Ainakin minun mielestä se optimointi on tällä hetkellä kaikista tärkein osa-alue, koska rauta ei kehity ennen vuotta 2024-2025 ja ei kenelläkään yksilöllä ole varaa pistää kymmeniä miljoonia euroja uuden LLM-mallin rakentamiseen. LLaMAn lokaalin hostauksen osalta koko homma muutenkin pyörii ihan muutaman yksilön ja yhteisän varassa, joilla on varaa ja osaamista ostaa laskentatehoa hienosäätämään LLaMAa ja luoda siitä aidosti käyttökelpoisia malleja.
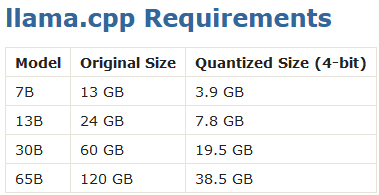
Kaikki laskentateho kyllä tullaan käyttämään ja oikeastaan käytetään jo nyt. Ellei ole joku hyperspesialisoitu malli, niin näistä tulee minun kokemukseni mukaan arkikäytössä aidosti hyödyllisiä vasta tuossa 30B parametrin kohdalla, joka vaatisi GPU:lta yli 60 GB VRAM. Kallein kuluttajamalli Nvidialta (koska AMD ei toimi hyvin) sisältää vain 24 GB kuumana käyvää GDDR6X, joten ilman optimointia ei oikeastaan pyöri edes tuo 13B.
Onneksi keksivät alkaa kvantisoida malleja, koska parametrien lisäys kompensoi moninkertaisesti sen epätarkkuuden, mitä alhaisemmista bittimääristä tulee. 65 B kvantisoituna vaatiikin sitten jo että osan kuormasta heittetään CPU & RAM ja varaa tarpeeksi pagefilea, että mallin saa ylipäätään ladattua. Väkisinkin hitaampaa kuin näytönohjaimella leikkiminen, mutta jos alta löytyy kaverina uusin Intelin i9 ja 128 GB nopeaa keskusmuistia, niin kyllä ihan siedettäviin vauhteihin silloinkin päästään.
Pitää toivoa, että Nvidia vihdoin alkaa tuoda järkeviä muistinlisäyksiä näytönohjaimiin myös kuluttajapuolella ja että saisimme kuluttajapuolella vihdoinkin 48 GB VRAM näytönohjaimen vuonna 2024. RTX A6000 48 GB ammattilaisille maksaisi 6500 €, joten tämä harrastus menee muuten pitkälti arvosijoittajan ulottumattomiin
Itse pelkään pahoin että NVIDIA katteiden perässä tahallaan “rampauttaa” kuluttajakortit LLM-käytön osalta niin että seuraavassakin sukupolvessa jäädään sinne 24-32GB nurkille pelikorttien lippulaivassa ja ne jotka haluavat enemmän joutuvat siirtymään ammattikortteihin ja ammattikorttien (3-4x) hintalappuihin. Tämä on NVIDIAlle loistava tapa segmentoida markkinaa ja taatusti hyödynnetään ellei kilpailu pakota tekemään toisin.
Eli jos haluaa tilanteen olevan toisin, pitää rukoilla Lisa Sun suuntaan ja toivoa että sieltä tulisi 64GB Radeonia joka pakottaisi nahkatakkimiehen peliliikkeisiin.
Oikeastaan sanoisin, että nyt jo ollaan tilanteessa, jossa aikahorisonttien lyhenemisen myötä tulevaisuuden projektioiden tekeminen muuttuu aina vain vaikeammaksi. Jopa 5-10 vuoden hahmottaminen tulevaisuuteen menee aika hankalaksi. Luin vähän aikaa sitten erilaisia artikkeleja noin 5-10 vuoden takaa, joissa yritettiin hahmottaa tekoälyn kehitystä eteenpäin. Usein niissä esimerkiksi oletettiin melkein varmana asiana, että pian rekka-autoliikenne automatisoidaan, mutta kukaan ei ennakoinut copywriterien tai graafikoiden hommien olevan ensimmäisenä.
