Jos oikein eilen näin, niin ymmärsin, että splitti toteutuisi 10.6.
3 tykkäystä
Silläkin uhalla, että menee kurssihehkutukseksi, niin Nvidia treidaa pre-marketissa jo $2.5T valuaatiolla (n. 7% nousussa), mikä on:
- enemmän kuin Mag-kutoseen kuuluvat Amazon ja Tesla yhteensä
- suurempi kuin koko Saksan pörssi
- noin 8500 kertaa kaikkien Suomen pörssiyhtiöiden markkina-arvo
Siitä perspektiiviä tilanteeseen, jonka nahkatakkimies sanoo olevan vasta vallankumouksen alku.
Maailman 2. suurimman yhtiön paikan varastaminen Applelta on enää 17% nousun päässä.
18 tykkäystä
Suurella todennäköisyydellä datakeskusten useiden satojen prosenttien vuosikasvulle sanotaan tämän tuloksen myötä jäähyväiset, sillä viime vuoden q2 oli ensimmäinen superkasvun kvartaali.
Nyt voi tyytyväisenä jatkaa Kiina/Taiwan -tilanteen pelkäämistä.
3 tykkäystä
Jos kerran ollaan tekemässä teollista vallankumousta, niin silloinhan lyödään murskaksi aiemmat ennätykset. Applehan on vielä pitänyt aika piilossa omat vallankumoukselliset innovaationsa, joten Applea, sen markkina-arvoa, voidaan pitää kohta historiaan jäävän ATK ja ICT aikakauden kovimpana yhtiönä. NVIDIA vie meidät AGI aikaan, ja samalla lyö aiemmat ennätykset laudalta.
8 tykkäystä
Poimin Q1 sijoittajapuhelusta joitakin Jensenin nostoja ja laitoin perään oman tulkintani siitä:
Jensen : Companies and countries are partnering with NVIDIA to shift the trillion-dollar installed base of traditional data centers to accelerated computing and build a new type of data center, AI factories, to produce a new commodity, artificial intelligence.
Elikkä tänään vielä 90% datacentereistä on ns. perusmallisia, ilman AI kiihdyttimiä. Sen takia infrauudistukset ovat tosiasiassa vasta alkamassa.
Jensen : Strong and accelerated demand – accelerating demand for generative AI training and inference on Hopper platform propels our Data Center growth. Training continues to scale as models learn to be multimodal, understanding text, speech, images, video and 3D and learn to reason and plan.
Multimodaalisuus takaa sen, että kysyntä ei vähene, vaan Jensenin mukaan kiihtyy. Tietysti prosentuaaliset kasvut tasoittuvat.
Jensen : Our inference workloads are growing incredibly. With generative AI, inference, which is now about fast token generation at massive scale, has become incredibly complex.
AI päättelyä viedään tokeneihin. AI-tokenien maailma on äärimmäisen monimutkaista. NVIDIA luo AI päättelymekanismeja ja ehkä AI päättelyä tekevät tokenit voivat kehittyä vaihdannan välineiksi?? NVIDIA näyttää jälleen arkkitehtuurista ja teknologista suuntaa ja muut tulee perässä.
Jensen : from producing software to generating tokens, manufacturing digital intelligence.
Tokenit ovat näitä pieniä tai miksei isojakin älysoluja. Niitä ei enää koodata, vaan nyt en oikein tiedä mitä sanoisin, sanotaan nyt niin, että niitä kasvatetaan, tai niille annetaan olosuhteet kasvaa ja kehittyä
Jensen : Token generation will drive a multiyear build-out of AI factories.
Koko AI toimiala jatkaa paisumistaan. NVIDIA auraa latua ja vetää laite ja infravalmistajat ja myös softataloja imuunsa.
Jensen : From today’s information retrieval model, we are shifting to an answers and skills generation model of computing. AI will understand context and our intentions, be knowledgeable, reason, plan and perform tasks.
Eli voidaan tehdä työtä tekemällä oppivia robotteja, ja vaikkapa Amazon voi korvata varastotyöntekijät roboteilla.
Jensen : The combination of Grace CPU, Blackwell GPUs, NVLink, Quantum, Spectrum, mix and switches, high-speed interconnects and a rich ecosystem of software and partners let us expand and offer a richer and more complete solution for AI factories than previous generations.
NVIDIA johtaa orkesteria, jossa kilpailijat saavat soittaa sooloja. NVIDIA hivuttaa kvanttilaskennan pikkuhiljaa osaksi Accelerated Computing ratkaisukokonaisuutta.
