Mitä jos yrittäisit kirjoittaa asiallisesti turhan pätemisen sijaan? Ei kai nyt kukaan kuvittele IP protokollan olevan katoamassa lähiaikoina mihinkään.
Tcp:n suhteen asia on juuri niin kuin aiempi kirjoittaja kertoi. Uusissa ”valtavirta” protokollissa tcp korvataan tehokkaammilla vaihtoehdoilla.
Yritin ja mielelläni olisin jättänyt tämän aiheen jo pari turhanpäiväistä viestiä sitten.
Vastausteni sävy muuttuu sitä mukaa, kun keskustelu menee syyttelyksi virheellisistä ja perättömistä väitteistä. Tämän episodin olisi voinut jättää väliin, mutta olen missä olen ja teen mitä teen lähinnä siksi, että en jätä mitään kesken. Päteä minun ei tarvitse kenellekään ja arvostan asiantuntijoita. Asiantuntemattomiin syytöksiin vastaan.
Ei kai nyt kukaan kuvittele IP protokollan olevan katoamassa lähiaikoina mihinkään.
Jos lukaiset aiemmat viestit huomaat, että olet väärässä. Internetin liikennettäkin voi luulla http-protokollalla toteutetuksi ja lähteä vielä väittelemään asiasta.
Mitä tulevaisuuden verkkoihin tulee, myös data- ja control-tasoihin tulee varmasti muutoksia verkkotarpeiden muuttuessa, mutta on liian varhaista sanoa minkälaisia ja vanhat protokollat eivät katoa mihinkään. Mainitsin jo aiemmin softapohjaiset verkot (SDN). ITU on julkaissut aiheesta tutkielmia tai jonkinnäköisiä ennustuksia ja niissä SDN:n ja VNF:n (virtuaaliset verkkotoiminnot) oletetaan olevan isossa roolissa 2030-luvun verkoissa. Tässä yksi asiaa selventävä julkaisu aiheesta ITU:n “Network 2030” -ryhmältä. ITU:n palvelusta löytyy myös lisää ryhmän koostamaa ja muiden julkaisemaa materiaalia.
Jotta edes joku linkitys tekoälyyn säilyisi – verkoilla on merkitystä myös tekoälyn kehityksessä. ITU nimittää tulevaisuutta koskevissa materiaaleissaan kaikkein vaativimpia tarpeita “teleportaatio”-nimityksellä. Linkittämästäni artikkelista asiasta voi lukea lisää kohdasta “17.8 AI/ML role in Management & Orchestration”.
En ole verkkotekniikan DI, mutta arvostan sellaisia ja olen sellaisten kanssa tehnyt lukuisia projekteja ja hankkeita ympäri maailmaa. Jaan ja vastaanotan mielelläni tietoa tuntemistani asioista ja mielenkiinnon kohteista. Jos joku pitää sellaista minun tai jonkun muun osalta pätemisenä – ihan sama.
EUn tekoälyasetus: EUn asetus on “riskiperustainen ja käyttötapauskohtainen lähestymistapa tekoälyn käyttöön ja kehittämiseen. … Tässä jaottelussa kiellettyjä käyttötapoja ovat todennäköisesti esimerkiksi ihmisten manipulointi”
Manipulointi. Onko mainonta tai somen sisältöä juuri sinulle räätälöivät algoritmit muuta kuin ihmisen manipulointia? Minun mielestäni ei. Ekat koittaa saada sinut ostamaan tuotteen ja somen algot koittavat maksimoida sinun somessa viettävän ajan ja engagementin. Ylen juttu alla. Nämä siis kiellettyä jahka “EU da köning de regularization” saa homman päätökseen.
Pörssin tekoälyralli. Ymmärrän miksi NVidia ja Microsoft ovat raketoineet. En ymmärrä miksi osakkeet kuten Tesla, Palantir, SoFi, UpStart ja Datadog ovat raketoineet. Noilla firmoilla on tekoälyä, mutta heidän tekoälyllä ei ole ihan hirveästi tekemistä Trasformer pohjaisten LLM mallien kanssa. Esim vaikka Datadogin pilvipalveluiden monitorointi ei suuresti voi hyödyntää LLM pohjaista tekoälyä, koska logia ja metriikkaa tulee niin kovaa vauhtia ettei LLM malli pysy millään perässä. Teslan osalta sama. Heidän autopilotti ei tule yhtään paremmaksi kuskiksi LLMien avulla. Ehkä muut sijoittajat eivät tätä tiedä. Tai sitten muut sijoittajat luulevat etteivät muut tätä tiedä ja ostavat siksi.
