GPUt osaavat ajaa hurjan määrän (kymmeniä tuhansia) pieniä asioita rinnakkain. Tämä on hyödyllistä tietynlaisien ongelmien ratkaisuun. Historiallisesti tällaisia ovat olleet grafiikka ja vaikkapa kryptolaskenta (yllätys)
CPUt historiallisesti ovat ajaneet ehkä kymmeniä asioita rinnakkain kivuttomasti, mutta kykenevät paljon monimutkaisempiin asioihin. Suurin osa ongelmista on sellaisia että niitä on hankala jakaa loputtoman moneen rinnakkaiseen säikeeseen ja usein jokainen säie vielä tarvitsisi oman muistialueen ja muistikaistan, joka usein tuo ongelmia (tuore 96-ytiminen Threadripper yhdistettynä liian vähäiseen muistimäärään tuo yllättäviä koomisia ongelmia kun ohjelma typerästi vain katsoo että hei, 96 corea, siispä jaan duuniin 96 säikeelle ja tuosta noin… mitä? out of memory? Ah, koska jokainen säie varasi gigan muistia ja koneessa ei ollut 96 gigaa muistia… systeemi joka toimi ihan hienosti vaikka 8 ytimellä ei yhtäkkiä enää toimikaan)
Prosessoreilla kellotaajuuksien loputon nostaminen on aika lailla tullut tiensä päähän ja lisätehoa on saatu pinoamalla lisää ytimiä ja lisäämään rinnakkaista laskentaa. Ongelma on että monet jutut eivät taivu rinnakkain ajettavaksi kivuttomasti tai kohtaavat ennen pitkää seinän jonka jälkeen lisäytimien lisääminen voi jopa hidastaa hommaa. Samalla prosessoreilla ei oikeastaan edes voi järkevästi tehdä asioita joita GPUt voivat tehdä, koska jopa 96 ydintä rinnakkain ei riitä mihinkään jos esim ollaan renderoimassa grafiikkaa jossa pitäisi muutamassa millisekunnissa generoida miljoonia pikseleitä. Jokainen yksittäinen pikseli on pieni duuni, mutta ainoa tapa tehdä homma järjellisessä ajassa on ajaa älytön määrä asioita rinnakkain.
CPU: kahdeksan täysperävaunullista rekkaa
GPU: 10000 pientä jakeluautoa
Jos duunisi on toimittaa 10000 pientä pakettia 10000 vastaanottajalle, CPU voi sen tehdä, mutta saattaa muutama viikko vierähtää. GPU teki sen jo tänään.
AI sattuu olemaan duuni jossa GPUn arkkitehtuuri on erittäin hyvin soveltuva. Joten yllättäen Nahkatakkimies hehkuttaa kuinka uusi aikakausi on alkanut ja joka datacenter tarvitsee nyt rekkalaisteittain (NVIDIAn) GPUita näiden uusien laskentaduunien hoitamiseen. Markkinointimiehiä. Totuus ei ole ihan näin yksinkertainen, mutta eipä nuo megacap-teknot näitä GPU-kiihdytettyjä servereitä huvikseenkaan ostele…
Koneoppimisen pohjalla olevan parametrien optimoinnissa käytettävän tensori-parallelisoinnin hyödyt ymmärrän ja ostan - ne ovat aivan ilmeiset jokaiselle, joka on joskus koittanut rakentaa yhden kerroksen perceptronia vähänkään monimutkaisempaa mallia saati optimoinut backpropagationilla tuollaista mallia vähänkään suuremmalla datamassalla. Tämä on se, mikä tulee nyt läpi tuloslaskelmaan jo isosti. Grafiikka ja krypolouhinta ovat tietysti yhtä ilmeisiä.
