Ettei lipsahtaisi hiukan fake news osastolle? Joka ainoassa leaderboardissa jonka olen nähnyt on GPT-4 kärjessä tai vähintään top-3:ssa. Aiemmin itse postasit koodaus benchmarkin jossa gpt4 sai 67% vs paras kustomisoitu malli 57%.
Orca mallista oli paljon hehkutusta pari viikkoa sitten, mutta senkin jää vielä kauas gpt4 taakse.
Perässä tulevat mallit kuten Orca ovat pienempia, mutta ne on monasti treenattu käyttäen OpenAIn malleja.
Apple oli ensimmäinen joka toi laajaa menestystä saaneen kosketusnäytöllisen puhelimen markkinoille. Kuka kukisti Applen? Ei kukaan. Microsoft toi ekan käyttöjärjestelmän koti pclle ja x86 arkkitehtuurille. Kuka kukisti Microsoftin koti pc markkinassa? Ei kukaan. Sopivasti kun sahailee niin saa sellaiset tulokset kuin haluaa
Tällä hetkellä se että muut tekee omat mallinsa kopiomalla OpenAI:n mallien vastaukset ja se että heillä on jo plugin ekosysteemi käynnissä tekee heistä selvän markkinajohtajan. He ovat se mittapuu jota muut jahtaa. Ja kaikki data tästä menee OpenAIn seuraavan version tekemiseen. En näe välitöntä, sanotaan vaikka seuraavan 6kk uhkaa heille, mutta jos postaat ne tulokset missä custom mallit pyyhkii gpt4:llä lattiaa niin olen valmis muuttamaan mieleni.
Ymmärsit nyt viestini väärin ja hämmennyin myös tuosta vastauksestasi, joten yritetään uudestaan.
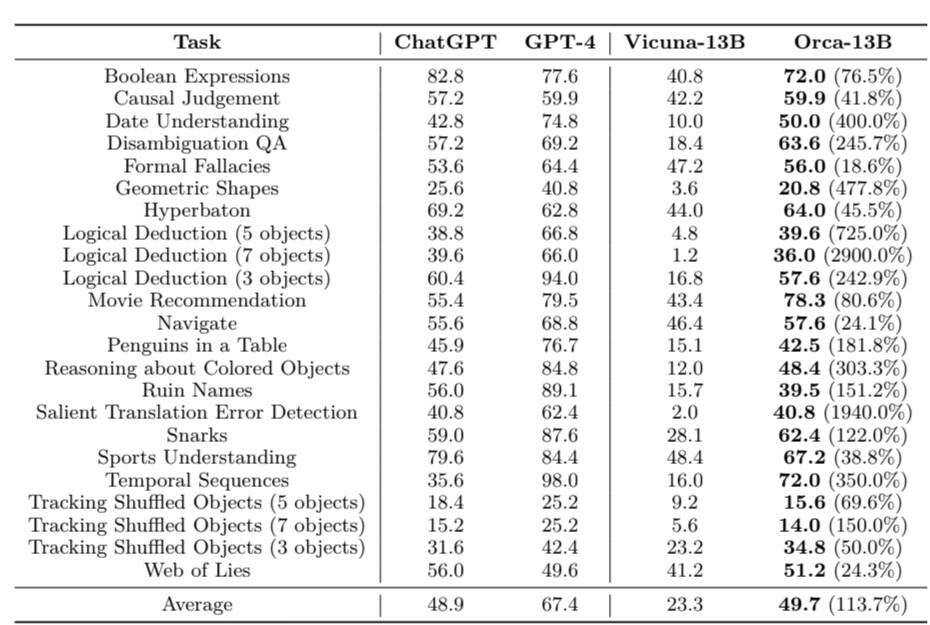
Tuossa kuvassa vertaat GPT-4 sellaisiin yleismalleihin, kuten Vicuna-13B ja Orca-13B, joissa on käytetty korkeintaan joitain prosentteja siitä datamäärästä mitä GPT-4:ssa. Pelkästään hyppy 13B —>30B on yleensä aivan valtava mallin kyvykkyydessä, joten jos Orcaakin skaalattaisiin riittävästi ylöspäin, niin voisi olettaa GPT-4 jäävän tappiolle noissa testeissä.
