En tiedä onko tämä oikea paikka mielenkiintoisen systeemitreidauksen videoille. Itselläni ei mielenkiintoa opiskella tätä alaa, mutta hattua kyllä nostan kaverin tekemille tuotoille ja kaiken datan ylläpitämiselle ja oman tien kulkemiselle.
Vakuuttavaa tekemistä ja mielenkiinnolla seuraan tulevia vuosia. Varsinkin videoista osa 2, näyttää vähän konkretiaa mitä tällainen dataharavointi vaatii, riskienhallinnasta, mentaalipuolesta ym…
Oli kyllä silmiä avaava kokemus katsoa nämä muutama video.
Kovaa suorittamista, mutta kyllähän tuossa aika isoja riskejä on. Aina on olemassa riski, että ennen näkemättömiä asioita tapahtuu. Viime viikolla on ollut astetta jännempi treidi (alla)
Syyskuussa on kuitenkin osunut treidit aika kohdilleen. Kokonaisuudessaa nostojen takia on jäänyt 228 849$ voitot saamatta, jolloin TWR:n mukainen salkun koko olisi 720 849$
Heräsi tällainen ajatus: voisiko transformer-mallin opettaa osakehintasarjoilla?
Tekninen analyysi kai perustuu ajatukseen, että tietyt säännönmukaisuudet toistuvat datassa ja näitä hyödyntämällä voi tehdä tuottoa. Transformerin läpimurto-ominaisuushan on nimenomaan löytää suuresta määrästä sequence-dataa (esim. LLM:issa luonnollisesta kielestä) säännönmukaisuuksia ja ennustaa niiden perusteella seuraava datapiste. Miksei siis transformer-malli voisi oppia ymmärtämään bull ja bear flag -kuvioita, päätä ja olkapäitä jne. tai jopa säännönmukaisuuksia, jotka meille ihmisille eivät ole ilmeisiä?
Muutama hyvin suppean, mutta lupaavan kokeilutuloksen löysin netistä. Kertokaa mulle, missä tässä on sudenkuopat ennen kuin alan tekemään tästä itselleni projektia?
Kielimallit ja transformerit ei toimi mun käsitykseni mukaan aikasarjojen ennustamiseen. Varmaan ihan liikaa satunnaisuutta kurssikehityksissä, eikä mallit ymmärrä aikasarjojen luonnetta.
“Time series data is fundamentally sequential, where the order of data points carries significant meaning. A key characteristic of time series is that it’s temporal — each data point is intrinsically linked to its position in time. This is where the permutation-invariant property of the self-attention mechanism becomes a problem. Permutation-invariance means the model treats the sequence as a set, ignoring the order of elements, which leads to the loss of temporal information. This property allows the model to give the same attention values even when the positions of data points are switched around.”
Yksi suhteellisen yksinkertainen ja mielenkiintoinen tapa on aikasarjan ennustaminen Diskreetti Fourier-muunnoksen avulla. Siinä sovitetaan siniaaltoja kurssikäyrään ja niitä jatkamalla saadaan laskettua ennusteet. Stationaarisuus on kuitenkin huomioitava sovellettaessa menetelmää osakekursseihin.
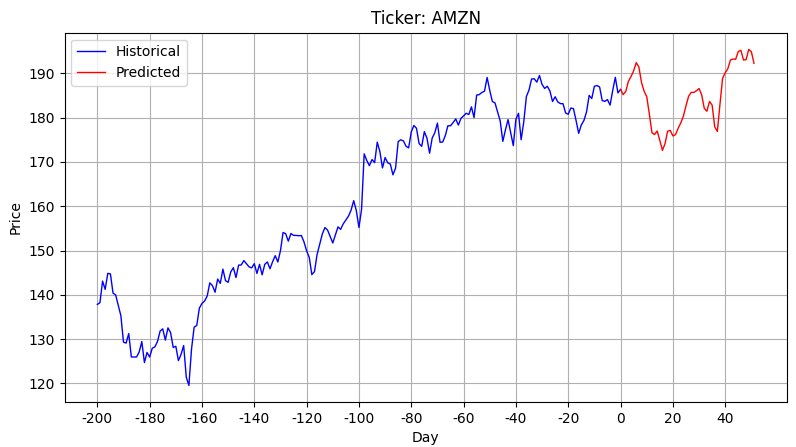
Alla yksi esimerkki Amazonille, joka alunperin kesäkuun 26 päivä postattu Treidi ja swingi: ideoita, analyysia ja tulkintaa -ketjuun. Sinisellä värillä olevan kurssikehityksen perusteella on ennustettu punaisella värillä kuvattu kurssikehitys.
