Älä suotta ota itseesi, tuo oli vaan oikeasti kovin hassu käännös
[…]
Take, for instance, word embeddings in natural language processing (NLP).
[…]
making vector databases an essential component of the generative AI puzzle.
vs.
[…]
Otetaan esimerkiksi sanan upotukset luonnollinen kielenkäsittely (NLP).
[…]
tekee vektoritietokannoista olennaisen osan generatiivisessa tekoälypulmapelissä
Terminologian suomentaminen on kyllä näissä tosi vaikeaa, koska vakiintunutta sanastoa suomeksi ei aina ole, tai ainakaan sitä ei tiedä jos ei sattumalta ole joskus osallistunut suomenkieliseen koulutukseen tms aiheesta (mikä on nykyään varmaan aika harvinaista kun yliopistoissa ja korkeakouluissa opetus on kansainvälistynyt). Upotukset, kuviot ja ominaisuudet on sinänsä ihan loogisia käännöksiä sanoille embeddings, patterns, features, mutta kahdesta jälkimmäisestä on hahmontunnistuksen yhteydessä ainakin taidettu kyllä käyttää käännöksiä “hahmo” ja “piirre”.
Termipoliiseilu ei suinkaan ollut miun tarkoitus, vaan se, että tuo käännös ei ole edes kieliopillisesti kohdallaan (ChatGPT 3.5:llä tulee jo sujuvampaa tekstiä), mitä korostaa se että kyse on tekoälyyn keskittyneestä sivustosta.
Ei miulla tuota lähdettä vastaan mitään ole, englanninkielinen versio vaikutti ihan pätevältä sen verran mitä nyt kykenen sisältöä arvioimaan (esim. se, että miten embeddings-mallit oikeastaan toimivat on miulle edelleen täysi mysteeri). Miulla ei myöskään ole mitään kritiikkiä osoittaa siun tekstiäsi kohtaan. Vektoritietokannat vaikuttavat hyvinkin käteviltä työkaluilta nimenomaan luonnollisen kielen kanssa, oli mukana chat-käyttöliittymää taikka ei. Hyvä esimerkki siitä, että vaikkei mitään yli-inhimillistä keinotekoista älykkyyttä ole saavutettu (eikä sellaista välttämättä koskaan saavutetakaan), matkan varrella syntyy kuitenkin hyödyllistä teknologiaa.
OpenAIn dev dayn key note menossa tai taitaa juuri loppua. Gpt4 turbo, uusia modaliteettejä ja helpompi mahdollisuus customisoida. Ei uutta vallankumousta, mutta kätevän näköisiä parannuksia.
Kylläpä täällä on oltu suolaisia. Taitaa setää harmittaa, kun nuoret jakkubroilerit vetää oikealta ja vasemmalta ohi?
Olen itse useamman kuukauden käyttänyt chat gpt-4:ää aktiivisesti niin töissä, kuin koulussa, jossa jatkokoulutan itseäni töiden lomassa. Missä chat gpt on hyvä?
Olen muuttanut kymmenien tuntien edestä kuvia ja PDF:iä CSV muotoon. Ihan pirun kätevä.
Kääntäjä on valovuoden translatea edessä. Sanakirja.orgit ovat historiallinen jäänne.
Tuore keskustelu moodipelaa melko hyvin. Voisin veikata, että muutaman vuoden sisällä potilaskertomukset ynnä muut kuormittavat tekstit muodostetaan suoraan taltioidusta potilastkäynnistä. Litterointi ja sen pureskelu on menneisyyttä.
Minulla on aikaisemmista koulutuksista kokemusta vain spss:tä. Nyt jatkokoulutuksessa tarvitsen R:ää. Chat gpt:n privaatti R-koodin harjoitteluistunnot ovat osoittautuneet vallan mainioiksi.
Noin 10 kertaa nopeampaa kysyä botilta vinkkejä excelin käyttöön, kuin googlailla.