Usein sellaiset asiat, jotka vaikuttavat helpoilta ihmisille, voivat olla vaikeita toteuttaa AI:lle ja toisinpäin. Voidaan myös miettiä, mikä kielimallien tilanne oli 5 vuotta sitten ja koettaa ekstrapoloida samaa kehitystä tulevaisuuteen, niin aika isot muutokset tuossa olisi kyseessä. Muistan kun Geoffrey Hinton käytti yhdessä haastattelussa ilmaisua, että tulevaisuudessa vallitsee tavallaan eksponentiaalinen sumu – lähelle näkee kohtalaisen hyvin, mutta jonkin matkan jälkeen ei voi enää tietää oikein mitään.
En ole vuosiin oppinut niin nopeasti asioita kuin ChatGPT:n avulla. Sen vastaukset ovat selkeitä ja ytimekkäitä. Voi kysyä täsmennyksiä. Tämä voittaa Googlen niin monella tapaa, myös perinteisen luokkaopetuksen monella tapaa, että en ala edes luettelemaan.
Itselle aukeaa tavallaan ahdistava näkymä tästä. Ne, jotka luonnostaan kyselevät ja ihmettelevät asioita paljon ja ottavat niistä selvää, ne voivat näiden työkalujen avulla alkaa valonnopeudella erkaantua niistä, jotka eivät ole kiinnostuneita. Kun tajusin sen nopeuden, millä omaksun uusia asioita tämän avulla, en ollut yksinomaan ilahtunut vaan myös ahdistunut. Olen aina lukenut kirjallisuutta ja selvittänyt juttuja wikipediasta, katsonut dokumentteja, mutta tämä tuntuisi paljon tehokkaammalle tietyssä mielessä, toki poistamatta tarvetta edellisille tai korvaamatta niitä. Se ikään kuin täyttää vuosien saatossa syntyneitä tiedollisia aukkoja ja kun ne täyttyvät, kokonaisymmärrys kehittyy samalla.
Jossain kohtaa tulee vastaan ihmisen kapasiteetti. Ihminenhän on huono muistamaan. Asiat jotka osasit hyvin 20 vuotta sitten, mutta et käyttänyt sen jälkeen, ei ole ihan tuosta vain takaisin muistissa. Ehkä juuri sen takia, että sitä tilaa ei nyt niin hirveästi ole kaikenlaiseen toisiinsa liittymättömiin (isoihin) asioihin. Aivojenhan käsitetään toimivan parhaiten kun se yhdistelee jollain tavalla liittyviä asioita toisiinsa uusissa yhteyksissä. Sitten kun aletaan miettiä tilannetta, jossa jokainen olisi AI:n myötä vaarassa muuttua monen alan ekspertiksi ja ahdistua siitä, voikin loppua tila?
Eli oikeastaan näen vaarana toisen suunnan, joka on jo ollut aika totta kun internetistä tuli yleiskäyttöinen. Tekoälyn myötä kukaan ei jaksa perehtyä asioihin, kun voi vain helposti kysyä tekoälyltä sen (vrt. “miksi opetella vaikeita juttuja kun voi laskea laskukoneella?”, “miksi painaa mieleen asioita jotka voi googlettaa 5 sekunnissa?”). Koska tulee se toinen viiva vastaan, että kukaan ei enää osaa itse mitään, kun kaikki pitää kysyä tekoälyltä? Homo scientia dementicus?
Sillä tuntuu olevan faktat riittävän hyvin hallussa. Olen tankannut historiallisia ja eri maihin liittyviä faktoja. Mitä erikoistuneempaan tietoon mennään, sitä varauksellisempi pitää olla.