Toteutunut kurssikehitys on yllättävän hyvin osunut ainakin tähän yksittäiseen ennusteeseen. Nuolella on havainnollistettu ennusteen ajankohtaa.
Kiitos linkistä! Jäin kyllä vähän ihmettelemään johtopäätöksiä tuossa tekstissä liittyen pääasialliseen counter-argumenttiin eli aikasarjan ajallisen sijainnin katoamiseen (ts. datan aikasarjaluonteeseen).
Esim. tämä: “In a Transformer model, the self-attention mechanism allows each token in the input sequence to interact with every other token, thereby understanding their dependencies and relationships. While this mechanism is highly effective for tasks like machine translation, where the order of words in a sentence can be shuffled without losing meaning, it becomes problematic when applied to time series data.”
Kyllähän kielessä sanojen järjestyksellä on äärimmäisen suuri merkitys. Lause “Pekka syö kalan” on merkitykseltään ihan eri kuin “kala syö Pekan”. Juuri siksihän transformerit käytää positional encodingia (mikä toki lukee myös tekstissä). Mulle ei aivan aukea, miten autoregressiiviseen “ennustamiseen” perustuvat transformerit varsinaisesti kadottaisivat temporal-tiedon - @Ripelein ymmärrätkö sä ? Tutkimusevidenssin, joka tekstissä esitellään, toki ymmärrän.
Edit: lähdepaperi näyttäisi keskittyvän mm. luonnonilmiöihin kuten säähän sekä muihin aikasarjoihin, joissa ehkä treidauksen olettamat epäsatunnaisuudet ovat ovat osakeaikasarjoja pienempiä.
Tää on jo ihan silkkaa voodoota . Mun ajatus oli nimenomaan treenata transformeri osakehintojen downstream ennustamiseen (ehkä jopa per tickeri). Mutta nämä kirjoittajat esittävät, että sekin olisi ehkä tarpeetonta ja voisi käyttää suoraan jotain frontier-mallia ilman fine-tunausta .
Propsit myös paperin otsikosta, joka on ihan suora rip-off GPT2 paperista (Language Models are Unsupervised Multitask Learners).
En kanssa ihan täysin ymmärrä tuota, että sijainti katoaisi johonkin. Prosessi kuitenkin toistuu samanlaisena ja tietyssä järjestyksessä koko ajan. Asia ei ehkä ole niin yksiselitteinen kuin annetaan ymmärtää ja erot menetelmien välillä voi olla suhteellisen pieniä. En ole kuitenkaan syvällisesti perehtynyt noihin kielimallien toimintaan.
Käytännössä tuossa “Pekka syö kalan” -esimerkissä sanat muuttuvat, joten se on ehkä olennaisesti eri asia kuin sanajärjestyksen muuttaminen. Aika paljon teksteissä on yleensä mahdollisuuksia vaihtaa sanajärjestyksiä ilman muita muutoksia ja säilyttää sama viesti.
Omien kokemuksieni perusteella yritän seuraavaksi varmaan jotakin tiettyihin tilanteisiin opetettua mallia. Keskittyminen erikoisempiin tilanteisiin toivottavasti yksinkertaistaa ja nopeuttaa kaikkia vaiheita ja tekee lähestymistavasta vähän ymmärrettävämpää. Kaikkiin tilanteisiin sopivat yleiset mallit tuntuvat aika hankalilta saada toimimaan.
Transformerit ovat yksinkertaisesti erittäin epätehokas tapa tehdä aikasarjaennustamista. Kannattaa tsekata Nixtlan TimeGPT ja muutkin mallit, ei vaadi muutamaa koodiriviä enempää testata eri malleja. Itse näen suuremman potentiaalin teksti- ja kuvadatan enkoodauksessa.
Sanat muuttuvat vain suomenkielen kaltaisissa kielissä, joissa on sijapäätteitä yms. Esim. englanniksi sanat olisivat täsmälleen samat, mutta merkitys muuttuu täysin sanajärjestyksen vaihdon myötä: “Pekka eats fish” vs. “fish eats Pekka” .
Epätehokas missä mielessä - laskennallisesti? Verrattuna mihin - tilastollisiin aikasarjamalleihin?