Mitä Chat gpt ei osaa:
Chatpdf ja muut pdf:n lukuohjelmat eivät korvaa PDF:n lukemista.
Chat gpt vastaa usein tyhmää höpöä itsevarmasti. Niché aiheista etenkin.
Joku kysyi aikaisemmin, että mitä hyötyä siitä plussasta on:
Voit ladata plugineja. Esimerkiksi matkan suunnittelua, PDF:än tulkintaa tai datan analysointia varten onoomansa
Data analyysi pluginit ovat antaneet luotettavia vastauksia tilastotieteen ja mallinnuksen kursseissa. Ei ole oikeastaa ensimmäistäkään 1+1=3 virhettä tullut.
Botin kanssa on ihan mukava keskustella automatkalla, jos jokin asia alkaa askarruttamaan.
Ero ilmaisen ja maksullisen version välillä on mielestäni suuri, vaikka en oikein osaa selittää eroa. Ilmaisen kanssa turhautuu helposti.
Koska embeddings on GPT-kielimallin toiminnnan perusta, tarkennan asiaa. Olen samaa mieltä, että linkin takana oleva teksti on käännöksen jälkeen huono, mutta itse kuvateksti on asiaa selventävä, vaikka embeddings käännös on huono.
Luulen että tunnet embeddings-käsitteen kohtuullisen hyvin, et olisi muuten ottanut asiaan kantaa. Voit korjata asiasisältöä, jos tässä on virheitä.
Embeddings avaruudessa sanoja edustavat moniulotteiset vektorit. Mitä lähempänä sanojen merkitys on toisiaan, sitä lähempänä ne ovat tuossa avaruudessa.
Embeddings-avaruus luodaan neuroverkolla. Jos se tallennetaan vectorikantaan, sieltä voi hakea sanoja merkityksen perusteella (semanttiset haut). Haun voi tehdä vektorien etäisyyden perusteella
Vektorikantaan voi tallentaa erilaista tietoa, ei vain sanoja. Tietoa edustavat vektorit, joiden ulottuvuudet vastaavat merkitystä.
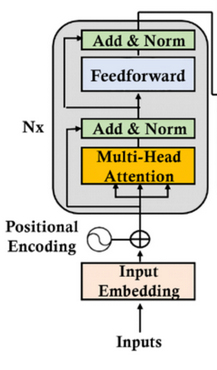
Samaa periaatetta käyttää GPT-kielimallin käyttämä Transformer.
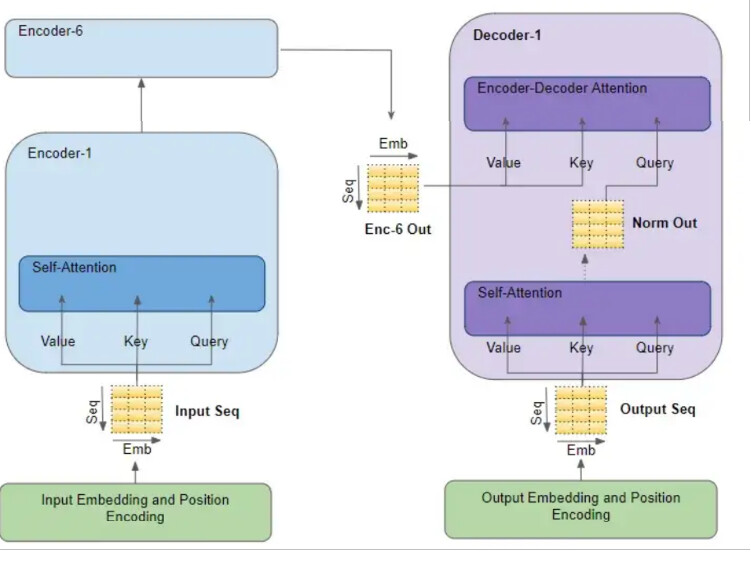
Tässä kuvassa Input-Embedding lohko, jossa Transformeriin tuodaan dataa muuttamalla data (esim. sanat) moniulotteisiksi vektoreiksi.