14 tykkäystä
@Miami tuossa pohdiskeli NVIDIAn splittiä. Muutama ajatus splitistä. Kyseessä on tekninen toimenpide. Yhtä osaketta vasten saa 10. Splitti ei tietenkään vaikuta yhtiön liiketoimintaan, eikä yhtiön arvoon. Siksi, kun 7.6. markkina sulkeutuu, niin omistaja saa 10.6. 10x määrän osakkeita, joiden kurssi on sitten 1/10 7.6. päätöskurssista. Noin se menee lukion yhteiskuntaopin kurssikirjan mukaan.
Elävä elämä toimii hieman eri tavalla. Yhden osakkeen arvon tekninen alentaminen lisää kaupankäyntiä ja likviditeettiä, koska ainakin osa piensijoittajista ei pääse suoraan kiinni tonnin osakkeeseen, vaan mutkien kautta. Miten iso tämä likviditeettivaikutus on, sitä voi asiasta kiinnostuneet tutkia tutkimuksista, joita varmaankin netistä löytyy. Mutta maalaisjärjellä ajateltuna pienempi yksikköhinta osakkeelle on parempi kuin isompi, koska se lisää potentiaalista osakkeenomistajien määrää ja kaupankäynnin määrää, se taas on asia mistä koko osakemarkkina pitää. Likviditeetti on aina hyvä asia.
Okay, on siis tapahtumassa asia, joka ei missään nimessä ole markkina-arvoa heikentävä asia. Mutta se voi olla markkina-arvoa hieman lisäävä asia. NVIDIAn osalta pienetkin hyvät asiat voivat kertautua positiivisesti eteenpäin. Esimerkiksi, NVIDIA saattaa käyttää omaa osakettaan yritysostojen kaupankäynnin välineenä. Osakkeella voi splitin takia olla piirun verran enemmän arvoa, kuin ilman splittiä. Ja näin vanhojen osakkeenomistajien osuus liudentuu piirun verran vähemmän, jos NVIDIA käyttää osakettaan kaupankäynnin välineenä.
Sitten vielä on arvoitus, menikö splitin ennakoidut hyödyt jo heti osakkeen hintaan. Vaikea sanoa. Siitäkin lienee maailmalla tehty case-tutkimuksia.
Isossa kuvassa splitin pieni positiivinen merkitys osakkeen kurssiin/yhtiön arvoon hautautuu liiketoiminnassa tapahtuvien asioiden alle.
6 tykkäystä
Viputuotteiden käyttö helpottuu myös kun yksi kontrahti ei enää kustanna $100k. Retail-treidaajat tykkää ainakin.
1 tykkäys
Huang pitää 24h päästä keynoten Computex 2024:ssä: NVIDIA at Computex 2024
2 tykkäystä
Teknisesti ottaen kyse on juuri-ennen-Computexia pidettävästä keynotesta samassa kaupungissa läheisellä areenalla eikä ole osa varsinaista tapahtumaa. Nahkatakkimiehen kun piti pistää show joka on ennen Computexin virallisesti avaavaa AMDn keynotea. Normaalia ystävällismielistä firmojen nokittelua ![]()
AMDn Computex-tapahtuman avaava keynote jossa myös varmaan sanotaan “AI” pari kertaa
Maanantaina 04:30 Suomen aikaa.
5 tykkäystä
En ole NVIDIAn piireihin perehtynyt ja siksi kysyn, viitataanko Tokeneilla Transformerin Tokeneihin/vektoreihin ?
Googlasin, että Hopperissa on Transformer Engine ja Blackwellissä Second-Generation Transformer Engine. En noita tarkemmin vielä tutkinut.
Suuri osa innovaatioista tuntuu nykyään pohjautuvan Transformeriin ja input Tokenien määrää kasvatetaan jatkuvasti.
2 tykkäystä
Tokenit ovat LLM:stä puhuttaessa syötteen ja tulosteen osasia / rakennuspalikoita. Yksinkertaisimmillaan NLP-modaalisuudessa token on yksittäinen sana syöte-/tulostelauseessa, jonka LLM ottaa syötteenä ja tuottaa syötetokenin perusteella output-tokenin. Nykyisissä NLP LLM:ssä (Llama / GPT4 jne.) token on tosin paljon monimutkaisempi ja erilaisia tokenization-tekniikoita on paljon.
