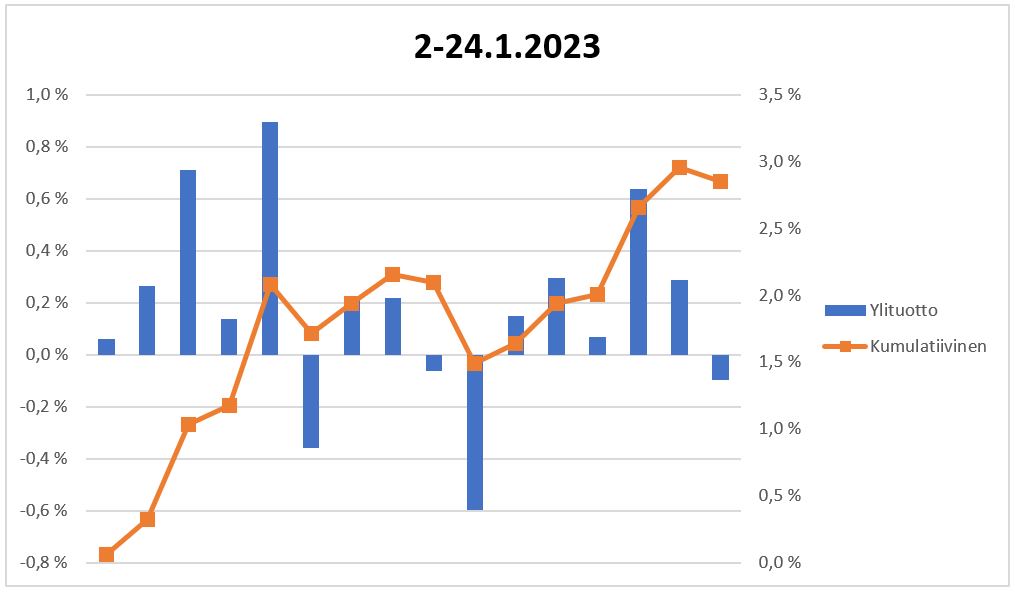
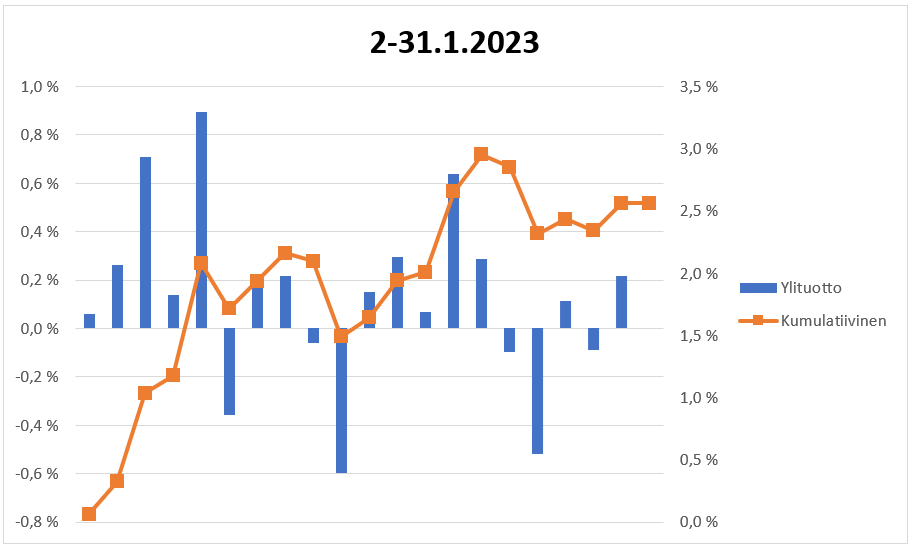
Yllättävän hyvin osunut noi tammikuun yhtiövalinnat tähän mennessä. Vasemman reunan tuotot päivittäiselle ylituotolle ja oikeanpuoleinen kumulatiiviselle ylituotolle.