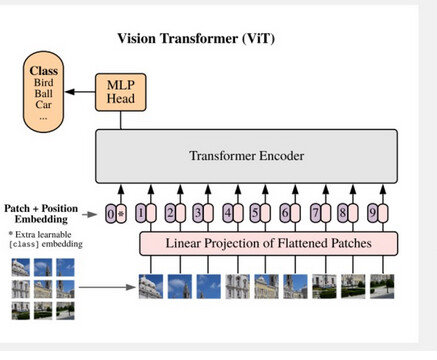
Tässä esimerkki Transformerista kuvien luokittelussa.
Siinä Input Embeddings-lohkossa osiin jaetun kuvan osiot muutetaan vektoreiksi. Opetuksen jälkeen noiden vektoreiden etäisyydet toisistaan kuvaavat merkitystä. Lopuksi merkityksen perusteella voi ennustaa uutta dataa (kuten kielimallissa) tai kuten tässä esimerkissä, luokitellaan kuvia vektorien välisten etäisyyksien perusteella.
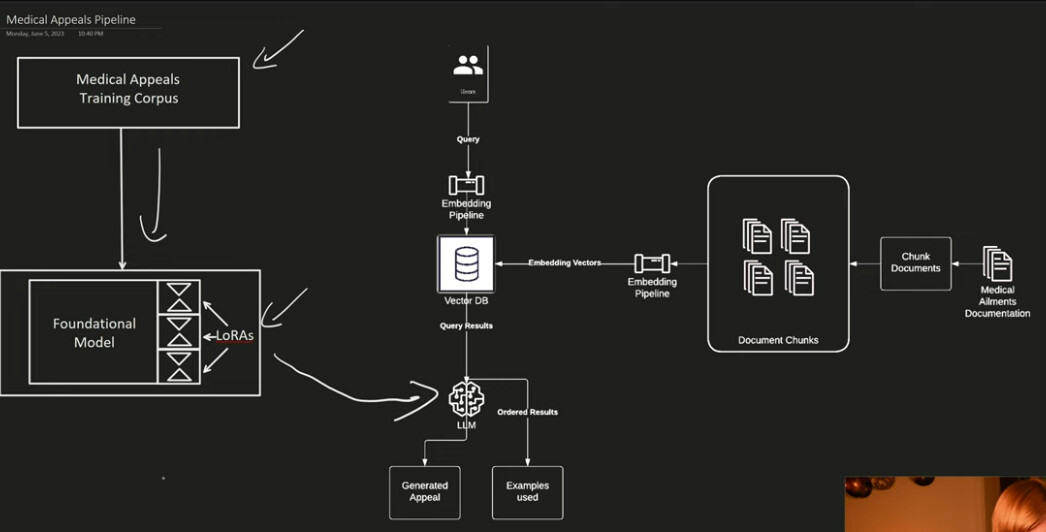
Tässä yksi käyttökohde, jossa yhdistyvät kielimalli ja vektorikanta.
Fine-tuning (tässä LoRA) säätää kielimallin sanojen generoinnin periaatetta. Taas vektorikantaan voi tuoda haluttua tarkempaa sisältöä.
Tuon videon ensimmäisillä 7 minuutilla selviää Embeddings sekä tuon kuvan toimintaperiaate. En ole tuota loppua itse koodaillut
Alkuperäinen pointtini oli se, että Vektorikantojen käyttö todennäköisesti kasvaa erilaisissa kohteissa kielimallin ja jatkossa erilaisen datan samankaltaisuuden käsittelyyn. Tällöin koko vektoriajattelusta tulee peruskauraa.