Se mikä herättää duubioita on tuo Huangin ajatus siitä, että kiihdytetty laskenta ulottuisi uutena laskentaparadigmana lähitulevaisuudessa yleisesti myös muualle kuin koneoppimisen käyttötapauksiin. Itse siis kuulen tuota viestiä niin, että suurinpiirtein kaikki ohjelmistot, jotka nyt voisivat jollain tavoin hyötyä suuremmasta, rinnakkaisesta ALU-määrästä. Tulkitsenko Huangia väärin, kun hän sanoo esim. There’s just no reason to update with more CPUs when you can’t fundamentally and dramatically enhance its throughput like you used to. And so you have to accelerate everything.?
En vain itse keksi esim. miten jossain MVC-ohjelmistoarkkitehtuurissa rinnakkaisuus tuo throughput hyötyjä. En löydä sitä samaa ilmeisyyttä kuin tensoreilla tapahtuvassa matriisilaskennassa tai grafiikassa. Onko siis pelkkää markkinointia?
Tämähän se ongelma on. Myyntimies kyllä myy sulle ne GPU-coret ja kehuu että näillä voit tehdä vaikka mitä(*…
(* raudan mukana ei toimiteta valmista ratkaisua tehdä vaikka mitä, palkkaa vähän softakehittäjiä ja ideoi ihan itse!
Ei mahdotonta, mutta ei ihan triviaalia ja monessa asiassa hyödyt eivät riitä paikkaamaan sitä vaivaa mitä uudelleenimplementoinnista olisi. Mutta tietenkin kun meillä on kohta joka datacenter täynnä GPUita niin eiköhän insinöörit keksi uusia käyttötarkoituksia jotka aiemmin eivät olleet järkeviä koska rautaa ei ollut nurkat täys ja se oli kallista ja prossuillakin luonnistui tarpeeksi hyvin.
Jep. Itselläni on vain melko korkea kynnys leimata Huang ja hänen juttunsa markkinointimiehen jorinoiksi. Nimittäin ihan samaa “markkinointia” hän on paasannut meille kuolevaisille maan matosille aina sieltä 2015-2016 saakka Nvidian tuotteiden positiosta tekoälyyn liittyen ja jokainen voi nyt todeta, miten olisi kannattanut näitä puheita kuunnella, vaikka kysyntä tuolloin olikin se kuuluisa zero billion dollars.
Siksi pyrin itse nyt ymmärtämään ja analysoimaan, voisiko Huang kuitenkin nähdä tässäkin jotain, mitä minä / me emme vielä näe. Siis jotain muutakin kuin sen (mahdollisesti ihan validinkin) pessimistiskenaarion, että ylijäämäraudalle pitää keksiä jotain hyötykäyttöä
Vaikeaa sanoa, AI-jutut kehittyvät nyt sitä tahtia että en yllättyisi jos kaikesta tästä devaustyöstä jatkojalostuisi jotain jolla tehtäisiin jotain aivan uutta GPU:lla joka ei ollut aiemmin realismia prosessoreilla. Nyt meillä on jo chattibottia ja kuvien sekä pian videoiden generaatiota mutta varmasti keksitään muutakin.
On noissa jutuissa siinä mielessä vinha perä että GPUita pinoamalla sitä laskentakapasiteettia saadaan älyttömästi enemmän kuin prosessoreilla, on hyvin mahdollista että tuolle kapasiteetille keksitään ihan uusia käyttötarkoituksia. Jos näitä tippuu edes muutaman vuoden välein niin GPUita tulee menemään kaupaksi vinot pinot pitkälle tulevaisuuteen.
Noin se on. Jensen on kommunikoinnissaan aina ollut lavea, eikä välttämättä mieti jokaista lausettaan ihan tarkasti. Eli hän kommunikoi karkeasti oikein, mutta ei kannata lukea hänen sanomisiaan liian kirjaimellisesti.
Allekirjoitan lavean tarinan kerronan jossain määrin. Mutta kiihdytetyn laskennan yleisen vallankumousasian osalta hänellä on ollut yhtä konsistentti näkemys viimeiset pari vuotta aivan joka puheenvuorossa kuin hänellä oli AI:n osalta noin vuodesta 2015, jolloin kukaan ei ottanut asiaa vakavasti.