Tässä on aika hyvä yhteenveto siitä, mikä GPT-4:ssä on token ja miten ne toimii: https://www.youtube.com/watch?v=zduSFxRajkE
Kun puhutaan kuva- ja / tai videomodaalista, niin token on jokin yksittäisen kuvan tai framen osa. Jos miettii, että hyvälaatuinen videosekunti pitää sisällään 24 framea ja se pilkotaan useaksi eri tokeniksi, on aika ilmeistä, että nämä modaalisuudet kasvattaa prosessoitavien tokenien määrää siirryttäessä kielimodaalisuudesta lukuisiin muihin modaalisuuksiin.
4 tykkäystä
Jos vielä koitan yksinkertaistaa. Kaikki data joka tekoälyn käsiteltäväksi päätyy täytyy muuntaa sen ymmärtämään muotoon, mitä enemmän dataa halutaan tekoälyllä käsitellä sitä enemmän tätä muunnosta tarvitsee tehdä.
Miksi tokenien luonti on sitten niin merkittävää että Jensen puhuu jopa AI tehtaista? Luulen että tässä menee sekaisin embedding ja token Mistralin kuvaaja voi auttaa.
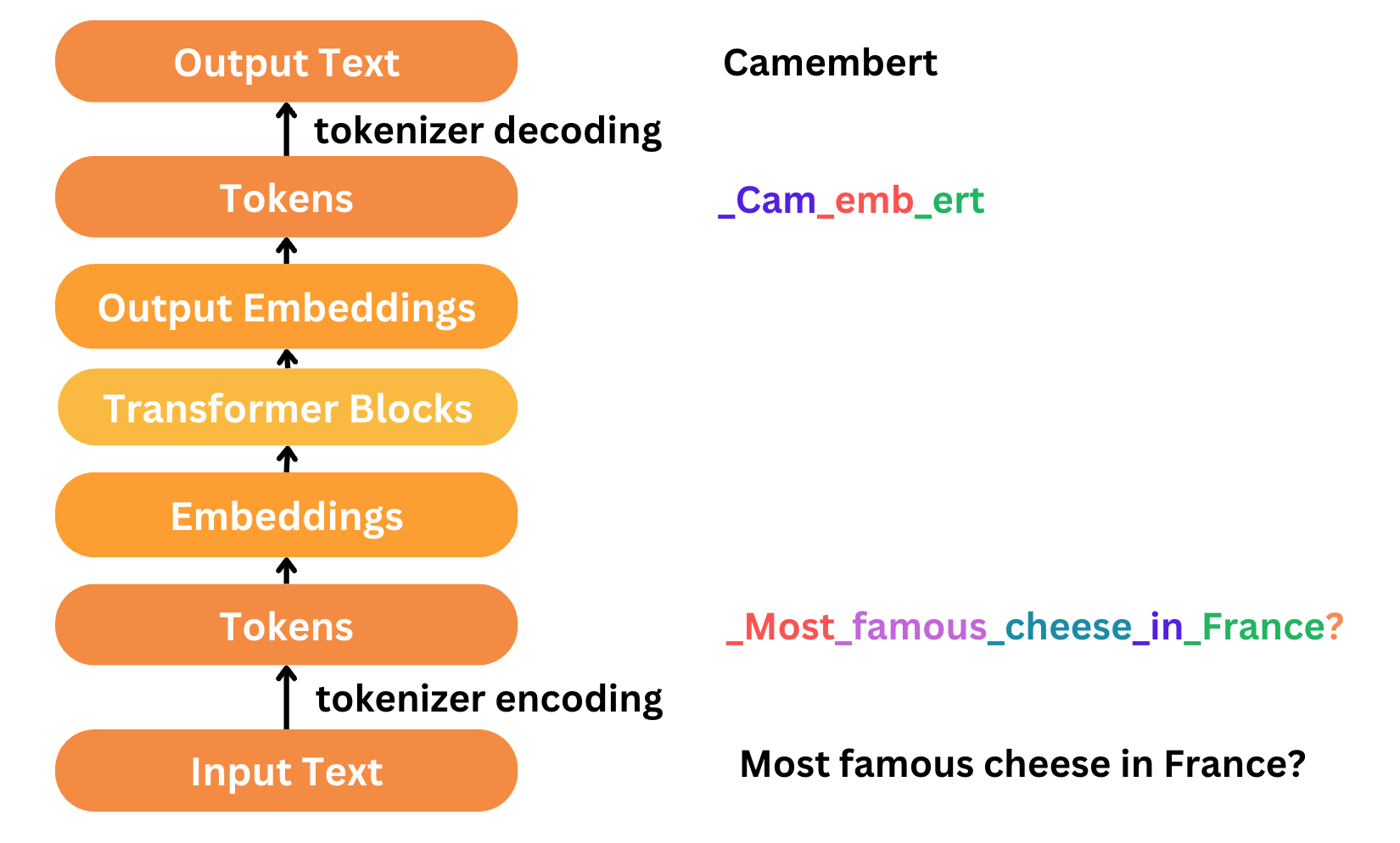
Jotain dataa tulee sisään, se muunnetaan säännölliseen muotoon tokeneiksi, sitten tokenit muunnetaan esikoulutetun mallin läpi embeddingeiksi.