Tämän varmasti datan kanssa toimivat tietävät paremmin, mutta sijoittajat välttämättä eivät
Näin sivusta vain huikkaan pienellä riskillä, että tämä varsin semanttinen keskustelu vie liikaa tilaa tästä ketjusta, että sana upotus on vakiintunut käännös sanalle embedding matemaattisessa yhteydessä. Lause rakenne on vähän hassu tuossa, mutta sana on ihan oikea. Upotus on matematiikassa kuvaus \varphi: X \to Y topologisten avaruuksien X ja Y välillä jolle \varphi määrittää homeomorfismin avaruuksien X ja \varphi X \subset Y välille. Tässä se on siis luonnollinen sana kuvaamaan tuota kyseistä operaatiota koska tuo upotus kuvaa yksiselitteisesti (bijektiivisesti) inputit (avaruus X) jollekkin toiselle avaruudelle Y, joka on luonnollisempi laskennan kannalta, eli nyt se vektoriavaruus.
Mr. Altman’s departure follows a deliberative review process by the board, which concluded that he was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities. The board no longer has confidence in his ability to continue leading OpenAI.
Mitä lie tapahtunut?
Ps. Tämän voi siirtää jonnekin sopivampaankin ketjuun.
En ole ihan varma, ollaanko Transformerin tarkoituksesta samaa mieltä
LLM: What unlocked their abilities to parse and write as fluently as they do today is a tool called the transformer, which radically sped up and augmented how computers understood language.
Transformers process an entire sequence at once — be that a sentence, paragraph or an entire article — analysing all its parts and not just individual words.
This allows the software to capture context and patterns better, and to translate — or generate — text more accurately. This simultaneous processing also makes LLMs much faster to train, in turn improving their efficiency and ability to scale.
Miten Transformer soveltuisi FSD:n toimintaan? Ymmärsinkö jotain väärin, mihin yllä viittasit?
Vektoritietokannat on oman tietämyksen mukaan aika sidonnaisia niitä käyttäviin sovelluksiin, joten tuollainen FSD:n toiminta on hyvin monimuotoista. Veikkaan, että älyvälikerros on täysin spesifinen ja toteutuskohtainen, joten hyvin monimutkainen uusi Transformer joka tapauksessa. Virheettömyys esim. muotojen tunnistuksessa tuntuu mahdottomalta.
Transformer ei ole mikään silver bullet kuvien analysoinnissa. ViT (Vision Transformer) pieksi hetken aikaa perinteiset ConvNetit, mutta sittemmin tutkijat ymmärsivät mikä siitä teki paremman, ja uudet ConvNet-arkkitehtuurit taitavat olla taas edellä. Tuosta iltasatua: https://arxiv.org/pdf/2201.03545.pdf
“In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually “modernize” a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed Con- vNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.”
Edit: pelikenttä muuttuu koko ajan, voi olla toki että nyt on taas uusi ViT-pohjainen juttu mennyt edelle. Pitäisi kahlata arxivia läpi kunhan ehtii.
Transformer ei ole vain LLM:n, se voi käsitellä mitä dataa vaan. Tässä ketjussa olen kuvin asiaa selventänyt.
Yllä olevassa viestissäni olen kertonut, miten lähes mikä vain data muutetaan vektoreiksi (embeddings). Itse Transformerin mekaniikka toimii saman kaltaisesti kaikella datalla.