Toisaalta OpenAI:n puolustukseksi julkiset testit ovat epäluotettavia, kun nykyään malleja ylioptimoidaan nimenomaan testeihin, joten GPT-4 etumatka tosielämän sovelluksissa on suurempi kuin miltä paperilla näyttää. Suosittelisin siksi tekemään omat testit ja olemaan jakamatta niitä julkisuuteen, jos malleja haluaa aidosti vertailla keskenään. Omasta mielestäni esimerkiksi WizardLM on huomattavasti huonompi, kuin mitä sen paperilla pitäisi olla.
Koska olemme sijoitusfoorumilla, niin ajattele GPT-4 kyvykkyyttä ns. ’Circle of competencena’. Kun ollaan keskellä ympyrää, niin vastausten tarkkuus on 100% ja ulkokehää kohti mentäessä lähestytään nollaa ja rajan yli mennessä tehtäviä joita GPT-4:lla ei voi suorittaa ollenkaan. Tuolla ulkokehän maastossa räätälöidyt mallit dominoivat ja jopa kotikoneella jostain heikommasta mallista väännetty LoRA kykenisi päihittämään GPT-4:sen.
Kysymys on lähinnä siitä, että kuinka suuren osan kaikista maailman mahdollisista tehtävistä nämä jokapaikanhöylä-mallit kuten GPT-4 kykenevät kaappaamaan itsellensä. Nämä yleismallit eivät mielestäni tule olemaan hyvä bisnes, koska niissä ei voi oikein saavuttaa merkityksellistä kilpailuetua ja sen vuoksi OpenAI:n hinnoitteluvoima syödään, kun kilpailijat saavat heitä kiinni.
Pienemmillä malleilla on selkeitä eroja, jotka tarkka silmä voi huomata. Isoimmilla erot vähenevät ja tulevat ajan kanssa lähes katoamaan, jonka vuoksi kuluttajan tulee olemaan hankala vertailla niitä, kunhan ”tarpeeksi hyvä” -taso ylitetään. Ammattihommiin taas haluaisit näiden yleismallien sijaan tehtävään räätälöidyn mallin jolla päästäisiin 100% tarkkuuteen tai ainakin merkittävästi korkeampaan tarkkuuteen mitä yleismalleilla pystytään. Jos vaatimus on 100% tarkkuus ja GPT-4 saavuttaa 95%, niin se ei vaan riitä, puhumattakaan tehtävistä missä GPT-4 suoriutuu aidosti huonosti.
Ymmärrän, että sulle itselles näkyy tämä OpenAI:n kuukausihintainen sopimus ja tuntuu siltä, että se on se, millä OpenAI on lähtenyt markkinoita valloittamaan ja tienaamaan.
Hyvä kuitenkin huomata, että heillä on kumppaninaan ja merkittäviä summia sijoittanut Microsoft, jonka pääbisnes on yhä siellä yritysmaailmassa, vaikka ovat meiltä tavallisia tallaajiakin onnistuneet saamaan tilaajiksi.
Lisäksi johtoryhmässä on istunut Muskikin. Hänkin on varmasti tuonut omat näkemyksensä.
En usko, että tuleva liiketoiminta tulee eroamaan merkittävästi alkuvuosina muiden jenkkiteknojättien liiketoiminnasta. Ei vaadi mitään suurenmoista tutkimusta, että voi lähteä arvaamaan, että arvokkaampi tuote on tarkempi tieto siitä, mihin tuota voisi myydä ja mihin ihmiset sitä ylipäänsä käyttäisivät. Ihan älytön määrä liiketoiminta mahdollisuuksia, kun saa dataa siitä, miten ylipäänsä miljoonat ihmiset tuota haluaisivat tai keksisivät käyttää.
Joko voit myydä sitä dataa tai tuottaa tarkennettua tai tuottaa datan perusteella tuotteita.