En pidä ongelmana kahta esitettyä, muistikapasiteetin rajallisuutta ja mahdollista virheellistä tietoa:
Tieto lisääntyy yhtä kaikki ja ennen kaikkea lisääntyy ymmärrys, sillä tuon avulla voi tilkitä avoimeksi jääviä kysymyksiä. Usein esimerkiksi kirjan lukeminen herättää yhtä paljon jatkokysymyksiä kuin antaa vastauksia. Wikipedia on ollut yllättävän heikko työkalu tässä tarkoituksessa. Parhaiten palvelee lyhyt ja ytimekäs tieto, jota voi halutessaan tarkentaa.
Kirjan lukeminen herättää jatkokysymyksiä, mutta mistä se tieto sitten pitäisi hankkia. Kaikki muistaa, kuinka wikipediaa syytettiin ja yhä syytetään väärästä tiedosta, tai että se ainakin voi olla väärää. Pitäisikö ChatGPT:n faktat tarkistaa Wikipediasta vai mennä yliopiston kirjastoon. Mielestäni väärää tietoa ei tarvitse pelätä ja johonkin on tyytyminen, että asiassa päästään eteenpäin. Koen, että tehokkuus antaa anteeksi joukkoon mahtuvan väärän tiedonkin. Joudun kyllä ennen pitkää väärän tiedon kanssa törmäyskursille oikean tiedon kanssa. Silloin se oikea tieto voi jättää jopa syvemmän muistijäljen ja tuottaa paremman ymmärryksen, kuin jos törmäisit oikeaan tietoon ilman mitään ennakko-oletuksia aiheesta. Kyse on ehkä asenteesta tietoon. Itsellä on aika filosofinen ote tietoon, en ole tietosanakirja.
Ainakin, jos vaivautuu tutkimaan, onko tällainen lähde oikeasti olemassa. ChatGPT alkoi hallusinoida pätevän kuuloisen tieteellisen artkkelin pätevän kuuloisten tutkijoiden tekeminä, kun siltä tivasi lähdettä. Varmaan oikeita ihmisiä sinänsä, mutta ilmeisesti tekoäly on vain tyydyttääkseen kysyjää yhdistellyt tieteellisten artikkelien otsikoita ja tekijöitä. Ainakaan internetistä ei tavallisin hakukonein löytynyt.
Onkohan jo dark webiä hyödyntävä tekoäly tulilla?
On tosiaan havaittavissa, että lähitulevaisuudessa jotkut voivat vaikka kymmenkertaistaa oman tuottavuuden näillä työkaluilla. Kilpailupaine ajaa vielä automatisoimaan kaiken mahdollisimman nopeasti, ja jos ei tee noin, niin kilpailijat vie markkinat. Hieman rupeaa mietityttämään, mihin tämä kaikki on menossa.
Yksi ala joka on tähän mennessä ehkä tehostunut eniten generatiivisen AI:n myötä on peleihin liittyvä design ja sisällöntuotanto. Tuo artikkeli on viime vuodelta, niin siinä ei edes ole uusimpia asioita, mutta antaa varmaan suuntaviivoja.
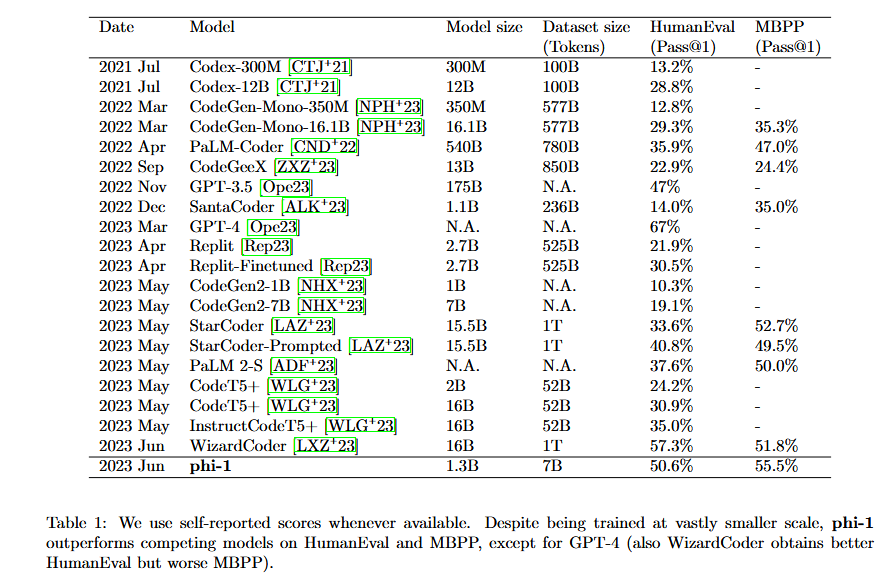
Datan laatu on kaikki kaikessa. Juhlitun WizardCoderin julkaisusta on kulunut vain viikko, mutta jo nyt se alkaa näyttää pahasti vanhentuneelta. Juuri julkaistussa paperissa phi-1 vaikuttaisi pääsevän samalle tasolle, mutta aivan mielettömän pienellä 1.3 miljardin parametrin kokoluokalla.