Vektorikanta liittyy tähän siten, että myös sinne voi tallentaa mitä dataa vain vektoreihin ja hakea dataa vektorien etäisyyksien pohjalta. Kannattaa selventää itselle transformerin toiminta niin ymmärtää, miksi vertaan sitä vektorikantaan
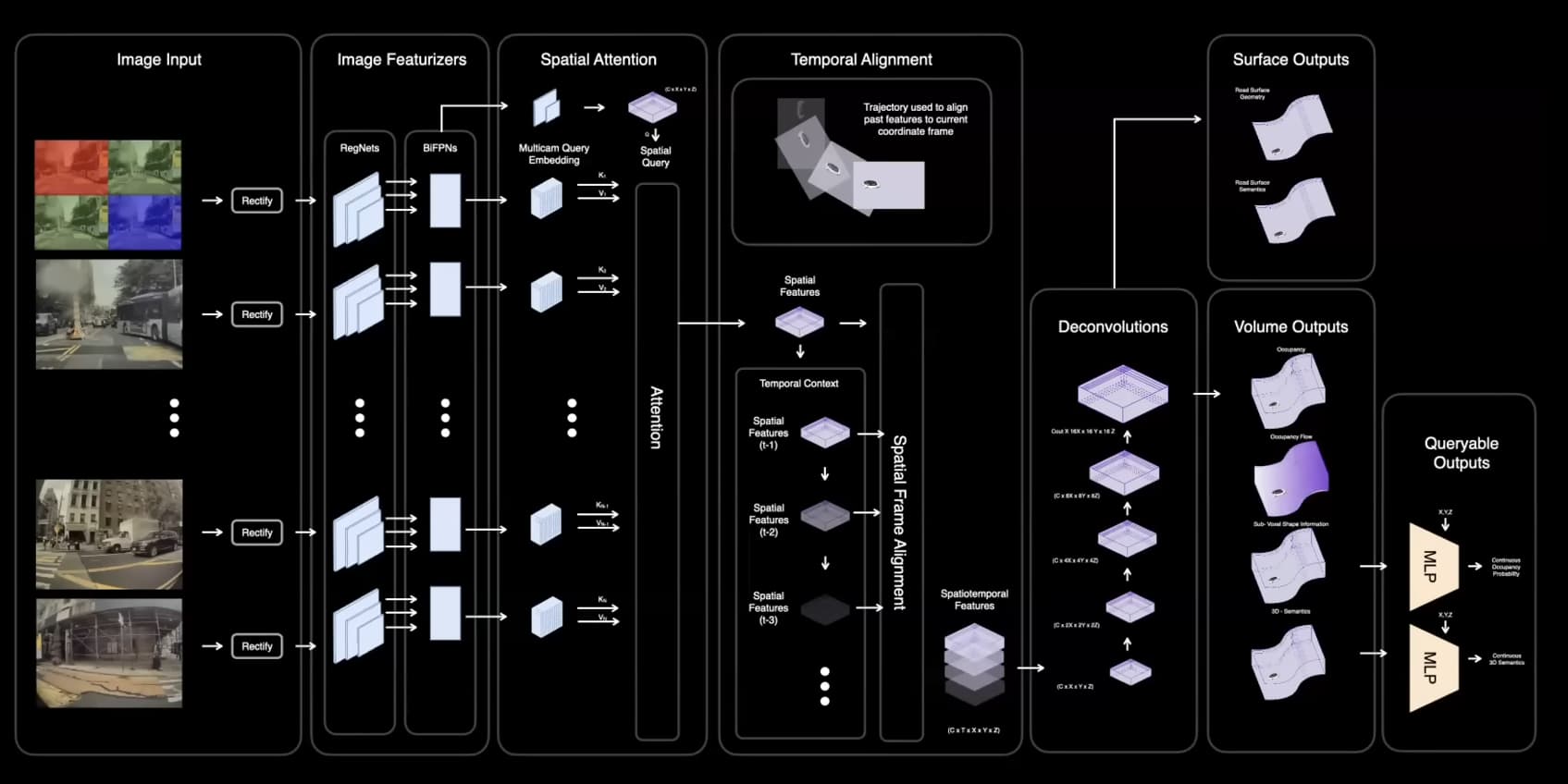
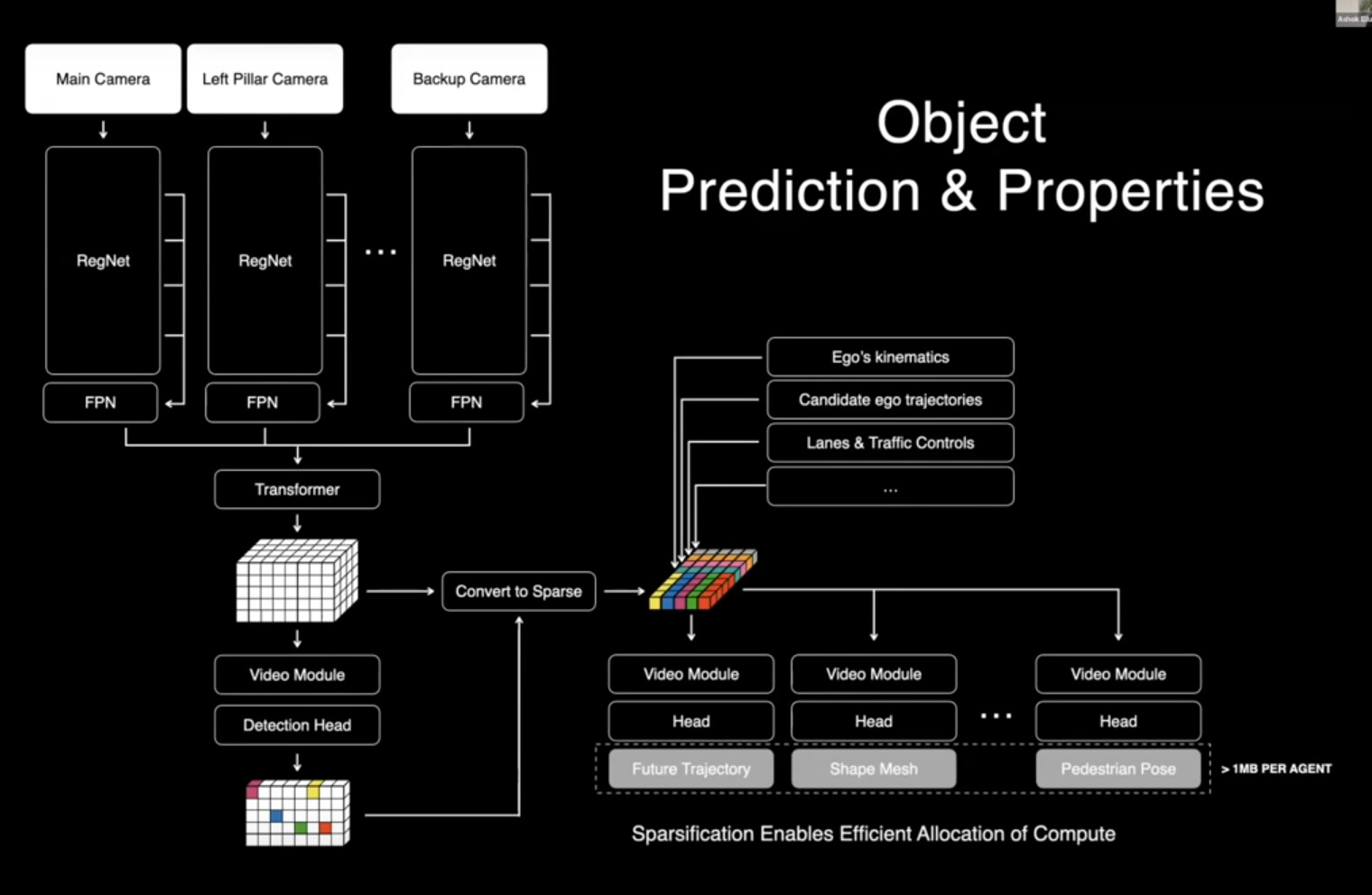
Tuossa on kuva Teslan Occupancy-ratkaisusta (varattu tila)
Tuo Spatial Attention on Transformer.
Voit verrata sitä alla olevan kuvan Value, Key ja Query osuuteen (Multihead Attention, jossa opetusvaiheessa vektorit löytävät suhteensa toisiinsa, Attention is all you need)
Näissä kummassakin Transformer käsittelee konvoluutiokerroksen (RegNet) tunnistamia featureita (muotoja) ja tekee ennustukset niiden pohjalta
Uusi Teslan V12 rakennetaan uudelleen täysin End2End-ratkaisuksi, mutta luulen, että transformeria käytetään vähintään yhtä paljon kuin nykyisessä.