Kaikki ennätykset on tehty rikottavaksi, pörssissäkin!
On paljon toimialoja, joilla prosessit ovat niin hankalia, että nykyiset IT/ERP järjestelmät eivät niitä ole juurikaan parantaneet. Hyvä esimerkki on sote, jossa moderni ATK on lisännyt kustannuksia ja hidastanut potilasvirtaa läpi hoitoketjujen. Koneoppiminen ja LLM mahdollistavat monimutkaisten prosessien tehostamisen ja automatisoinnin - juuri niiden joihin ei perinteellinen jäykkä ERP nyt pure. Mutta voi olla, että siirtymä some-rahoitteisesta AI buumista teollisten toimialojen ja soten AI buumiin ei tapahdu saumattomasti. Jotenkin musta tuntuu, että 2026 tienoilla tapahtuu samanlainen kysyntäpysähdys kuin 2022 krypto- ja pelibuumin hiivuttua. Nvidian sijoittajan tulee varautua syklisyyteen. Minä en osaa reagoida syklisyyteen, ja otan sen pulkkamäen sitten ookoona, kun se tulee. Nvidia nousee aina, se on nyt sellaisessa pitkän syklin vedossa markkinan luojana. Pitkään vetoon kuuluu 70% dipit välillä.
Kysymystäsi voi lähestyä esimerkiksi sitä kautta, että miettii, millaiset tehtävät ovat GPU:lla tehokkaasti rinnakkaistettavaissa. Hyvin GPU:lla rinnakkaistettava tehtävä esimerkiksi:
On muotoiltavissa järkevällä tavalla GPU:n SIMT (Single Instruction, Multiple Threads) -arkkitehtuurilla ratkaistavaksi.
Sisältää riittävän itsenäisiä osatehtäviä, jotta GPU:n sisällä suorituksen synkronointioperaatioiden (esim. laskennan erilliset synkronointivaiheet tai atomiset operaatiot) määrä pysyy kohtuullisena suhteessa muuhun suoritukseen. Parhaan hyödyn GPU:sta saa irti, jos pystyy lähettämään GPU:lle asynkronisesti työjonoon paljon toisistaan riippumattomia osatehtäviä, jolloin GPU on koko ajan täydessä ajossa. Sovelluskohteesta riippuen tämä on tai ei ole helposti mahdollista.
On kooltaan riittävän iso, jotta tehtävän siirtely / alustaminen / tulosten lukeminen CPU->GPU->CPU ei aiheuta enemmän suorituskykyhaittaa kuin mitä GPU:n hyödyntämisestä saadaan etua.
Kaksi jälkimmäistä näistä ovat ehkä (?) ilmeisiä ja ensimmäinen tarkoittaa sitä, että GPU:sta saa hyödyn irti vain jos useat (GPU-sukupolvesta / mallista riippuen yleensä vähintään useat kymmenet) säikeet voivat suorittaa täsmälleen samaa kohtaa ohjelmakoodissa samaan aikaan. Vaikka modernilla GPU:lla laskentaytimiä (esim. NVidian CUDA cores -lukema) on periaatteessa kymmenissa tuhansissa laskettava määrä, nämä eivät ole silti ollenkaan samalla tavalla toisistaan riippumattomia kuin vaikkapa perinteisen CPU:n ytimet.
Tehtävästä riippuu, onko jossakin tietyssä datacenterissä suoritettavan laskenta puettavissa järkevästi tuollaiseen muotoon vai ei. Jos esimerkiksi ohjelmakoodin logiikka on voimakkaasti haarautuvaa laskentatulosten perusteella, niin tämä voi johtaa hyvinkin huonoon hyötysuhteeseen SIMT-tyyppistä arkkitehtuuria käytettäessä, jos samaan aikaan rinnakkain suoritettavat säikeet haarautuvat hyvin satunnaisesti eri osiin ohjelmakoodia.