Noin pienen mallin pyörittämisen tietokonevaatimukset ovat täysin mitättömät ja se pyörisi varmaan jollain peliläppärillä. LLaMA:n julkaisusta on parin päivän päästä kulunut 4 kuukautta ja nämä kuluneet kuukaudet ovat olleet aivan pähkähulluja ihan millä mittapuulla tahansa. Mitähän uutta ne taas mahtavat keksiä ensi viikolla?
Kunhan avoimet koodimallit vielä hieman paranisivat, niin jaksaisi jatkaa omien sijoitustyökalujen jatkokehitystä tekoälykoodiorjan avulla ja sitten voisi alkaa kouluttaa LoRA:lla toisen tekoälymallin lukemaan vuosikertomuksia, niin saisi varmaan poimittua pörssistä matalalla roikkuvat hedelmät minkä löytämiseen ei tällä hetkellä vapaa-aika riitä. En usko että keskimääräinen salkunhoitaja oppii käyttämään tekoälyä hyödyksi sijoittamisessa ainakaan seuraavaan 10 vuoteen, joten tässä pitäisi olla hyvin aikaa repiä ylituottoja nörtteilyllä.
Täytyy sanoa, että pyöriteltyäni muutamaa kielimallia vajaan parin viikon ajan omalla koneellani jatkan edelleen tyytyväisenä ChatGPT:n käyttäjänä.
Asensin ensimmäisenä Githubin Llaman ja Alpacan Linux-koneelleni. Asennuskokemus oli Linuxille tyypillinen; node.js ja Python piti päivittää uusimpiin versioihin, taisi olla näiden lisäksi vielä jotain muutakin tavanomaista säätöä.
Lähdin testailemaan llaman 7B ja 13B -malleilla. Testailtuani jonkin aikaa sain vähitellen malleista jotain järkevää ulos kohtuuajassa. Asetusten säätöä riitti, jotta koneesta sai edes hitusen tehoista tähän käyttöön, enkä ollut lopputulokseen kaiken säädön jälkeenkään erityisen tyytyväinen. ChatGPT:tä syytettiin hallusinoinnista etenkin aluksi, mutta asentamieni mallien kanssa vaikuttaa siltä, että nämä mallit ovat jatkuvasti pöllyissä tai aineissa verrattuna ChatGPT:n uusimpaan versioon.
Sain tekosyyn lopettaa testailun sillä koneen käyttislevy, terainen Samsungin M.2 980 PRO oli uhkaavasti täyttymässä isojen kielimallien asennuksen jälkeen ja tilasin Amazonista Corsairin nopeimman 2TB:n levyn tilalle. Levyn toimituksen piti olla eilen, mutta onnekseni se oli päätetty lähettää samaan aikaan jonkun samassa tilauksessa olleen pilleripurkin kanssa ja tuleekin vasta maanantaina. Ajatuksena on testailla vielä isommilla (30B, 65B) malleilla jahka saan levyn vaihdettua.