Datatalouden uskotaan olevan arvokkaampi tulevaisuudessa kuin tuotetalouden. Yritysten kesken myös vaihtuu mukavampia summia rahaa kerralla kuin ihmisten kesken. Eiköhän ChatGPT:llä ole hyvä ansaintamalli ajateltuna vai uskommeko tämän olevan Bill Gatesin hyväntekeväisyysprojekti?
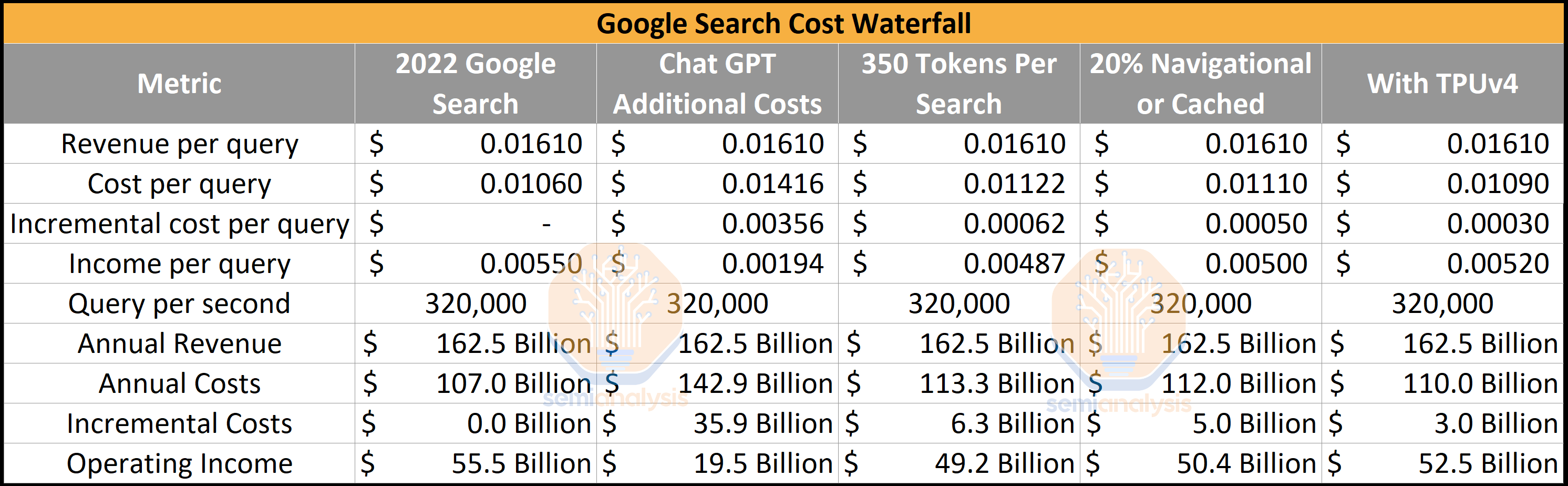
Tuon mukaan yksi kysymys maksaa 0.36$ OpenAi:lle. Olen omista lähteistä kuullut että chatGPT4 olisi noin kymmenen kertaa kalliimpi. On hyvin vaikea keksiä ansaintamallia joka tuottaisi lähellekkään tuollaisia summia. Joko hardwarea pitää saada paljon paremmaksi tai softaa tehokkaammaksi ainakin kaksi kertaluokkaa.
Edit: @Nortti1 tuon 0.36$ osalta en osaa sanoa mutta OpenAI kilpailijan suusta kuultuna oli väite että yksi query chatGPT4:lla olisi reilu kolme dollaria. Oma kompetenssi ei riitä arvioimaan lukua mutta kuulostaa hurjalta.
Melkoista persnettoa tekevät nykyhinnalla, jos tuo pitää paikkansa. OpenAI:n API-hinnastosta laskemalla tulee eri näköiset luvut. Ainoa kohta, joka täsmää on se että GPT4 näyttää olevan noin 20-30 kertaa kalliimpi kuin GPT3.5.
Jos olettaa että yksi kysymys on keskimäärin 20 tokenia ja vastaus 200 tokenia. API hinnalla toi tekisi kysymys-vastaukselle hintaa
GPT4: 0,6 + 12= 12,6/1000 = 0.0126$
GPT-3.5: 0,03 + 0.4 = 0,43/1000 = 0.00043$
Hinnat alla per 1k tokenia. Jos 0.36$ per kysymys-vastaus niin API hinta ei kata kuin muutamia prosentteja hinnasta.