Ja esimerkiksi jossain palvelinkeskuksissa voi olla ihan toisen tyyppistä työkuormaa. Jos vaikkapa jollain palvelimella useat kymmenet käyttäjät ajavat omia erillisiä skriptejään, ohjelmiaan yms., niin tämän tyyppinen kuorma ei oikein sovellu mitenkään suoraan SIMT-arkkitehtuurilla kiihdytettäväksi. Suorituksessa eivät ole rinnakkain edes samat ohjelmat, joten skaalaaminen SIMT-lähtökohdasta ei oikein tule kyseeseen. Tällaisen työkuorman rinnakkaistamisessa perinteinen CPU toimii paremmin.
Yleisesti ottaen tämä
There’s just no reason to update with more CPUs when you can’t fundamentally and dramatically enhance its throughput like you used to
pätee niissä tilanteissa, joissa suoritus on järkevästi GPU:lla toteutettavissa. Tällöin monimutkaisemman CPU-ytimen on vaikea kilpailla “yksinkertaisten” ja määrältään moninkertaisten GPU:n laskentaytimien kanssa. Monet esim. laskentaklustereilla ratkottavat tehtävät varmaan täyttävät nämä kriteerit, mutta eivät tosiaan välttämättä kaikki.
En ainakaan itse ennustaisi perinteisemmän CPU:n kuolemaa vielä tässä vaiheessa, mutta enpä toisaalta ole Huangin kaltainen visionäärikään, vaikka nahtatakki löytyykin vaatekaapista.
Joka aamuinen Jensenin mietelause (heti conf call jälkeen Jon Forttin haastattelusta), aiheena AI Enterprise engine:
"Accelerated computing is not just about the chip, it’s about the software. - - Accelerated computing requires a full stack. Whenever we do something in quantum chemistry, it requires a quantum chemistry stack. Whenever we do something in weather simulation, it needs a weather simulation stack. Whenever we do something for AI training, it requires an AI training stack.
And so each one of these stacks - robotics stacks, AV stacks, each one of these stacks require a great deal of engineering. In the case of CSPs they can manage it themselves. - - But for most of the enterprises and enterprise software companies, they simply don’t have the large and deep expertise in accelerated computing at this point. And so we’ll do it for everybody. We’ll optimize it for everybody. We’ll create these stacks for everybody and with everybody and we’ll make it run in every single cloud for everybody.
And the way that we monetize it is through this engine, this Nvidia AI Enterprise engine, which is essentially an operating system for Nvidia’s AIs, Nvidia’s enterprise and accelaration algorithms. And you pay for it per GPU per year, just like an operating system. And you can run everything that Nvidia creates and enables. - - This is going to be very, very significant opportunity for us."
Nonniin, nyt siitä tuli sitten ihan täysiverinen softatalo piirisuunnittelun lisäksi. Uusi lätkamaila kaapista ja asentaen NVIDIAn käppyrän jatkoksi kun kerran suunnitellut softastackit alkavat jauhamaan rahaa kaksin käsin lisenssoinnin kautta. Ja kaikki tietenkin vuosilaskutuksella…
Ainahan NVIDIA on softaa tehnyt, mutta historiallisesti se on ollut olemassa vauhdittaakseen raudan myyntiä ja luodakseen vallihautaa vs. kilpailevat rautavalmistajat eikä sinänsä ole erikseen maksanut.