En ole (enää) erityisen innokas säätämään kaikkien juttujen kanssa loputtomiin, joten asenteessani tätä kokemusta kohtaan saattaa olla korjattavaa. On tietenkin hienoa, että tämäkin puoli kehittyy nopeasti, mutta palasin mielelläni arkeen ja ChatGPT:n pariin päivittäisissä tarpeissa.
En epäile etteikö nämä kotikoneellakin pyörivät mallit voisi haastaa LLM-palveluita jonain päivänä. Erityisen mielenkiintoista olisi mahdollisuus opettaa mallia itse johonkin erityistarkoitukseen, vaikka sijoittamiseen. Tähänastisen kokemukseni perusteella ei olla vielä siinä pisteessä.
Mahtavaa että pääsit testailemaan! Muutama huomio ennen kuin teet johtopäätöksiä:
Llamaa ei ole tarkoitus käyttää itsessään, vaan jotain sen pohjalta koulutettua mallia. Alpaca taas on kolme kuukautta(!) vanha malli, joten se kuvastaa sen aikaista primitiivistä tilannetta. Kokeile mielummin vaikkapa guanacoa tai oikeastaan ihan mitä tahansa uudempaa mallia. Models - Hugging Face
Säädön osalta olet tietysti oikeassa ja teknologia kehittyy niin kovaa vauhtia, että säätämään väkisinkin joutuu ennen kuin saa homman pelittämään, kun nopeasti muuttuvaa softaa ei kannata rakentaa peruskäyttäjää varten. ChatGPT 3.5 on peruskäyttäjälle tällä hetkellä ehdottomasti riittävän hyvä, mutta teknisesti orientoituneelle hyvän tietokoneraudan omaavalle käyttäjälle nuo paikalliset mallit ovat jo menneet siitä kovaa vauhtia ohi.
Oikea diktomia ei tässä yhteydessä ole local vs remote tai local vs cloud vaan custom vs generic tai tailor-made vs one-size-fits-all. Myös custom mallia voi ajaa cloudissa. Asialla on paljonkin merkitystä, jos joku harmittelee, kun kotikoneen rauta ei riitä custom mallille. VM:n GPU:lla tai pelkkää GPU laskentaa voi ostaa cloudista.
Mulla ei ole omassa koneessa GPU:ta, mutta jos töissä tarvitsen GPU laskentaa niin CSC:llä meillä on käytössä GPU VM. Remote execution hommelit toimii VS Codesta ihan näppärästi. Joskus aiemmin piti tehdä tahmaisia remote IDE ikkunoiden tunnelointeja. Onneksi näihin ei ole enää tarvetta vaan IDE toimii nopeasti, koska se on lokaalina ajossa ja koodi taas pyörii remote päässä.
Itellä on AI huuma hiukan laskussa. On tullut vähän kyseenalaisiakin kokemuksia. Toki kokonaisuutena reilusti plussan puolella.
Pyysin ChatGPT neloselta ehdotuksia nopeasti isolla datalla toimivasta koneoppimisen mallista yhteen ongelmaan. Korostin vielä näitä reunaehtoja. No itsevarmaan tyyliin sieltä tuli ideoita jotka ChatGPT avulla koodasin. Kun proto oli valmis totesin että aivan liian hidasta. Eikä siis edes vähän liian hidasta vaan käyttökelvotonta. Olisi voinut toimia, jos dataa olisi 10k riviä, mutta kun dataa oli luokkaa 10M riviä. Onneksi yksi mun teamin jäsen keksi nopeamman custom algon ja päästiin eteenpäin. Ainahan tästä voi syyttää opetusaineistoa. Suurin osa geneerisistä koneoppisen algoista on toteutettu ja testattu pienillä dataseteillä eikä ne sitten aina oikein skaalaudu. Koska algot on geneerisiä on mahdollista keksiä custom datalle nopeampia ja tarkempia toteutuksia. Toisekseen koneoppimisen kentällä usein unohdetaan mitata algojen nopeuttaa vaan raportoidaan F1, Acc, Auc-Roc jne. Suoritusnopeus jää usein sivulauseeksi jos edes siihen.