Loppu kuukausi olikin sitten vähän heikompi, mutta ylituottoa kuukaudelta silti 2,56%. Viimisen päivän kurssitietojen haussa tapahtu jotain erikoista eikä oikeita tuottoja ole nyt mukana.
Meni sen verran kivasti, että kokeillaan uudestaan, mutta ainoastaan viidellä yhtiöllä. Usein tämmönen pienempi määrä yhtiöitä on toiminut vähän paremmin. Fiskars tuntuu erityisesti miellyttävän algoritmia.
Kysytään pitkästä aikaa tältä ketjulta mielipidettä. Vastaus saattaa löytyä vanhoista keskusteluista, mutta ehkä viimeisen vuoden aikana on kuitenkin saatu uuttakin tietoa josta tänne ei ole kirjoiteltu.
Eli pitäisi saada seuraavaa historiadataa markkinoista. Tällä hetkellä livedata ei ole tarpeen, koska haluan vain käsitellä dataa ja opetella/testailla sen avulla eri teorioita.
Alphavantage on useasti mainittu, onko tämä edelleen se paras ylläolevan datan hakemiseen? Löytyykö kryptopörsseistä edelleen data helpommin (periaatteessa ei väliä mikä on kohde, koska teorioita tässä vaan testataan). Onko kellään ollut hyviä kokemuksia Nordnetin APIn käytöstä?
Kahlailen ketjua vielä ajatuksella läpi, uusia kysymyksiä/kommentteja varmasti tulossa.
Kiitti
Reilu vuosi vierähtänyt edellisestä viestistä tässä ketjussa kiireiden takia. Nyt vähän uutta projektia testiin, joka on ollut jo jonkin aikaa mielessä. Aineistossa kokonaisuudessaan ladattu yfinance:n avulla. Tällä hetkellä aineistossa 3,24 miljoonaa päivittäistä kurssitietoa.
Tarkoituksena esimerkissä on etsiä aineistosta Telian kurssikäyrää lähellä olevat havainnot, joista tarkastellaan toistaiseksi joka toista päivää. Näitä on kuvattu punaisella ja vihreällä viivalla, jotka ovat yhden keskihajonnan päässä keskiarvosta.
Musta pystyviiva kuvaa tätä hetkeä. Vasen puoli mennyttä 149 kaupankäyntipäivää ja oikea puoli seuraavia 49 kaupankäyntipäivää. Sininen viiva kuvaa toteutunutta kurssia tai ennustetun kurssikehityksen keskiarvoa. Ennuste näyttäisi tässä tapauksessa aluksi aika neutraalilta ja nousevan loppua kohden lievästi.
Alla vanhin vastaava kurssi kehitys, jonka kurssia kerroin vastaamaan Telian kurssitasoa. Silmämääräisestikin vastaa aika hyvin kurssikehitystä.
Täällä saattaisi olla kiinnostusta tätä Hudson et Thames juuri open sourcettua kirjastoa kohtaan. Nopealla vilkaisulla näytti suhteellisen kattavalta.
Laitetaanpa tähän pieni testisetti Hesulin ennusteista nykyversiolla. Aineiston koko nyt n. 25 miljoonaa riviä, jossa mukana nyt viimeisten 200 päivän tuotot. Ennustejakso on pidetty 50 (tai oikeastaan 49) päivässä ja taulukossa ennustettu tuotto jakson viimeisenä päivänä. Lista on järjestetty laskemalla Tuotto*Tuotto / Riski ja sorttaamalla sen mukaisesti. Tuoton ollessa negatiivinen on arvo kerrottu vielä -1:llä.
Listan perusteella 15 potentiaalisinta nousijaa vähän tarkemmin.
Nää ei muuten ole sijoitussuosituksia!