Softapuolen analysointi olikin tehtävälistalla seuraavana tuon laskentaparadigma-asian ohella. Tuo $1B softapuolen annualisoitu runrate on kyllä myös supermielenkiintoinen ja Huangin tajunnanvirta conf callissa jäi vähän hämäräksi tuon osalta. Ilmeisesti siis jokin n. $5000 recurring revenue softalisenssikomponentti tulee jonkin hardiksen mukana maksettavaksi, jos ymmärsin oikein. En tiedä meneekö laskuni nyt sinne päinkään, mutta jos ajatellaan, että Nvidia myy vaikka tänä vuonna sen n. 3M Enterprise-luokan chippiä, tuo recurring tuo vielä vaikkapa 10 vuoden juoksuajalta 150 miljardia toistuvaista liikevoittoa. Saa korjata, jos ymmärrykseni on jotenkin ihan pielessä.
Samaan aikaan Nvidia ylitti juuri $2T valuaation. Apple on (enää) n. 40% kurssinousun päässä.
En laskisi ihan noin härkämäisesti, koska valtava osa raudasta menee isoille megateknoille jotka tekevät itse omat softastäkit ja eivät tällaista lisenssoi.
Tämä on tapa myydä AI-softaosaamista pienemmille pelureille joilla ei ole Googlen, Metan ja Microsoftin kokoista insinööriarmeijaa joka devaisi ne AI-softat ja joka kenties haluaa nojata NVIDIAn osaamiseen tältä osin (maksua vastaan).
Miljardeja, ehkä kymmeniä miljardeja jollain aikavälillä? Hyvin karkea arvaus.
No vähän ajattelinkin, että jotain menee pieleen. Laskentaa varten pitäisi siis osata arvioida CSP:eiden osuus chipeistä, joka lienee varmaan ainakin toistaiseksi ylivoimainen enemmistö.