Kiitos tästä Nixtla-linkistä Pitää tutustua tarkemmin. Ihan sekään ei kuitenkaan nopeasti vilkaistuna näyttäisi vastaavan omaa ajatusta, joka oli replikoida decoder-only malleja vaihtamalla vain opetusdata toisenlaiseksi sequenceksi. Ajatuksena siis tehdä täysin tyylipuhdasta teknistä analyysia ja löytää säännönmukaisuuksia ilman, että mukaan tungetaan multivariate-ajattelua.
Yleensä tavoitteena on maksimoida ennustetarkkuus tavalla tai toisella, jolloin samaan lopputulokseen pääset todennäköisesti huomattavasti pienemmällä kehitykseen menevällä ajalla ja laskentateholla käyttämällä perinteisempiä malleja. Nixtlan TimeGPT on syönyt sisään satoja miljardeja rivejä aikasarjadataa - miten meinasit omasi kouluttaa tai fine-tunata?
Se on siis ihan selvää, että kouluttamiseen tarvitaan dataa ja GPU-voimaa. Itsellä on akateemisen ympäristön tuomat pääsyedut näihin molempiin eli tässä vaiheessa pohdintoja nuo ovat vielä “sivuseikkoja” . Muistaakseni esim. NYC-pörssi generoi päivässä jonkun karkeesti +10GB hintadataa (vrt. GPT-2 treenattiin 40GB:llä) eli senkin vuoksi osake-sequencet voisivat olla täydellinen kandidaatti, kun miettii, että transformereille data x mallin koko = mallin suorituskyky Neural Scaling Lawsin perusteella.
Eli tässä vaiheessa ei ole pohdinnan kannalta kriittistä niinkään se, onko paras bang-for-buck kotiolosuhteissa joku ARIMA-ratkaisu vaan se, onko tässä ylipäätään missään olosuhteissa mitään järkeä.
Ja siis näin alkuun voisi testata asiaa vaikka jollain GPT-2 -tason proof-of-concept -ratkaisulla, jollaisen saa pyörimään ihan vaikka oman läppärin GPU:lle vaikka vain yfinance datalla.
Edit: @Avokado:n linkittämä paperi tosin sai pohtimaan, että mitä jos vain lataisi esim. Llama3.2:n ja experimentoisi sopivan tokenizerin kanssa hommaa lähes nollavaivalla.
Voi olla aika nollapostaus tähän keskusteluun, kun en nyt voi sanoa tuntevani kumpaakaan teoriaa syvällisesti - treidausta tai transformereita - että voisin ottaa kantaa. Luin aiemmin tällaisen tekstin varsin hypehakuisen otsikon takaa:
Laitetaanpa tähän tällainen pieni ja pikainen testailu mitä olen kielimalleihin liittyen välillä miettinyt. Lähtökohtana on Karpathyn gpt.py koodi alla olevasta linkistä.
Shakespearen sijaan ollaan kiinnostuneempia indeksin tuotoista. Muutetaan koodia riviltä 19 eteenpäin. Kohta ‘chr(int(200 + 1000 * data[i]))’ muuttaa päivittäisen tuoton ensin positiiviseksi kokonaisluvuksi ja edelleen sitä vastaavaksi merkiksi. Tämän jälkeen kurssikehitys on muutettu tekstiksi, joten sitä on mielekästä käsitellä kielimallilla. Noiden neliöiden muutoksissa pitäisi olla hakasulkeita.
Muutos →
torch.manual_seed(1337)
import matplotlib.pyplot as plt
import yfinance as yf #Ladataan Indeksin tiedot ja lasketaan päivittäiset tuotot
data = yf.download(tickers=[‘^NDX’], period=‘max’, interval=‘1d’)[‘Close’].pct_change().round(3)[1:].to_list() #Muutetaan tuotot positiivisiksi kokonaisluvuiksi ja muutetaan ne merkeiksi
X =
for i in range(0, len(data)): X.append(chr(int(200 + 1000 * data[i])))
#here are all the unique characters that occur in this text
chars = sorted(list(set(X)))
vocab_size = len(chars) #create a mapping from characters to integers
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ‘’.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
#Train and test splits
data = torch.tensor(encode(X), dtype=torch.long)
n = int(0.9*len(data)) # first 90% will be train, rest val
train_data = data[:n]
val_data = data[n:]
Kielimalliin ei pitäisi olla mitään tarvetta tehdä muutoksia, mutta alun parametreja muutin läppärille sopiviksi. Tuottoja pitää muuttaa tekstiksi ja tekstiä tuotoiksi. Koodin loppuun tehdään seuraavia muutoksia.