Hieman kevyt kysymys. Täällä on selvästikin ihmisiä jotka ovat IT-alalla, ohjelmistokehityksen parissa ynnä muissa vastaavissa hommissa. Miten sikäläisissä kahvipöytäkeskusteluissa spekuloidaan GPT:n muovaavan IT-alaa tulevina vuosina? Ollaanko enemmän huolissaan vai innoissaan? Ovatko eniten vaarassa sellaiset peruskoodarit, joilla ei ole syvempää ymmärrystä tietokoneen toiminnan perusteista, tietorakenteista ja algoritmeista, ylipäätään alan teoreettisesta perustasta?
Olem kuullut kahdenlaista kannanottoa: joko business as usual tai koodaus nykymuodossa katoaa. Itse en usko kumpaankaan vaan näen tilanteen toistavan historiassa esiintynyttä kaavaa: uusi teknoogia otetaan osaksi työkalupakkia ja se nostaa koodareiden tuottavuutta ja siten laajentaa sitä joukkoa ongelmia jotka on koodaamalla ratkaistavissa. Koodarit jotka eivät suostu tai kykene ottamaan uusia välineitä ja työtapoja haltuun häviävät, mutta siinä ei ole mitään uutta.
Kaivoin muutaman aiemman viestini asiasta. Niissä on pohdittu tätä tarkemmin. Sittemmin olen itse ottanut Github Copilotin käyttöön, ja se kokemus vahvistaa uskoani tähän näkenykseen.
Jotkut ovat sitä mieltä että tämä on kuin vuorovesi ja nostaa kaikkia veneitä (koodareita). Paitsi niitä joissa on reikä (= koodarit ketkä ei opettele käyttämään tätä). Toiset on sitä mieltä että kevyemmällä arsenaalilla varustetut saa koodarit saa kenkää. Vaikea sanoa kumpi tapahtuu. Molempiin näkökulmiin löytyy perusteita.
Kuulun siihen kastiin, joka oli 1990-luvulla “huolissaan” työpaikastaan ja jolle esimies vakuutti, että Intian ja Aasian koodarit tekevät tulevaisuudessa kaikki työt, joten kannattaa keksiä jotain muuta. Ja yrittiväthän ne hieman myöhemmin, kunnes todettiin, että ei tämä nyt ihan toimi. Siirryin tekemään jotain muuta vuosituhannen vaihteen hujakoilla, mutta syynä oli se, että olin mielestäni keskinkertainen kehittäjä ja muut asiat kiinnostivat enemmän – ei siis pelko intialaisten invaasiosta.
On mielestäni selvää, että kaiken tasoisten koodarien pula tulee jatkumaan hamaan tulevaisuuteen. Full stack -osaaminen takaa varmasti työpaikan nykykoodareille eläkeikään asti ja mielestäni tekoälyn lisääntyminen työkaluissa vain lisää devaajien tarvetta. Allekirjoitan myös sen väitteen, että ainoa tapa tehdä itsestään koodarityömarkkinoiden hylkiö on jättää uudet työkalut opettelematta ja niiden tarjoamat mahdollisuudet käyttämättä. Näin se on aina ollut – jo ennen ChatGPT:tä. Yksi osa-alue, jossa kehitystyöt tulevat lisääntymään räjähdysmäisesti on todennäköisesti erilaisten integraatioiden ja rajapintojen kehitys.
Ehkä tähän on syytä lisätä, että kukaan ei osaa vielä sanoa, missä mennään vaikka 20 vuoden päästä. Työt tulevat muuttumaan – eikä vain koodareiden työt.
Edit. Unohdin mainita isomman kuvan softakehityksestä… Jos katsoo ympärilleen, kaikki on yhtä virtuaalia. Näkemämme ja kokemamme maailma on enemmän ja enemmän softaa vaikkei AR-laseja olisikaan silmillä. Tämä koskee myös infrastruktuuria, jossa kehitys on nopeaa. Rauta ja fyysinen infrastruktuuri on jo nyt – ja vielä enemmän tulevaisuudessa – ikäänkuin virtalähde, jota mitataan tehokkuudessa tai kyvykkyydessä – loppu tehdään softalla. Ja tämä maailma ei ilman softan tekijöitä synny.
Ainakin tämän pienehkön tutkimuksen lopputulema oli että tämänhetkisillä työkaluilla ohjelmistokehitys muuttuu vahvasti koodaamisesta GPT:n ehdotusten tarkastamiseksi, mikä johtaa siihen että tällä hetkellä kokemattomien koodareiden käsissä tuosta lienee enemmän haittaa kuin hyötyä.