Tarkennuksesi perusteella arvioisin, että laskelmistani voi poistaa sellaisen 75-90%
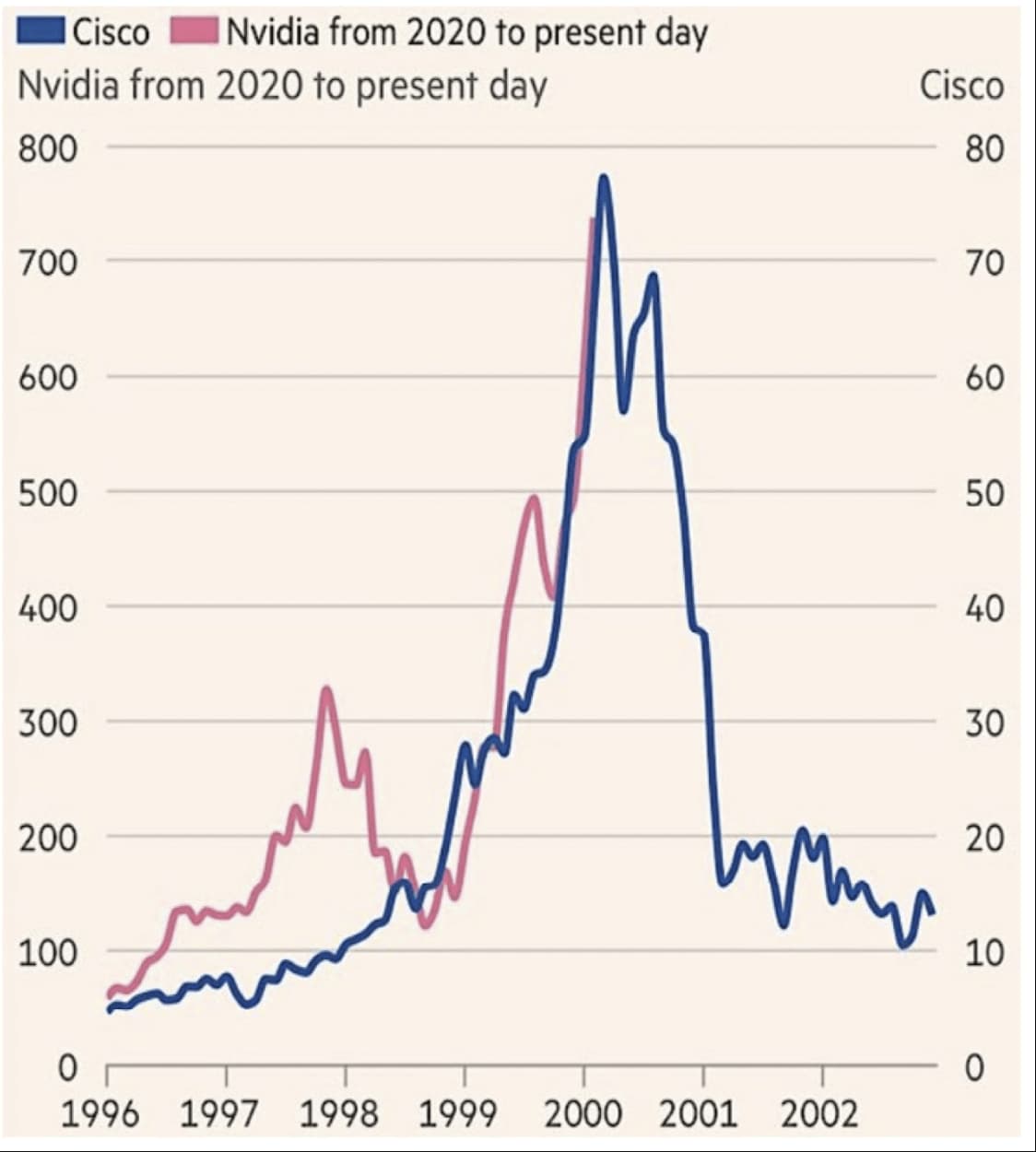
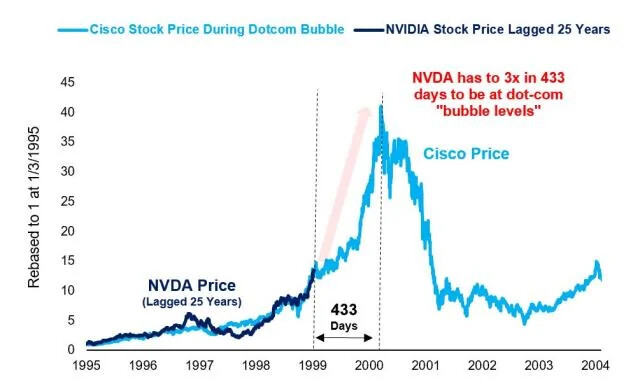
Hyvä perspektiivi jatkuvaan kuplakeskusteluun, Cisco-muistutteluun ja “this time it’s different” -anekdoottailuun - jokainen päättäköön itse kumpaa graafia (jos kumpaakaan) uskotte:
X:ssä olen lukenut muutamia hyviä huomiota miten NVIDIAn myynnistä jos jonkinlainen lohko tulee muilta ”mageilta” jotka pistävät tällä hetkellä kymmeniä miljardeja Capexia laskentatehoon (esim. Meta).
NVIDIA tottakai myy muuallekin, mutta tavallaan hauska hahmotella miten analyytikoiden ennusteissa yhtiön kokoluokka moninkertaistuu lähivuosina ja meinaako tosiaan muut paisuttaa capexejaan entisestään (mikä valuu NVIDIAn voitoiksi).
Tässähän tulikin vastaus edellä esittämääni kysymykseen. Eli CSP:t plus Metan kaltaiset jätit ovat karkeasti +50% ison skaalan chippi-myynnistä.
Kyllähän fakta on se, että megateknojen capexit eivät voi paisua loputtomiin ja jostain on löydyttävä korvaavaa kysyntää. Toki sekin on huomattava, että tuollainen kymppimiljardi ei ole kuin prosentteja megateknon taseessa. Ja jos laskentakapasiteetti todella luo uutta “teollista vallankumousta”, voi referenssipistettä haarukointiin hakea karkeasti tuotantolaitosinvestointien tasesuuruusluokasta (tuotantoassetit voivat olla pääomaintensiivisillä yrityksillä jopa siellä 50-75% nurkilla taseen loppusummasta).