Kokeilin myös midjourney:ta kuvien generointiin. 20 minuuttia jaksoin tapella, mutta en saanut edes lähellä mun päässä ollutta visiota kuvaksi.
Töissä on myös projekti missä kvalitatiivista dataa koitetaan luokitella GPT3.5:n avulla REST rajapinnan läpi. Yllättävän hyvin se toimii, mutta aina välillä homma menee sekoiluksi. Ja jos luokiteltava aineisto on 10k riviä niin 5% virheitä on sekin 500 riviä ja kun ei edes tiedä missä ne virheet on.
Tuntuu myös että autolomareissujen suunnitteluun tämä ei oikein taivu. Teoriassahan AI:n pitäisi pystyä tekemään sulle reitit, kertoa nähtävyydet, varata majoituksen jne. Käytännössä ei oikein mitään näistä. Ei ainakaan laatutasolla mitä itse haluaisin. Kaupunkilomien kohteita sillä voi etsiä, mutta kohteiden saamisen jälkeen patikointireitit on pakko tarkastaa.
Talvella pohdittiin, että missä mahtaa olla kilpailevat mallit, kun tulee kesä. No on niitä ilmestynyt, mutta lähes kaikissa tehtävissä ChatGPT4 on leaderboardin kärjessä. Softa-ala on aina ollut ”winner takes it all”-markkina. Käytännössä järkevät vaihtoehdot ovat ChatGPT4 tai custom mallit jotka räätälöit jollain datalla tai tehtävällä. Muille markkinatarjokkaille Bing, Bard, jne ei taida olla kysyntää. Jään odottamaan miten tuoteisiin integroidut mallit pärjää.
Olet oikeassa että tuo geneerinen vs räätälöity on tärkein kysymys, mutta myös lokaalin ajamisen leviäminen on aidosti tärkeää tekoälyn käytön yleistymisen kannalta, koska työhommia ei voi ajaa pilvessä tietosuojan takia ja ollaan vielä todella kaukana siitä pisteestä että työnantajat maksaisivat työntekijöille firman sisäisiä tekoälypalvelimia. ChatGPT:stä saatiin jo varoittava esimerkki aiemmin, kun keskustelut vuotivat muiden käyttäjien näkyviin, puhumattakaan siitä että OpenAI:lla pystyvät muutenkin seuraamaan käytyjä keskusteluita. Peruskäyttäjä tai vähän edistyneempikään ei todellakaan deployaa pilveen laskentatehon saamiseksi, vaan jos koti- tai työkoneen rauta ei riitä pyörittämään, niin homma jää kokonaan sitten siihen.
Nuo negatiiviset kokemuksesi ovat hyviä esimerkkejä siitä, miten tekoälyä yritetään tällä hetkellä käyttää täysin väärin ja tähän törmää muuten jatkuvasti ihmisten kanssa keskustellessa. Nykyiset mallit ovat pitkälti jokapaikanhöyliä, joiden tarkoitus on tehdä melkein mitä tahansa asiaa ihmiset niiltä keksivätkään vaatia siedettävällä tasolla. Tämä on itsessään jo aivan uskomatonta, kun ottaa huomioon miten monipuolisesti tietokone pystyy vastaamaan kummallisiinkin kysymyksiin tai piirtämään kuvia käytännössä reaaliajassa, mutta jostain syystä ihmisten lähtökohta on pyytää tekoälyä tekemään jotain hyvin äärimmäisen spesifiä ja pettyä kun se ei onnistu.