Ainahan uudet softapalvelut on tehneet vuosikausia tappiota ennen kuin punnertavat itsensä voitolle. Sitten kun tehdään voittoa sitä, tuleekin reilusti, kun ollaan monopoliasemassa. Toki on paljon firmoja, jotka polttaa sijoittajan rahoja vuodesta toiseen, kuten Snap
Näin. Toisaalta esim. näitä Llama johdannaisiahan on parannettu ja fine-tunattu ChatGPT:n tuottaman datan avulla, joko luomalla suoraan GPT:n avulla riittävän määrän kysymys-vastaus pareja tai samplaamalla sopivan otoksen julkisiin lähteisiin tallennetuista ChatGPT-keskusteluista (esim. sharegpt.com). Että sikäli @Tunturisusi on ihan oikeilla jäljillä ideansa kanssa.
Lainaa pankista miljardi dollaria. Myy tämä miljardi dollaria 900 miljoonan dollarin hinnalla. Nyt sinulla on miljardi dollaria liikevaihtoa ja 100 miljoonan dollarin miinusmerkkinen tulos. Näin helppoa se liikevaihdon tekeminen on ja ensi vuonnahan voit tehdä saman tempun mutta isommalla summalla, niin liikevaihto saadaan kasvamaan näyttävästi. Liikevaihdon ostaminen myymällä tuotetta tappiolla on niin idioottivarma bisnes, ettei siinä voi kukaan epäonnistua ennen kuin VC:n rahat loppuvat.
Kaikki teknostartupit kertovat aina sitä samaa tarinaa, että se tappiollinen kasvuvaihe on vain väliaikaista ja jossain kohtaa rahavirrat kääntyvät positiivisiksi, mutta OpenAI:lta puuttuu tällä hetkellä se tie voitollisuuteen, koska sen palvelinkustannukset ovat niin mielettömiä. Tässä kohtaa hypesykliä kysyntää kyllä riittää mielettömästi ja yritykset ostavat palveluita ihan vaan etteivät vaikuttaisi jälkeenjääneiltä fossiileilta, samaan tapaan kuin vaikkapa virtuaalitodellisuuslasien kanssa oli yritysmaailmassa 4 vuotta sitten. ChatGPT:n historiallinen menestys oli suunnittelematon vahinko. Todellinen testi tulee siinä vaiheessa, kun siitä yritetään rakentaa aito bisnes ja palvelun hintoja päätetään nostaa breakeveniin tai jopa voitollisuuteen saakka. Minunkaan ei ole mitään järkeä maksaa Amazonille 3€/h oman AI-pilvipalvelimen pyörittämisestä, kun ChatGPT-3.5 saa ilmaiseksi ja API-calleina puoli-ilmaiseksi
Joo, toistaiseksi ne OpenAI:n käyttöehdot on systemaattisesti kierretty ja ChatGPT jatkuvasti open sourcen apuna, koska lainsäädäntö on niin epäselvää ettei siitä voida mitenkään rankaista. Varmaan tuohonkin ennen pitkää isketään jollain tavalla kiinni, mutta kilpailukenttä on jo siinä vaiheessa hyvin eri näköinen, eikä lampun henkeä saa enää takaisin pulloon.
Tämä on koettu lukuisia kertoja. Tienatakseen tällä pitää tunnistaa hype ja sillä ratsastavat yritykset. Ostaa osakkeita ja vähentää säännöllisesti, koska tietää paskan laukeavan tuulettimeen jonain satunnaisena hetkenä. Joku yritys sitten pärjää ja tekee uskomattoman tuloksen, mutta sen tunnistaminen etukäteen on mahdotonta sattumanvaraisuuden vuoksi.
Itse näen tämän ehkä hivenen eri tavalla. Eli kysymys, jota mielestäni kannattaa pohtia on onko OpenAI tarkoitus edes tehdä rahaa?