Tätäkin Huang sivusi sijoittajapuhelussa ja muistaakseni jossain muuallakin ER:n jälkilöylyissä vielä tarkemminkin (valistuneen analyytikon kysymys oli suoraan suurin piirtein tämä “mistä Nvidian kasvu tulee mag6 capex-investointien jälkeen”), mutta en enää muista mistä tämä löytyy. Lohdutukseksi Jensenin tajunnanvirtaa sijoittajapuhelusta:
“But we’re also diversifying into new industries. The large CSPs are still continuing to build out. You can see from their CapEx and their discussions, but there’s a whole new category called GPU specialized CSPs. They specialize in NVIDIA AI infrastructure, GPU specialized CSPs. You’re seeing enterprise software platforms deploying AI. ServiceNow is just a really, really great example. You see Adobe. There’s the others, SAP and others. You see consumer Internet services that are now augmenting all of their services of the past with generative AI.”
Ja ilmoittihan Nokiakin hyppäävänsä Nvidian asiakaslistalle hei
Monihan nyt miettii sitä, että mikä NVIDIAn sirumyynnin oikein leikkaa. Keskustelu IonQ:n ketjussa poiki yhden skenaarion siihen, miten kauan noita NVIDIAn siruja oikein tullaan haluamaan nykytahdilla → kvanttilaskennan lyödessä läpi muutaman vuoden päästä havahdutaan siihen, että ei NVIDIAkaan ole nykyisen bittiarkkitehtuurin siruilla turvassa, kun kvanttisirut alkavat ottaa roolia AI laskentaan. Energian kulutus tullee olemaan tämän bittiarkkitehtuurin kasvun rajoittaja. Sen takia NVIDIAlla on kiire vahvistaa ohjelmistotuotantoaan, jota voidaan ohjata myös kvanttilaskennan tarpeisiin. Mulle ei ole ihan mahdoton visio se, että NVIDIAn teknolgiasta tulee kvanttilaskennan kehitysympäristö, jossa simuloidaan ja hiotaan kvanttialgoritmeja. Tästä on minusta ollut NVIDIAn osalta puhetta ja juttuakin. Eli yhtiöllä on kvanttistrategia.
Kvanttilaskentaan laskisin menevän vähintään vuosikymmenen, eikä sillä ole välttämättä ainakaan nykyisenkaltaista ai-kyvykkyyttä (nykyistä esimerkiksi chatgpt-laskentaa varten Microsoft on tehnyt itse omat prosessorit, koska nykyinen prosessitekniikka sovellu tehokkaasti tuohon, eli kyse ei ole aina puhtaasta matematiikasta ja kvanttilaskenta on aluksi aika perustason - joskin todella huimaa ja syvää - laskentaa). 2010-luvulla pienen kvanttihypen ollessa päässä kaikki oli ns. muutaman vuoden sisällä (tämä on aina jokaisen teknohypen perusteesi, muutaman vuoden päästä tapahtuu huimia asioita), näitä esiteltiin esimerkiksi vuonna 2017 eräässä jenkkiseminaarissakin jossa olin. Kovin paljoa ei ole kuulunut, vaikka silloin(kin) oltiin ihan läpimurron porteilla. Tietysti jenkit ovat markkinointihenkisiä ja ylipuheet kuuluu asiaan.
Kvanttihypeen ei kannata liikaa lähteä, se ei ole suoraa ns. seuraava teknologinen vaihe, jota aletaan käyttää noin vain.
Perinteisessä softassa säikeistys/rinnakkaislaskenta on tehtävä koodissa. Tämä unohtuu helposti tässä huumassa, missä on ero CPU/GPU.
Ja mihin kumpikin on tarkoitettu. Nyt unohdetaan se, mihin nykyisin ymmärrettävä AI lopulta pystyy.