Tarvitaan siis lisää koodareita jotta saadaan työkalut sellaiseen kuntoon että tekoälyllä parannetaan peruskoodareidenkin tuottavuutta. Ja siinä vaiheessa on varmasti keksitty seuraava uusi juttu, jonka hyödyntämiseen tarvitaan jälleen enemmän niitä entistä tuottavampia koodareita.
Tämä on oma havaintoni myös GitHub Copilotia käytettäessä. Fiilis on kuin todella fiksua kokematonta koodaria, jolla on vahva tunnelinäkö/laput silmillä, ohjaisi.
Niin kauan kuin ne juniorit ovat osana tiimiä, jossa on kokeneempia ja jossa on tähänkin asti tehty juniorien mentorointia oikeasti, tämän ei tarvitse muuttaa hirveästi mitään. Tiimi ohjaa oikeille tavoille. Omassa tiimissäni olen sanonut että “koska Copilot teki sen niin” ei ole koskaan riittävä vastaus
Joo ihan samat fiilikset koodauksen osalta ja kyllä ChatGPT 4:llä onnistuu koodaus varsin mainiosti kunhan osaa vaan tökkiä sitä oikeaan suuntaan. Itse hostatut mallit ovat koodauksen osalta vielä enemmän raakileita, tosin oman testailun perusteella WizardCoder on jo aika lähellä sitä tasoa mihin ChatGPT 3.5 pystyy.
Tuli testailtua samalla exllamaa ja sehän on aivan mieletön nopeusboosti AutoGPTQ:n verrattuna. 4-bit 30B mallilla 10 tokenia sekunnissa kotikoneella
Jännäksi menee mitä seuraavaksi keksitään. SqueezeLLM kuulostaa ainakin paperilla todella lupaavalta
To address this, we introduce SqueezeLLM, a post-training quantization framework that not only enables lossless compression to ultra-low precisions of up to 3-bit, but also achieves higher quantization performance under the same memory constraint.
…
When applied to the LLaMA models, our 3-bit quantization significantly reduces the perplexity gap from the FP16 baseline by up to 2.1x as compared to the state-of-the-art methods with the same memory requirement. Furthermore, when deployed on an A6000 GPU, our quantized models achieve up to 2.3x speedup compared to the baseline.
Tätä menoa ei tarvitsekaan ostaa seuraavaan koneeseen 2x RTX 5090 vaan nykyinen RTX 3090 riittää mainiosti omaan käyttöön
Eiköhän mallit sitten vain paisu kuin pullataikina ja hyödyntävät edelleen kaiken tarjolla olevan laskentakapasiteetin ja muistin… tosin täytyy sanoa että lähiaikoina “ammattiraudan” osalta nopean muistin määrä todennäköisesti kasvaa vauhdikkaammin kuin itse prosessointiteho.
Lähinnä nämä viime aikojen optimoinnit kertovat siitä että ongelmaa ratkoneet porukat ovat aluksi keskittyneet itse ongelmaan ja jättäneet optimoinnit tulevaisuuden huoleksi. Sitten saatiin jonkinlainen tuote kasaan ja siihen iski kiinni hurja määrä uusia käsipareja ja koska heillä ei ole pääsyä viimeisimpiin kehitysversioihin, helpoin asia mitä aluksi voi tehdä on olemassaolevan ratkaisun optimointi niin että se tarvitsee vähemmän resursseja. Varmasti myös paljon uutta porukkaa on itse ongelmanratkaisun kimpussa kehittämässä uutta, mutta heillä ei ole muutamassa kuukaudessa esittää mitään isoja hyppäyksiä, toisin kuin optimointiin keskittyneillä, joten heistä ei vielä ole kuulunut mitään. Ennustan että vuoden-parin aikajänteellä näitä alkaa ilmestymään ja vielä on täysin auki kuka tämän kilpajuoksun vie nimiinsä. Rahaa ainakin kaadetaan siihen malliin että siitä homma ei jää kiinni.
Ainakin minun mielestä se optimointi on tällä hetkellä kaikista tärkein osa-alue, koska rauta ei kehity ennen vuotta 2024-2025 ja ei kenelläkään yksilöllä ole varaa pistää kymmeniä miljoonia euroja uuden LLM-mallin rakentamiseen. LLaMAn lokaalin hostauksen osalta koko homma muutenkin pyörii ihan muutaman yksilön ja yhteisän varassa, joilla on varaa ja osaamista ostaa laskentatehoa hienosäätämään LLaMAa ja luoda siitä aidosti käyttökelpoisia malleja.