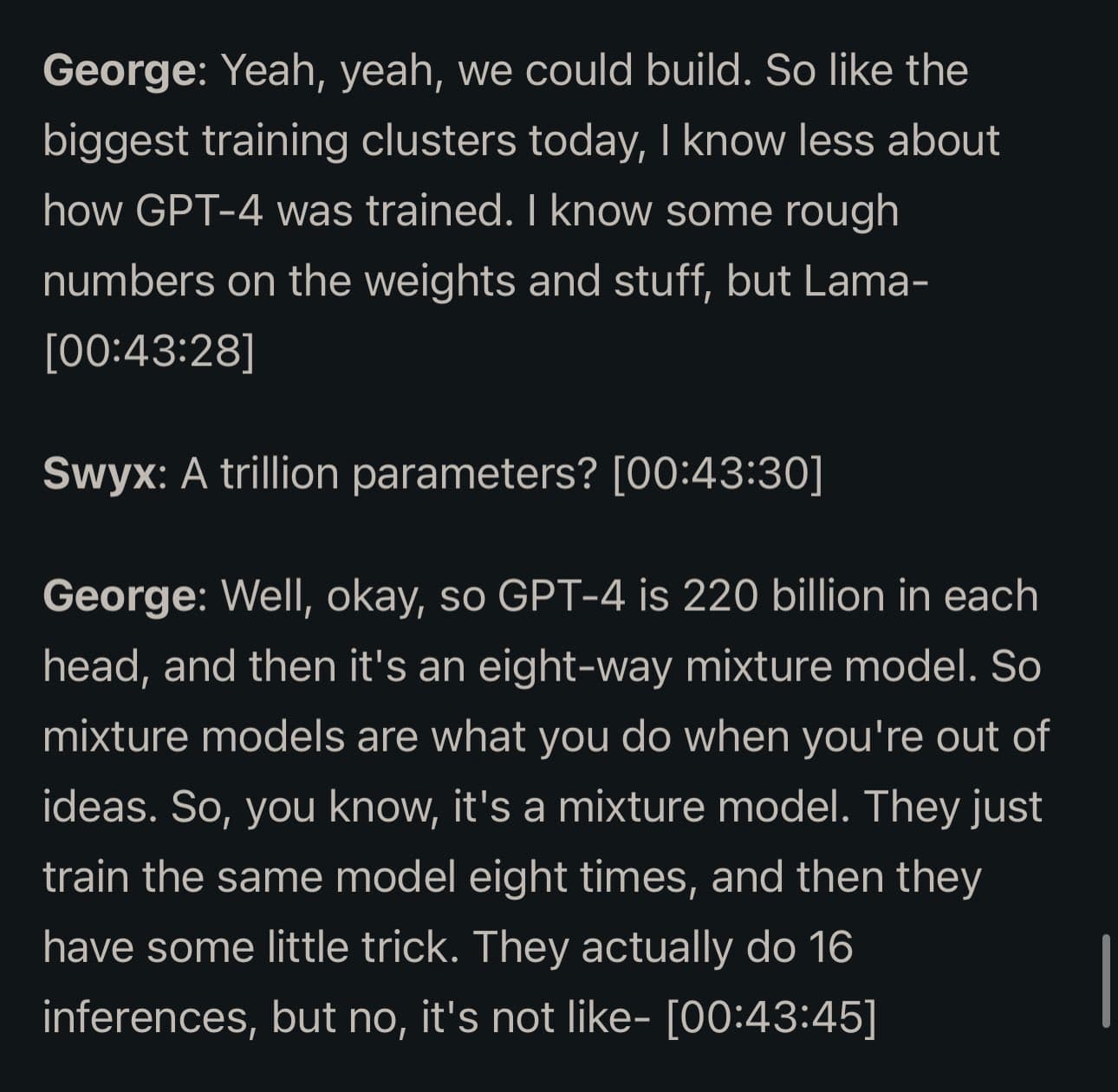
OpenAI:lla ei kuitenkaan ole minkäänlaista tuotteellista kilpailuetua tässä kisassa, vaan he ratsastavat lähinnä brändin ja suuren rahoituksen voimalla. GPT 3.5, Bard yms. ovat jo täysin geneerisiä ja triviaalisti replikoituja tuotteita. GPT-4 on vieläkin ylivertainen, mutta se johtuu siitä että OpenAI oikeasti heitti koko datatiskialtaan malliin ja tunki sen GPU-tehosekoittimeen. Katso nyt näitä George Hotzin mainitsemia speksejä:
Millään muulla firmalla ei tällä hetkellä ole realistisesti kykyä tai halua polttaa rahaa niin paljon kuin OpenAI tuohon käyttää, mutta ero GPT-4 ja kilpailijoiden välillä kapenee hirmuista vauhtia ja räätälöidyt mallit ja LoRA:t tulevat hyvin nopeasti pyyhkimään nelosella lattiaa spesifeissä tehtävissä. Sanoit sen itse toukokuussa hienosti, kun siteerasit Googlen vuodettua dokkaria:
Winner takes all voi olla jossain määrin totta, mutta ensimmäinen harvoin on se voittaja. Eikö ole kuitenkin todennäköisempää, että OpenAI on tekoälyn AltaVista?