Tarkoitan tällä sitä, että tuo ChatGPT syksyllä markkinoille tulo ja siitä syntynyt kohkaaminen vaikuttaa kovasti MS:n markkinoinnilta. Ensin tuli tuo ChatGPT ja herätti hurjan kiinnostuksen ja sitten vuoden vaihteessa MS tuli markkinoille uuden Edgen kanssa, jossa oli heidän jonkinlainen erillinen versio GPT:stä. Sen verran pitkälle kehitetyltä tuo MS:n tuote vaikutti ettei sitä luotu ChatGPT 4.0 julkistuksen jälkeen.
Itse siis näen tuon OpenAI funktiona kahdella tavalla:
R&D talo, joka tutkii ja kehittää menetelmiä
Tuki markkinoinnille ja markkinoiden luomiselle
Tuo koko 4.0 version julkistushan käytännössä loi markkinat näille ratkaisuille, joihin MS pystyi näppärästi tarjoamaan omia ratkaisujaan. Oliko tämä vain sattumaa vai kenties mietitty markkinoille tulemisen strategia? Ja toki se on omistajien etu, jos OpenAI pystyy itse rahoittamaan toimintaansa asiakkaiden rahoittamana (siis kuluttajat ja yritykset, jotka maksavat OpenAI:lle palvelusta).
In a phone call with Insider, Patel said it’s likely even more costly to operate now, as his initial estimate is based on OpenAI’s GPT-3 model. GPT-4 — the company’s latest model — would be even more expensive to run, he told Insider.
Ei pidä paikkaansa. Dylanin alkuperäinen arvio on nimenomaan ollut tuo 700 000$ USD päivässä, seuraaviin oletuksiin perustuen:
Estimating ChatGPT costs is a tricky proposition due to several unknown variables. We built a cost model indicating that ChatGPT costs $694,444 per day to operate in compute hardware costs. OpenAI requires ~3,617 HGX A100 servers (28,936 GPUs) to serve Chat GPT. We estimate the cost per query to be 0.36 cents.
Our model is built from the ground up on a per-inference basis, but it lines up with Sam Altman’s tweet and an interview he did recently. We assume that OpenAI used a GPT-3 dense model architecture with a size of 175 billion parameters, hidden dimension of 16k, sequence length of 4k, average tokens per response of 2k, 15 responses per user, 13 million daily active users, FLOPS utilization rates 2x higher than FasterTransformer at <2000ms latency, int8 quantization, 50% hardware utilization rates due to purely idle time, and $1 cost per GPU hour.
Kuten kirjoitin, on tuo arvio jo vanhentunut koska OpenAI tarvitsee nykyään huomattavasti enemmän rautaa palvellakseen käyttäjiään. En tiedä mistä väittämäsi 70 000$/päivässä tuli, mutta tuon uuden googlettamasi linkin 100 000$/päivä arvion lähteenä taas on joku Goldsteinin viime vuotinen twiitti siltä hetkeltä kun ChatGPT saavutti ensimmäiset miljoona käyttäjäänsä…
Koska tämä keskustelu menee jo parodian puolelle, niin ohessa vielä laskelma siitä, että miksi Google ei voi vain heittää ChatGPT suoraan heidän hakukoneensa päälle. Hinta voisi olla kirjaimellisesti kymmeniä miljardeja dollareita.
Juhannuksena kun otettiin vähän kuppia ja parannettiin maailmaa, niin samalla mietittiin seuraavaa.
Jos Suomen kaikkien henkirikosten data syötettäisiin ChatGPT:lle tuomioineen päivineen, niin kuinkahan monen ”ratkaisemattoman” tapauksen se saisi ratkaistua. Toistoahan tekoäly vaatii ja tällä hetkellä tiedot eivät ole saatavilla netissä.
Toisaalta tekoäly osaisi tuomita paremmin kuin yksikään ihminen, kun tunteet eivät vaikuta. Tiedämme esimerkiksi naisten saavan samoista teoista lievempiä tuomioita kuin miehet, itkevien uhrien kertomusten olevan uskottavampia seksuaalirikoksissa kuin kivikasvoisten sekä tuomarien antavan kovempia tuomioita juuri ennen lounasta kuin lounaan jälkeen. Ihmisiä kun vaan ollaan.