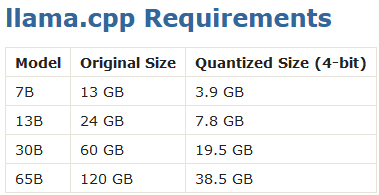
Kaikki laskentateho kyllä tullaan käyttämään ja oikeastaan käytetään jo nyt. Ellei ole joku hyperspesialisoitu malli, niin näistä tulee minun kokemukseni mukaan arkikäytössä aidosti hyödyllisiä vasta tuossa 30B parametrin kohdalla, joka vaatisi GPU:lta yli 60 GB VRAM. Kallein kuluttajamalli Nvidialta (koska AMD ei toimi hyvin) sisältää vain 24 GB kuumana käyvää GDDR6X, joten ilman optimointia ei oikeastaan pyöri edes tuo 13B.
Onneksi keksivät alkaa kvantisoida malleja, koska parametrien lisäys kompensoi moninkertaisesti sen epätarkkuuden, mitä alhaisemmista bittimääristä tulee. 65 B kvantisoituna vaatiikin sitten jo että osan kuormasta heittetään CPU & RAM ja varaa tarpeeksi pagefilea, että mallin saa ylipäätään ladattua. Väkisinkin hitaampaa kuin näytönohjaimella leikkiminen, mutta jos alta löytyy kaverina uusin Intelin i9 ja 128 GB nopeaa keskusmuistia, niin kyllä ihan siedettäviin vauhteihin silloinkin päästään.
Pitää toivoa, että Nvidia vihdoin alkaa tuoda järkeviä muistinlisäyksiä näytönohjaimiin myös kuluttajapuolella ja että saisimme kuluttajapuolella vihdoinkin 48 GB VRAM näytönohjaimen vuonna 2024. RTX A6000 48 GB ammattilaisille maksaisi 6500 €, joten tämä harrastus menee muuten pitkälti arvosijoittajan ulottumattomiin
Itse pelkään pahoin että NVIDIA katteiden perässä tahallaan “rampauttaa” kuluttajakortit LLM-käytön osalta niin että seuraavassakin sukupolvessa jäädään sinne 24-32GB nurkille pelikorttien lippulaivassa ja ne jotka haluavat enemmän joutuvat siirtymään ammattikortteihin ja ammattikorttien (3-4x) hintalappuihin. Tämä on NVIDIAlle loistava tapa segmentoida markkinaa ja taatusti hyödynnetään ellei kilpailu pakota tekemään toisin.
Eli jos haluaa tilanteen olevan toisin, pitää rukoilla Lisa Sun suuntaan ja toivoa että sieltä tulisi 64GB Radeonia joka pakottaisi nahkatakkimiehen peliliikkeisiin.
Oikeastaan sanoisin, että nyt jo ollaan tilanteessa, jossa aikahorisonttien lyhenemisen myötä tulevaisuuden projektioiden tekeminen muuttuu aina vain vaikeammaksi. Jopa 5-10 vuoden hahmottaminen tulevaisuuteen menee aika hankalaksi. Luin vähän aikaa sitten erilaisia artikkeleja noin 5-10 vuoden takaa, joissa yritettiin hahmottaa tekoälyn kehitystä eteenpäin. Usein niissä esimerkiksi oletettiin melkein varmana asiana, että pian rekka-autoliikenne automatisoidaan, mutta kukaan ei ennakoinut copywriterien tai graafikoiden hommien olevan ensimmäisenä.
Usein sellaiset asiat, jotka vaikuttavat helpoilta ihmisille, voivat olla vaikeita toteuttaa AI:lle ja toisinpäin. Voidaan myös miettiä, mikä kielimallien tilanne oli 5 vuotta sitten ja koettaa ekstrapoloida samaa kehitystä tulevaisuuteen, niin aika isot muutokset tuossa olisi kyseessä. Muistan kun Geoffrey Hinton käytti yhdessä haastattelussa ilmaisua, että tulevaisuudessa vallitsee tavallaan eksponentiaalinen sumu – lähelle näkee kohtalaisen hyvin, mutta jonkin matkan jälkeen ei voi enää tietää oikein mitään.