Muutos → #generate from the model
context = torch.tensor([encode(X[len(X) -50:])], dtype=torch.long, device=device)
Ennuste = decode(m.generate(context, max_new_tokens=500)[0].tolist())
Pct_muunnos =
Kurssi = [100]
for i in range(0, len(Ennuste)):
Tuotto = (ord(Ennuste[i])-200)/1000
Pct_muunnos.append(Tuotto)
Kurssi.append(Kurssi[i] * ( 1 + Tuotto))
Ennustetut päivittäiset tuotot viimeiselle 50 päivälle ja seuraavalle 500 päivälle näyttää testissä seuraavalta. Jännästi vuoden päästä alkaisi aikajakso jolloin volatiteetti on selvästi voimakkaampaa.
Indeksin lähtötasoksi asetin 100, että kriittinen arviointi on helpompaa. Ennuste näyttää ainakin silmärääräisesti ihan oikealta kurssikehitykseltä. Volatiteettia toki on aika runsaasti.
Tulokset näyttää ihan järkeviltä, mutta en laittais kaikkia rahojani indeksiin testin perusteella. Koodi toimi tällaisena, kun suurin päivälasku oli alle 20% ja kovin nousukin oli maltillinen. Muussa tapauksessa voisi tulla tarve tehdä muutoksia .
Noniin - tämä on täsmälleen se ajatus, jota yllä yritin hahmotella ja jonka järkevyyden perään tiedustelin . Just vastaavan tyyppistä kokeilua tarkoitin kun kirjoitin, että asiaa voisi testata jollain GPT-2 -tason proof-of-concept -ratkaisulla Heti tulee mieleen kysymyksiä:
Minkä kokoinen tuo ^NDX sarja on ihan megabiteissä?
Kauan kesti opettaa?
Ootko testannut mallia minkään toisen indeksin toteumia vastaan (ts. generalisoituuko ollenkaan)?
Katsoitko millaisiin training/test losseihin päädyttiin (muistaakseni loss funktiona oli MSE Karpathyn “GPT2”:ssa)? Katsoitko ton test setin osalta suoritusmittareita (accuracy, precision jne)?
Muutama huomio itse toteutuksesta, joilla tätä voisi potentiaalisesti parantaa:
Tämä on totta, jos ei halua muuttaa sitä valmiiksi koodattua decoderia. Voisi kuitenkin olla ehkä fiksumpaa tehdä muutokset sinne. Luonnollisen kielen suurin ongelma on nimenomaan se, että se pitää kekseliäillä tavoilla muuttaa numeroiksi, jotta gradientit voi optimoida. Numeerisella datalla, joita osakekurssit / -tuotot ovat, ei ole tätä ongelmaa, joten kannattanee suoraan käsitellä vain floating point -tyyppejä .
Liittyy edelliseen, mutta luulisin, että numeerisia sekvenssejä ei ole optimaalista hajottaa yhden integerin mittaisiksi tokeneiksi. Karpathy tekee Shakespeare-mallissa tämän, koska luonnollisen kielen osalta tokenisointi on pakko tehdä. Numeeriselle datalle en itse näe mitään tarvetta opetusta edeltävään manipulaatioon paitsi että positional encoding pitää tietysti tehdä.
Yleisajatus vielä: oma ajatus oli ehkä enemmän myös sen kaltainen, että piste-estimaattien sijaan voisi tuottaa ennen viimeistä softmaxia syntyvän jakauman eri skenaarioiden välillä ja katsoa, missä määrin jakauma antaa indikaatiota kurssien tulevaisuuden suunnasta.
^NDX sarjassa on 9838 havaintoa, mistä 90% harjoitusdatassa.
Opetus läppärillä kesti ehkä muutaman minuutin, kun äskön kellotin. Kotikoneella olisi mennyt hiha-arviolla minuutti ja näytön ohjaimella pitäisi mennä selvästi nopeammin. Näin iso malli alkaa nopeasti ylisovittamaan pientä dataa. Alla on noita harjoituksen tietoja.
Pitää kotona rakentaa paremmat testit jossain vaiheessa, kun siellä on paljon hyödynnettävää aineistoa ja parempi kone. Nyt oli tarkoitus lähinnä kokeilla kevyesti tän idean toteutuskelpoisuutta mökillä. Niitä varten joutuu kuitenkin kirjottamaan aika paljon koodiakin. Noita hyviä parannusehdotuksiakin voisi vähän miettiä ja kokeilla.