Mitä? Eikö Juurikki oikeasti olekaan Jäniksen vuosi -elokuvan söpö pieni pupu?
Ihan oikein AI-jai päätteli. Ja vielä kahteen kertaan, joskin jälkimmäisen kohdalta hieman johdateltuna, että etkö muista aiempaa vastaustasi.
AI-jai on ratkiriemukas huumorikone - ja vielä siitä hyvä, että joka ainoa poliittinen puolue voi pian ostaa tekoälyn, joka varmasti pysyy oman puolueen tinkimättömissä periaatteissa. Siis vaikka kannattajat eivät niitä edes kannattaisi.
Joo, juuri näin. ChatGPT ei ole varsinaisesti tekoäly vaan kielimalli eli siis hakutapa. Ja itse data on indeksoituna ChatGPT:n ymmärtämään muotoon, josta haulla haetaan. No, toki tässä on elementtejä pidemmälle, esim. semanttinen haku pelkän indeksoidun haun lisäksi, mutta malli ei osaa päätellä mitään. Se vain rakentaa lauseet materiaalin kautta. ChatGPT:n hyvät sovellustuskohteet on enemmän tekstiin liittyvien hajanaisten tietorelaatioiden tunnistamisessa, mutta tossa on se ongelma, että kielimalli itsessään osaa kirjoittaa vakuuttavan tuntuisesti mistä tahansa. Miten sitten tunnistat oikean ‘rivien välissä olevan tiedon’.
ChatGPT:n käyttäjämäärät laskivat ensimmäistä kertaa. Artikkelissa mahdollisiksi syiksi esitetään tsättibotin laadun tietoinen laskeminen paisuvien kustannuksien vuoksi, käyttäjien siirtyminen avoimiin malleihin tai opiskelijoiden kesälomasta johtuva kausivaihtelu:
En ihan saa kiinni, mitä tuo tarkoittaa. Wikipedia kertoo näin Kielimalli
"Tilastollinen kielimalli on sanajonon sanojen todennäköisyysjakauma tai sellainen todennäköisyysfunktio, joka tuottaa jakauman…
Todennäköisyyksien avulla kielimallit osaavat muun muassa ennustaa, miten jonkin lauseen tulisi jatkua, vastata kysymyksiin"
GPT:ssä sanaston sanat eivät ole indeksoitu vaan ovat viimeisen vaiheen lähtöjä, joille jokaiselle lasketaan todennäköisyys
ChatGPT indeksoi sisällön, sen keskeisin määre on token, joka on joskus tavu, joskus sana jne. Oman datan sisällön indeksoinnilla on hintakin (1000 token vastaa noin 500-700 sanaa riippuen kielestä ja tämä on alin hinnoitteluyksikkö). Tähän indeksiin kohdistetaan haut ja esim. chatgpt:n suomen kielimallissa tämä on ainoa mihin voi kohdistaa hakuja. ChatGPT:n eri kielimallit ovat eri tasolla, joten esimerkiksi suomessa voi käyttää vain tuota indeksointia, eikä ollenkaan semanttista hakua, koska kielimalli on näiltä osin vielä kesken. Englanniksi voi käyttää molempia. Tietenkin indeksointi tarkoittaa laajempaa mallia kuin pelkkä sanaindeksi, mutta indeksointi-terminologiaa käyttää ainakin Microsoft kuvatessaan tuota datasisältöä, joka on järjestetty ChatGPT-hakuja varten.