Tokeniksi muuntaminen voi periaatteessa olla halpa toimenpide ja tapahtua jopa käyttäjän laitteella. Mutta embeddingin luonti vaatii mallista riippuen enemmän laskentaa, koska embedding saattaa sisältää tekoälymallin ymmärrystä tokeneiden järjestyksestä ja suhteista toisiinsa.
Kun tekoälymallia muutetaan tarpeeksi paljon, myös embeddingit tarvitsee laskea uudelleen. Ja tästä syntyy se tarve laskea tokeneita ja embeddingejä uudelleen datalle jota halutaan hyödyntää vaikka itse tekoälymalli olisikin jonkun toisen valmiiksi kouluttama.
7 tykkäystä
Tokenit liittynevät NVIDIAn testeissä Transformeriin, vaikka toki eri AI-malleissa puhutaan tokeneista
Edit Tämä minuutin video kertoo hienosti, mikä on token kielimallissa (tai toki token/vector voi käsitellä mitä dataa vain)
Oman käsitykseni mukaan Transfomer käsittää 3 keskeistä kerrosta.

Alin Embedding-kerros muuttaa datan tokeneiksi ja niitä vastaaviksi vektoreiksi. Muunnos tapahtuu omalla AI-mallilla. Vision Transformerissa muistaakseni linear layerillä (patchin pixelit->vector)
Paikkatieto/Position embedding lisätään samassa kerroksessa
Multihead Attention kerros
Self Attention osuudessa vektorit kerrotaan Query, Key ja Value parametrimatriiseilla ja saadaan Query, Key ja Value matriisit.

Queryn ja Keyn tulona syntyy Attention Filter, jossa eri sanojen (tokenien) suhteet toisiinsa muuttuvat opetuksen mukaiseen suuntaan.

Tämä lopuksi kerrotaan Valuella.
Multihead Attentionissa useita Self Attention toimintoja ajetaan rinnakkain. Jokainen säätää vektorin omaa ulottuvuutta/merkitystä.
Eli jokaisen Multihead attention osuuden jälkeen embedding vektorien suhteet toisiinsa siirtyvät oikeaan suuntaan.
Viimeisessä fully-connected/liner layer kerroksessa decorer pohjaisessa kielimallissa on linear layer jossa vektorit litistetään tuloihin ja lähtöihin sanaston kaikki sanat. Tämä kerros antaa todennäköisyyden jokaiselle sanalle seuraavaksi sanaksi

Multimodalia voi tehdä varmaan monella tapaa. Yksi voisi olla käyttää Transformerin Cross Attention osuutta, joka vastaa Self Attention osuutta mutta voi muokata toista dataa toisen datan ehtojen perusteella.
Tähän perustuu vaikka Diffuusion mallien kuvan sisällön ohjaus tekstillä.

Cross Attention toimii kuten Selt Attention, mutta Attention Filter muodostetaan kahdesta datasta. Query ja Key.

Se miksi kiinnosti se, että optimoiko NVIDIA Transformerille piirinsä pohjautuu siihen, että näin Transformerin voittokulku jatkuu.
Alla kuva siitä, miten nykyään tehdään itse ajava auto end2end-arkkitehtuurilla. Teslan uusi ratkaisu lienee konseptitasolla vastaava
Ratkaisu muodostuu kolmesta Transformerista. Myös tuo pohjatuu isoon määrään dataa. Eli pelkät kielimallit eivät jatkossa ole NVIDIAn piirien drivereita

12 tykkäystä
Hyvä lisähavainnollistus. Näissä embeddings, token ja transformer -käsitteissä aletaan olla nykyaikaisen datatieteen ihan kovassa ytimessä eikä näitä ole ihan helppo ymmärtää. Näyttäisi kuitenkin, että @JukkaM tuntee nämä konseptit erinomaisesti ![]() Nyt ymmärsin myös alkuperäisen kysymyksen - pohditaan sitä alempana.