Innostuin kokeilemaan ilmaista Pythonanywhere.com palvelua, joka on kyllä aika näppärä ainakin pieniin sovelluksiin. Kohtalaisen näppärästi saa sivut luotua Flask:n avulla. Uutta asiaa tuli opittua melko reippaasti, että sai edes tämän verran tehtyä. Suurimman osan aikaa vievästä laskennasta suoritan omalla koneella, jonka tulokset lataan toistaiseksi manuaalisesti sivustolle. Projektissa mukana toistaiseksi vain melkein kaikki suomalaiset osakkeet. Koko prosessi pitäisi kyllä ollla mahdollista automatisoida.
Alla tuore ennuste Incap kurssikehitykseen perustuen. Verrataan ensin First North:n osakkeisiin, jossa Incap merkattu punaisella.
Yhtiökohtainen sivu havainnollistaa aineiston sopivuutta Incapin kurssikäyrään ja aineiston lähimpien havaintojen toteutuneita tuottoja.
Sivustoa https://sawor.pythonanywhere.com/ päivitetty javascriptin avulla ja muutenkin vähän yksinkertaistettu ulkoasua. Nyt on selvästi paremmat kuviot ja taulukko. Mukana reilu 350 osaketta tällä hetkellä, joita lisään varmaan, kunhan saan viimeiset ohjelmapätkät integroitua. Tällä hetkellä osakkeita selailtava markkinoittain ja sen sisältöä on helpohko käydä läpi.
Kynttiläkuvioiden teko oli loppupeleissä yllättävän näppärää, mutta selvästi työläämpää kuin Pythonilla olen tottunut. Ylimääräisten viivojen piirtokin oli helppoa. Kuvioita vastaavat esimerkit osoitteesta canvasjs.com ja taulukko datatables.net
Ennustemalli antaa esimerkiksi Inderesille ja Kempowerille suunnilleen saman tuottoennusteen, mutta niihin liittyvä riski on eri suuruinen. Tuntuu aika luonnolliselta tulokselta riskin osalta, koska liiketoiminnat etenee omia enemmän tai vähemmän vauhdikkaita polkujaan.
Danelfin yllätti positiivisesti, kun tutkein tekoälyyn perustuvaa osakepoimintaa. Osakelistoilla “Largest 1,000 US-listed stocks by market cap” ja “STOXX Europe 600 stocks”. Viime syyskuussa oli julkaistu tuollainen TOP-lista, joka on tuossa alapuolella. Lisäsin siihen ainoastaan toteutuneet tuottoprosentit, jotka kurssikäyristä karkeasti laskin tähän päivään mennessä.
"Published 04/09/2023, 11:26
Investing.com - Danelfin has released its new September ranking of the stocks most likely to beat the market. Proprietary Machine Learning algorithms analyse more than 10,000 daily indicators for each company, based on more than 900 daily fundamental, technical and sentiment data. This methodology allows stocks to be evaluated from a holistic point of view. Aika vakuuttavan näköistä poimintaa.
But it is also important to consider the risk associated with each stock. Therefore, Danelfin has created a new ranking, which ranks companies according to the AI Risk/Reward Score, which is an average of the AI Score and the Low Risk Score.
The Low Risk Score is a score based on negative price fluctuations (semi deviation) over the last 500 market days. The higher the score (from 1 to 10), the lower the downside risk.
This is the Top 5 Risk/Reward Stocks, according to Artificial Intelligence data:
Spain
Europe
United States of America
United Kingdom
Germany
France
Italy
Translated from Spanish using DeepL."
Projekti etenee lähes päivittäin, mutta auringonpaiste ei oikein innosta istumaan koodailemassa. Osakekurssia analysoidaan nyt melkein 1500 osakkeelle päivittäin ja fundamenttianalyysiä löytyy 15 osakkeelle, jotka löytyy listattuna etusivun alareunasta.
Pitkään on tehnyt mieli alkaa tutustumaan paremmin kuumiin kasvuyhtiöihin ja ensimmäiseksi tutustumisen kohteeksi päätyi Nvidia. Maanantain jälkeen laitoin ennusteen talteen, jolloin seuraavan 50 päivän odotuksissa oli kurssitaso 1040.