Tekoäly on nykyisin atk-sanan tyyppinen kattotermi, jota nykyisin sovelletaan eri asioihin. Jos asiat käydään wikipedia tasolla, no siellä voidaan puhua mistä termistä vain. Jos keskustellaan taasen miten ChatGPT teknisesti toimii ja miksi se ei ole varsinaisesti tekoäly - vaikka se luokiteltaisiinkin de-facto terminologiassa AI-teknologioihin… Tämä on paljon mielenkiintoisempi itse teknologiaan keskittyvä träkki. Tämä luokitus kyllä näkyy ChatGPT:n wikipediasivuillakin : Type
Large language model
Generative pre-trained transformer
Chatbot
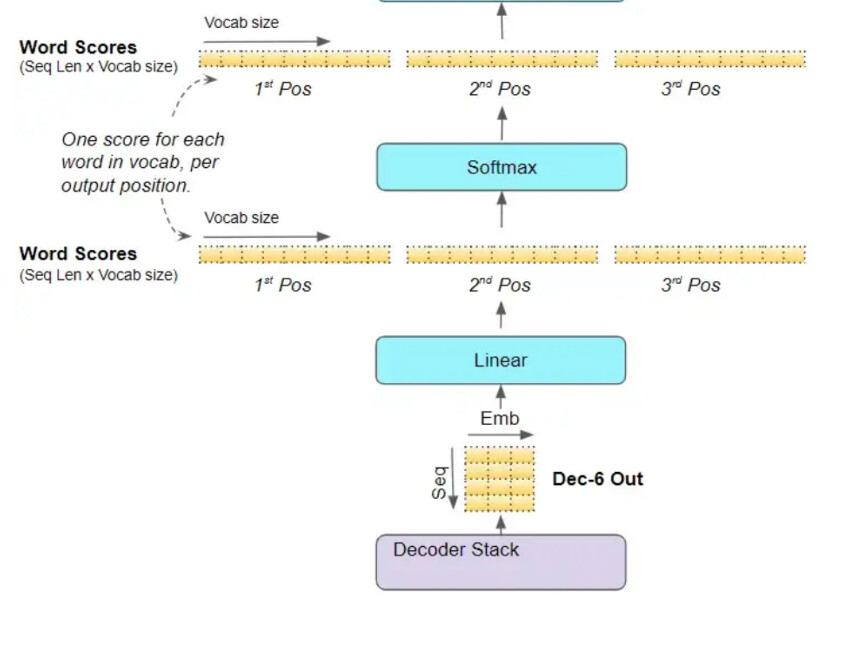
Itse olen ajatellut GPT-kielimallin toiminnan konseptitasolla jotenkin näin.
Sanat jaetaan tokeneiksi. Jokaista tokenia edustaa moniulotteinen (esim. 512) vektori, jokainen vektorin ulottuvuus vastaa kielellistä ominaisuutta.
Sisääntulossa token saa vectoriin alkuarvon Word embedding ja positional encodingilla.
Mallin opetuksessa kysymys syötetään vasempaan encoderiin ja generoidut vastaukset oikean puoleiseen Decoderiin.
Sen kuinka paljon GPT:n antama vastaus on väärä, säädetään parametreja.
Opetuksessa sanojen (tokenien) vektorien kielelliset ominaisuudet (vektorin arvot) säätyvät siten, että jokaisessa kielellisessä ominaisuudessa/ulottuvuudessa, samaa tarkoittavat sanat ovat lähellä toisiaan
Eli sanaston kaikki sanat ovat 512 ulotteisessa avaruudessa sijoitettuna kielellisten ominaisuuksiensa mukaisesti.
Tämä tapahtuu MultiHead attention lohkoissa.
Opetuksen jälkeen saadut parametrit otetaan tuotannossa käyttöön.
Tuotannossa kun GPT:ltä kysyy, ovat kaikki annetun vastauksen sanojen vektorit 512 kielellisine ominaisuuksineen peräkkäin, ja viimeisen kerroksen Linear layer on oppinut antamaan todennäköisyydet “jos peräkkäin on tuollaisia sanoja tuollaisilla kielellisillä ominaisuuksilla, on seuraavan sanan todennäköisyys tämä”.
Eli käsittääkseni opetuksessa säätyvät parametrit. Löydettyja arvoja käytetään tuotannossa. Parametrit säätyvät antamaan keskimääräisesti parhaan tuloksen.
Itse massiivinen data on opetuksessa.
Toki voi olla, että käsitykseni on ollut väärä ja pitää siirtyä Googlen käytöstä ChatGPT:n käyttöön
Sinänsä ei väliä, ehkä tuo indeksihaku on se todellinen toiminnallisuus