Transformeria voi käyttää moneen muuhunkin kuin kuvan ja sanojen käsittelyyn. Input Embedding lohkossa data muutetaan vektoreiksi, joiden suhde toisiinsa tarkentuu opetusvaiheessa. Lopuksi vektorien suhteen mukaan voi ennustaa uutta dataa tai luokitella dataa
Kiitokset, olen selvästi liian ohkaisella tietopohjalla liikenteessä. Koodarina on tottunut tukeutumaan testailuun debuggauksen kautta, mutta siihen ei ole enää tällä tasolla rahkeita. Aihe on kyllä äärimmäisen mielenkiitoista enkä pysty tuosta hahmottamaan, miten tunnistukset ilman opetusdataa (johon vertailla) voisi onnistua.
Esim. Vin Vashishta, yksi tekoälykentän / AI VC:n kovimmista nimistä kertoo, että OpenAI kärsii jo nyt esim. API-rajapintojen stabiliteettiongelmista ja että yritykset ryhtyvät ensi viikolla siirtämään ratkaisujaan OpenAI:n alustalta muualle.
Ei taida olla ihan mahdoton skenaario myöskään se, että Altman tulee takaisin ja boardi lähtee vaihtoon.
Sellaisen huomion tehnyt, että tekoälylle kelpaa myös ns. google-fu tai öö luolamieskieli, ilman että se merkittävästi vaikuttaa vastaukseen. Sellaista arkipäivän optimointia
Sen sijaan, että kirjoitat jotain tyyliin “In typescript react native using context api, what’s the most efficient way to iterate a dynamic component based on data calculated based on current context state”
riitää kun kysyy esim. “ts rn ctx iterate dyn compo ctx efficiently”, vähän ääriesimerkkinä
Pelkään että jos tuolta todella lähti Sam Altmanin lisäksi kasa kovimpia devauspuolen miehiä niin OpenAI on yhtäkkiä vähän sellainen kuori jolla on tuote jonka tekijät lähtivät kílpailijalle. Microsoft tietenkin esittää että homma jatkuu koska mikä tahansa muu voisi aiheuttaa kovalla vaivalla ulos pistettyjen tuotteiden kanssa katkoja, mutta varmaa on että tavoitteena on tehdä OpenAI tarpeettomaksi Microsoftille keskipitkällä aikavälillä…
Bullish Microsoft, ei niin bullish OpenAI. En myöskään haluaisi olla firma joka on kovalla rahalla ostanut ChatGPT:tä OpenAI:lta tuotantokäyttöön… jos huippuosaajat juuri vaihtoivat Microsoftille, nopeasti herää pelko että mistä enää maksetaan, kuinka nopeasti tämä tuote lahoaa alta vs. kilpailijat.
Vähän joo perinteistä embrace extend extinguish microsoftia nähtävissä tässä liikkeessä, vaikka OpenAI ei koskaan kovin avoin nimestään huolimatta ole ollut. Jos joku tästä saa jotain irti, niin varmaan Meta ja heidän avoin llama. Olen arvostanut Yann LeCunia siitä asti kun löysin lushin ja tässäkin kohtaa hänen varoituksiaan suljetuista malleista.
Käytännössä lähes koko työväki sanoo että firman hallitus vaihtoon ja Sam Altman takaisin, tai lähtevät kävelemään. Microsoftin uudella AI-osastolla kuulemma on työpaikat valmiina…
Melkoista sekoilua. Alla YTn paras kanava kertoo lisää taustoja, mutta sekavuuden yksi huipentuma saattoi olla kun Ilja koki uskonnollisen AGI herätyksen ja muuttui tiedemiehestä profeetaksi.