Tulosjulkaisu villitsi sijoittajat ja osakepäätyi torstaina 1038 tasolle, jonka jälkeen odotusarvona on 20 kurssinousu.
Osakkeen tuotto-riski-suhde on muuttunut selvästi huonommaksi, joka verrattuna Nasdaq 100 osakkeisiin näyttää seuraavalta. Jonkin aikaa sitten tuottoennuste oli 13,7% ja riski oli suunnilleen samalla tasolla.
Esimerkiksi liikevaihto -ja liikevoittoennusteet näyttää alla olevilta. Liiketoiminnan suunta on muuttunut niin paljon, että ennusteissa olisi tarpeen nojata vain viimeisimpiin tietoihin. Nyt ennusteet näyttävät menevän alakanttiin, mikä takia pitäisi hieman muokata nykyistä ennustemallia, jossa käytetään vähintään viimeisen 2 vuoden tietoja. Ainakin tässä tapauksessa ihmisen ja koneen yhteistyö tulee tässä kohtaa, jossa voidaan tehdä valinta siinä, mitkä ovat relevanttia tietoa ennusteen tekemiseksi.
Kannattavuus säilyisi ennusteilla kuitenkin hyvällä tasolla ja omapääoman tuotto laskisi tulosten vahvistaessa omapääomaa. Vaatinee edelleen pienen hienosäädön, kun alunperin toteutin omapääoman laskennan eri tavalla.
Arvostus ei näytä kurssiraketin tavoin nousseesta osakkeesta niin pahalta kuin aluksi odotin. Punainen viiva kuvaa seuraavan 150 päivän ennustettua kehitystä. Kurssikehityksen osalta ensimmäiset 50 päivää, kuten yllä olevassa ennusteessa, jonka jälkeen viimeisen kurssitason odotetaan pysyvän samana jakson loppuun asti.
Ensimmäinen mahdollisimman yksinkertainen versio markkina-arvoa ennustava neuroverkkoihin perustuva malli ja aineisto alkaa olla kasassa. Aineiston tietoja ovat Liikevaihto, Liikevoitto, Tulos ennen veroja, Tulos, Taseen loppusumma ja Oma pääoma. Näitä on ennusteen takana 8 kvartaalilta ja erilaisia muuttujia syntyi yhteensä 72 kappaletta. Aineistossa yhteensä n. 2100 kvartaalia, joista suurimpia on rajattu pois. Ilman rajausta muutama maailman suurin yhtiö sotkisi pienten suomiyhtiöiden arvonmääritystä ikävästi. Enemmänkin tietoja olisi, mutta mennään nyt näillä alkuun. Simppeli malli mahdollistaa toimimisen hyvin pienellä määrällä tietoa, mikä on tarpeellista vaikka listautumisten yhteydessä. Alla kuvaus mallin rakenteesta.

Alla ennustetut markkina-arvon ero nykyiseen. Negatiivinen prosentti kertoo osakkeen yliarvostuksesta ja positiivinen aliarvostuksesta. Martelan poistin joukosta, kun suurehko aliarvostus olisi pilannut muuten kivannäköisen kuvion.
Mielenkiinnosta lisäksi UPM:n ennusteet. Ainoastaan viimeisillä kvartaaleilla on käytetty ennustettua tilinpäätöstietoja. Muissa on käytetty toteutuneita/oikaistuja arvoja. Q2 2013 selkeästi suurempi ennustevirhe saattaa virheellisestä tiedosta. Viimeisin ero ennusteessa saattaa johtua, huonoista ennusteista.
Ennusteet näyttävät yllättävän hyvältä, enkä usko tuon kokoisen mallin ylisovittavan älyttömästi. Keskimääräinen virhe UPM:n ennusteissa 8,7% ja mediaani 6,1%.
Miten hyödynnät näitä käytännössä ja oletko päässyt tuotoille?