Nyt ymmärsin myös alkuperäisen kysymyksen - pohditaan sitä alempana.
Huangilla on ollut tendenssi puhua “token generationista” hänen viitatessaan yleisesti (generatiivisen) tekoälyn potentiaaliseen hyödykkeellisyyteen. Hän on käyttänyt usein vertausta teolliseen vallankumoukseen, jossa höyrykone luo vedestä energiahyödykettä vastaavasti kuin GPU:t luovat nyt/tulevaisuudessa commodisoituja tokeneita “AI-tehtaissa”.
Tämä johtuu ns. scaling laeista. Nykyisen kaltaisten mallien on havaittu tuottavan yksinkertaisesti parempia tuloksia, kun niitä koulutetaan suuremmalla tieto- (aka token-) määrällä.
Jep - tapoja on monia. Mutta AI-laskennan ja GPU-kysynnän kannalta kaikki nykyiset tavat (kuten vaikka yksinkertainen patching kuva-transformereissa) lisäävät merkittäväsi kapasiteettitarvetta nykytilanteeseen nähden sekä opetuksen että inferencen osalta.
Blackwellissä on tiettyjä ratkaisuja, jotka tekevät siitä tehokkaamman transformer-arkkitehtuurissa vaaditulle laskennalle (etenkin inference-puolen token-luonnin osalta). En ehkä kuitenkaan näe, että isossa kuvassa tämä ainakaan lukitsisi generatiivista AI-paradigmaa transformer-arkkitehtuuriin oikeastaan mitenkään. Esim. Meta (JEPA-arkkitehtuuri) ja sadat tai tuhannet akateemikot pakertavat parhaillaan ihan uudenlaisten AI-tekniikoiden parissa, jotka voivat toimiessaan ratkaista niin kriittisiä LLM:n heikkouksia, että pelkkä laskennallinen tehokkuus ei tule pelastamaan melko alkeellisia transformereita.
Nvidian GPU:t ovat kuitenkin edelleen multipurpose-prosessoreja (vrt. vaikkapa TPU:t tai DPU:t) ja niin kauan kuin rinnakkaisuus tuottaa laskentahyötyjä, näitä tullaan käyttämään myös potentiaalisesti uusiin ja luoviin tarkoituksiin. BW:n pienet transformer-optimoinnit saattavat olla kuitenkin kriittisia vaikkapa MS:lle, jolle pienikin säästö esim. energiankäytössä voi olla merkittävä, kun miljoonat ihmiset tekevät kyselyitä copilotille.
8 tykkäystä
Toki Transformers kehittyy. Trendi tuntuu oleva se, että FeedForward-tyyppisestä ajattelusta siirrytään vektorien käsittelyyn avaruudessa. Vaikka vektorit muodostetaan “normaaleilla” parametrimatriiseilla, rikastavat ne todennäköisyyslaskentaa.
Yann Lecun puhuu Autonomous AI:sta jonka yksi keskeinen elementti on JEPA-arkkitehtuuri.
Esim. I-Jepa muodostuu käytännössä kolmesta ViT:stä (Vision Transformer).
Tässä Self Superviced learning metodissa opetusvaiheessa Target encoderin kuvien ennustaminen tehdään Context kuvan perusteella abstraktissa avaruudessa, jossa kuvien ennustaminen pohjautuu enemmän merkitykseen kuin pixeleihin.

Tuo tietojen merkityksien vertailu avaruudessa voi mahdollistaa enemmän ihmisen kaltaisen päättelyn.
Eli suunta on
- isoja malleja, joita voi tuunata eri tarkoituksiin
- unsupervised learning/self-supervised learning, massiivisilla datamäärillä opetus ilman labelointia. AI-itse päättelee, mitä on tärkeä ymmäärtää. Ihminen ei omalla labeloinnilla sitä päätä
- Transformer tai laajemmin vektorien suhteiden käsittelyyn avaruudessa
Nuo periaatteessa satavat NVIDIAn laariin.
Vaikka itse koodailin ensimmäiset AI-mallit 2016 ja olen odottanut sijoituskohdetta, jäin NVIDIAn kohdalla junasta. En uskonut piirivalmistajan saavan dominanssia
En viitsi enää NVIDIA ketjuun laittaa materiaalia, joka taitaa mennä hieman ohi aiheesta. Tuon tokenin halusin vain selventää
12 tykkäystä
Voihan se olla, että kyytiin ehtii vielä moneen kertaan, jos / kun tämänhetkiseen supersykliin saadaan eka särö ![]() . Nämä fundamentaaliset tensoreiden / vektoreiden laskennan kasvavat kysyntäajurit, joita diagrammeilla tässä hienosti havainnollistit, tuskin ovat kuitenkaan katoamassa enää mihinkään.