Jep - hyvää settiä . Taitaa olla auttamattomasti liian pieni treenidata noin “isolle” mallille, jotta tulokset olisivat generalisoitavissa. Tässä taitaa YFinance heittää aika ison haasteen . Siellä on näköjään aika isoja rajoitteita sen suhteen, miten paljon havaintoja datasetissä on. Näköjään ei myöskään auta edes tihentää periodia, koska tällöin mittaushistoria lyhenee myös.
Jos menee Chinchilla lakien mukaan, pitäisi noita havaintoja (jos havainto = 1 token) olla 16M. Pitäisi siis käytännössä olla ainakin kaikki yhtiöt USAsta kattaen Sepen, Nasdaqin ja Russelin ja ottaa lisäksi mukaan parit muutkin länsipörssit, jotta päästäisiin edes likimain riittävälle tasolle.
Ne jotka käyvät myös oikeaa kauppaa simulaatioiden lisäksi: Kuinka oikea kaupankäynti on mennyt verraten backtesteihin?
Olen kiinnostunut enemmän suorasta robottikaupankäynnistä kuin syvällisemmästä analyysistä jota täällä myös paljon on. Pari vuotta sitten testasin algoilla kaupankäyntiä ensimmäisen kerran mutta homma kaatui palveluntarjoajan ongelmiin, vaikka touhu olikin nimellisesti voitollista. Nyt on löytynyt kipinä uudelleen ja käsissä on esim. päivätasolla (ei päivittäin) kauppaa käyvä algo joka 10v backtestauksen perusteella olisi antanut >7 000% voitot ja vain yksi vuosi olisi ollut tappiollinen (-30 %). Keskimäärin +60 % /vuosi. Max drawdown kuitenkin -45% ja benchmarkina toimivassa Nasdaq100:ssa vastaava -35%, eli hieman enemmän heiluntaa vaikkakin voitto moninkertainen.
Tulee vain mieleen miksi touhu tuntuu liian helpolta, vai onko käsissä nyt joku kultajyvänen…? Mihinköhän tässä nyt oikein pitäisi eniten kiinnittää huomiota ja millä metodeilla algoa kannattaisi testata? Toistaiseksi haluaisin saada drawdownia pienemmäksi ja ensimmäinen askel on lisätä myös shorttipuoli kuntoon, sillä nykyinen algo tekee vain longeja.
En harrasta itse tätä töiden tuomien rajoitusten vuoksi, mutta ennen työuran alkua kyllä oli tavoite tehdä jotain tällaista, niin heitän ehkä ympäripyöreästi sen aikaisen tutkimukseni pohjalta pari ideaa. Joku livenä oikeasti tätä tekevä vastannee paremmin. Tulee ihan pari peruskysymystä ekana mieleen, jotka ei selvinnyt kuvauksesta.
Mallinnatko “slippagea”, eli sitä miten sinun kauppasi fillataan lopulta? Kauppahan tuskin tapahtuu simulaatioissa eksaktiin kurssiin, vaan markkina liikkuu ostopäätöksen ja lopullisen kaupankäynnin välissä. Tämä tuntuu olevan se asia joka monesti unohtuu alkuun, ja tuottaa helposti uskomattomia voittoja. Tuota voi kokeilla lisäämällä deterministisen sinulle epäsuotuisan spreadin aina ostohintaan simulaatiossa, tai mahdollisesti antamalla sille jonkun jakauman, jolloin voit monte carlolla arvioida mitä odotettu tuotto olisi ollut.
Millä käy kauppaa? Nykyään ensimmäinen oletukseni on kryptot kun datan ja alustojen suhteen se on paljon helmpompi markkina kuin osakkeet. Jos kyllä, niin huomioitavaa on, että satunnaisella frekvenssillä käytävä kauppa satunnaisella pitoajalla tuottaa keskimäärin markkinatuoton, ja 10 vuoden tuottona 7000% on sellainen, että sen olisi saanut satunnaisilla ostiolla ja myynneillä kryptoissa.
Mikä on sharpe luku?
Joku muu varmaan osaa kertoa enemmän, mutta alan foorumeita jonkun verran lukeneena nämä on ehkä ne päällimmäiset asiat jotka menee pieleen, ja kannattaa tarkistaa heti ensimmäisenä ennenkuin alkaa pohtimaan pidemmälle.
 | Traders' Club 231")
 | Traders' Club 232")