No näinhän tää homma menee elokuvissa, mutta tällä hetkellä ollaan vähän toisenlaisessa tilanteessa. OpenAI kuitenkin polttaa miljardeja antaessaan puoli-ilmaisen tekoälyn maailman käyttöön ja heiltä puuttuu vielä se rahaa takova tuote ja ylipäätään bisnesmalli jolla tehdä tuloja.
OpenAI:n tekoäly-tsättibotti on tuotteena aivan liian geneerinen ja helposti replikoitavissa tehdäkseen merkittävästi rahaa, mutta ei sitä oikein alaskaan voi ajaa kun ovat vahingossa saavuttaneet markkinajohtajuuden, joten ainoa vaihtoehto on polttaa kassaa ja toivoa että keksitään jotain uutta millä tehdä riihikuivaa. Ehkä sivun voisi laittaa täyteen mainosbannereita ja asiakasdatan voisi jotenkin myydä mainostajille?
Myspace kohtasi Facebookin, AltaVista Googlen, Nokia Applen ja IBM Microsoftin. Ei kannata yliarvioida ensimmäisen liikkujan etua, koska seuraavan sukupolven yritykset usein tulevat markkinoille terävämmällä bisnessuunnitelmalla ja paremmalla tuotteella kaapaten ison osan aikaisemman ’voittajan’ markkinaosuudesta. OpenAI:lla on tunnettavuus ja brändiarvo, mutta uusia ChatGPT 3.5:sta parempia malleja tulee sitä vauhtia, että kaikki haaveet monopoleista voi jo unohtaa. Ylipäätään OpenAI:n yleismallit ovat huomattavasti huonompia, kuin yksinkertainenkaan tehtävään kustomisoitu malli. Nyt heidän pitäisi jotenkin konvertoida markkinaosuus rahaksi julkaisemalla jonkinlainen seuraavan sukupolven maksullinen tuote, mikä ikinä se sitten onkaan.
Kilpailijoiden kehityksestä kun puhutaan, niin mosaicml julkaisi 30B-mallin, jossa on peräti 8k tokenin konteksti yleisemmän 2k tokenin sijaan. Tämän mallin raaka historiamuisti tulee siis olemaan aivan eri tasoa
On kieltämättä söpöä, että joku vielä herran vuonna 2023 Microsoftin kaltaiselta yritykseltä miljardeja kehitystyöhön saaneella yrityksellä olisi strategiaa, mitä nykyisen version julkaisulla haetaan.
Alustataloudessa ei pitäisi olla mitään uutta sijoittajille. Alkaa olemaan tuttua kamaa jo 2010-luvulta.
Tälläkin hetkellä varmasti moni testailee, mihin kaikkeen sitä ohjelmaa voisi käyttää. Dataa jota ihmiset tuottavat, kysymyksiä joita he tekevät aivan varmasti analysoidaan ja muokataan hyvin kannattaviksi bisnesmalleiksi.