En ole vuosiin oppinut niin nopeasti asioita kuin ChatGPT:n avulla. Sen vastaukset ovat selkeitä ja ytimekkäitä. Voi kysyä täsmennyksiä. Tämä voittaa Googlen niin monella tapaa, myös perinteisen luokkaopetuksen monella tapaa, että en ala edes luettelemaan.
Itselle aukeaa tavallaan ahdistava näkymä tästä. Ne, jotka luonnostaan kyselevät ja ihmettelevät asioita paljon ja ottavat niistä selvää, ne voivat näiden työkalujen avulla alkaa valonnopeudella erkaantua niistä, jotka eivät ole kiinnostuneita. Kun tajusin sen nopeuden, millä omaksun uusia asioita tämän avulla, en ollut yksinomaan ilahtunut vaan myös ahdistunut. Olen aina lukenut kirjallisuutta ja selvittänyt juttuja wikipediasta, katsonut dokumentteja, mutta tämä tuntuisi paljon tehokkaammalle tietyssä mielessä, toki poistamatta tarvetta edellisille tai korvaamatta niitä. Se ikään kuin täyttää vuosien saatossa syntyneitä tiedollisia aukkoja ja kun ne täyttyvät, kokonaisymmärrys kehittyy samalla.
Jossain kohtaa tulee vastaan ihmisen kapasiteetti. Ihminenhän on huono muistamaan. Asiat jotka osasit hyvin 20 vuotta sitten, mutta et käyttänyt sen jälkeen, ei ole ihan tuosta vain takaisin muistissa. Ehkä juuri sen takia, että sitä tilaa ei nyt niin hirveästi ole kaikenlaiseen toisiinsa liittymättömiin (isoihin) asioihin. Aivojenhan käsitetään toimivan parhaiten kun se yhdistelee jollain tavalla liittyviä asioita toisiinsa uusissa yhteyksissä. Sitten kun aletaan miettiä tilannetta, jossa jokainen olisi AI:n myötä vaarassa muuttua monen alan ekspertiksi ja ahdistua siitä, voikin loppua tila?
Eli oikeastaan näen vaarana toisen suunnan, joka on jo ollut aika totta kun internetistä tuli yleiskäyttöinen. Tekoälyn myötä kukaan ei jaksa perehtyä asioihin, kun voi vain helposti kysyä tekoälyltä sen (vrt. “miksi opetella vaikeita juttuja kun voi laskea laskukoneella?”, “miksi painaa mieleen asioita jotka voi googlettaa 5 sekunnissa?”). Koska tulee se toinen viiva vastaan, että kukaan ei enää osaa itse mitään, kun kaikki pitää kysyä tekoälyltä? Homo scientia dementicus?
Sillä tuntuu olevan faktat riittävän hyvin hallussa. Olen tankannut historiallisia ja eri maihin liittyviä faktoja. Mitä erikoistuneempaan tietoon mennään, sitä varauksellisempi pitää olla.
En pidä ongelmana kahta esitettyä, muistikapasiteetin rajallisuutta ja mahdollista virheellistä tietoa:
Tieto lisääntyy yhtä kaikki ja ennen kaikkea lisääntyy ymmärrys, sillä tuon avulla voi tilkitä avoimeksi jääviä kysymyksiä. Usein esimerkiksi kirjan lukeminen herättää yhtä paljon jatkokysymyksiä kuin antaa vastauksia. Wikipedia on ollut yllättävän heikko työkalu tässä tarkoituksessa. Parhaiten palvelee lyhyt ja ytimekäs tieto, jota voi halutessaan tarkentaa.
Kirjan lukeminen herättää jatkokysymyksiä, mutta mistä se tieto sitten pitäisi hankkia. Kaikki muistaa, kuinka wikipediaa syytettiin ja yhä syytetään väärästä tiedosta, tai että se ainakin voi olla väärää. Pitäisikö ChatGPT:n faktat tarkistaa Wikipediasta vai mennä yliopiston kirjastoon. Mielestäni väärää tietoa ei tarvitse pelätä ja johonkin on tyytyminen, että asiassa päästään eteenpäin. Koen, että tehokkuus antaa anteeksi joukkoon mahtuvan väärän tiedonkin. Joudun kyllä ennen pitkää väärän tiedon kanssa törmäyskursille oikean tiedon kanssa. Silloin se oikea tieto voi jättää jopa syvemmän muistijäljen ja tuottaa paremman ymmärryksen, kuin jos törmäisit oikeaan tietoon ilman mitään ennakko-oletuksia aiheesta. Kyse on ehkä asenteesta tietoon. Itsellä on aika filosofinen ote tietoon, en ole tietosanakirja.

{kind=link}