. Nämä fundamentaaliset tensoreiden / vektoreiden laskennan kasvavat kysyntäajurit, joita diagrammeilla tässä hienosti havainnollistit, tuskin ovat kuitenkaan katoamassa enää mihinkään.
7 tykkäystä
Hyvän keskustelun sait liikkeelle @JukkaM . Kun NVIDIAsta on kyse, niin ei mikään laskentaan liittyvä mene aiheen ohi. Ytimen ulkopuolellekin menevät pohdinnat ovat nekin arvokkaita. Ja tämä hetki voi olla ihan hyvä pysäkki seuraavan kymmenen vuoden pätkälle. Jensenillä on kova nälkä viedä laskentaa eteenpäin, joten ehkä nyt taas ollaan jonkun uuden tarinan alkulähteillä. Niin kauan kuin Jensen johtaa yritystään aktiivisesti, niin uutta innovaatiota pukkaa. AI:n hyödyt teollisiin toimialoihin on vielä suurelta osin saavuttamatta. Ja sinne nyt halutaan edetä.
4 tykkäystä
Nvidia julkaisi sitten seuraavan sukupolven GPU alustan Rubinin (Vera Rubinin mukaisesti) juuri äsken Computexissa.
Siinä on kilpailijoilla ihmettelemistä, kun Nvidia aloitti vasta H200 shippaukset, Blackwell julkaistiin pari kk sitten ja nyt jo putkesta tulossa seuraavaa sukupolvea. Näkymä on siis tänään julkaistun mukaan:
- 2024 Blackwell
- 2025 Blackwell Ultra
- 2026 Rubin
- 2027 Rubin Ultra
Amazonin kaltaiset seuraavan sukupolven odottelut tehdään kyllä tällä toiminnalla aivan tyhjänpäiväisiksi eikä tässä taida kukaan kilpailija ihan hirveän nopeasti kyetä ottamaan tätä syklinopeutta kiinni.
Computexin keynote-tykitys: https://www.youtube.com/watch?v=pKXDVsWZmUU
2 tykkäystä
Vähän pettymys, reilusti yli puolet sisällöstä oli käytännössä copypastea GTC-presentaatiosta.
Protovehkeen sijaan oli esiteltävänä tuotantoversio Blackwellistä, eli sen shippaukset Datacenter-asiakkaille ovat alkamassa, mutta kovasti oli jo vauhti päällä menossa 2026 Rubin-juttujen kanssa. Onhan se hyvä että on selvä roadmappi ja tavaraa tulee sellaista vauhtia että kilpailijoita varmasti hirvittää, mutta mitään mullistavaa ei juuri ollut esillä. GTC:ssä sentään oli jotain oikeasti uutta.
Kuluttaja- tai Workstation-puolelle ei ollut yhtään mitään. Eli sinne ei uutta rautaa ole tulossa ainakaan kolmeen kuukauteen. Pitävät varmaan GeForce-only esityksen jossain vaiheessa syksyllä.
4 tykkäystä
Oli ehkä odotettavissa - GTC keynotesta oli kuitenkin vain 75 päivää. Tulihan sieltä kuitenkin mm.
- Rubin-julkaisu
- Uudet NIMsit (mm. virtual human)
- Tuotantokäyttöiset Blackwell GPU ja Blackwell DGX (kuten mainitsit)
- +10 muuta uutta pienempää tai isompaa uutta innovaatiota ja yhteistyökuviota
Näyttää ehkä snadisti siltä, että paukut (selvästi ainakin yhtiön itsensä kertomassa tarinassa) on nyt laitettu industrial-skaalan tekemiseen. Sinänsä ymmärrettävää, kun kuluttajapuoli alkaa olemaan pyöristysvirheen suuruinen merkitys numeroissa. Toki install-basen merkitystä korostettiin useammassa paikassa ja olihan siellä screenillä niitä AI-läppäreitä esitelty, mutta selvästi nyt rakennetaan NIMsien yms. kautta laajempaa CUDA lock inniä.
Edit: ilmeisesti teasattiin myös 5000 RTX. Huang esitteli joku GPU-kädessä DXG Blackwelliä ja analyytikkojen mukaan 50-sarjalainen.
2 tykkäystä